Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Дисперсия
|
|
Рассмотрим меру вариации/рассеяния/разброса/изменчивости для метрической шкалы. По эмпирической кривой распределения или гистограмме на рис. 3.2.3 видим, что совокупность студентов неоднородна по продолжительности затрат времени на учебу. С одной стороны, очевидно, что средняя продолжительность учебы как характеристика имеет смысл, поскольку вполне правомерно сравнение средней продолжительности учебы для выделенных нами групп студентов: социологов, политологов, культурологов и т. д. С другой стороны, в ситуации неоднородности такое сравнение содержательно ни о чем не говорит.
Какова может быть мера неоднородности/однородности по продолжительности? Об этом можно судить по степени отклонения продолжительности затрат времени на учебу отдельного студента от средней продолжительности, которая в нашем случае равна 5,7 (в часах). Индивидуальные отклонения (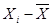 )нельзя просто суммировать, чтобы судить об общем отклонении. Отклонения в одну сторону будут погашаться отклонениями в другую. Чтобы этого не было, индивидуальные отклонения возводятся в квадрат, а затем складываются. Эта сумма делится на число респондентов, и получается характеристика, называемая дисперсией (s2). Это мера вариации значений признака в среднем и вокруг средней арифметической.
)нельзя просто суммировать, чтобы судить об общем отклонении. Отклонения в одну сторону будут погашаться отклонениями в другую. Чтобы этого не было, индивидуальные отклонения возводятся в квадрат, а затем складываются. Эта сумма делится на число респондентов, и получается характеристика, называемая дисперсией (s2). Это мера вариации значений признака в среднем и вокруг средней арифметической.
s2 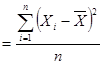
Следует заметить, что при небольшом числе объектов делить нужно не на n, а на (n ¾1). Для социолога это не принципиально, так как он работает обычно с достаточно большим числом объектов.
Корень квадратный из дисперсии называется среднеквадратическим отклонением ( s ¾ сигма). По ней можно сравнивать меры рассеяния разных признаков, одного признака для различных совокупностей. Прямое сравнение дисперсий, среднеквадратических отклонений мало что дает. Рассмотрим пример из нашего исследования. Вычислим среднее арифметическое и среднеквадратическое отклонение продолжительности затрат времени на учебу для нескольких групп студентов. Допустим, что для социологов (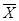 = 6, s = 4), психологов ( = 5,4, s =3,5), политологов ( = 4,5, s = 3,5), историков ( = 6, s = 2). Какие выводы можно сделать по этим данным?
= 6, s = 4), психологов ( = 5,4, s =3,5), политологов ( = 4,5, s = 3,5), историков ( = 6, s = 2). Какие выводы можно сделать по этим данным?
Социологи и историки затрачивают на учебу в среднем одинаковое время, но совокупность социологов менее однородна, потому что среднеквадратическое отклонение больше. Психологи затрачивают на учебу в среднем больше времени, чем политологи, и они более однородны, чем группа политологов. Дисперсия одинакова в этих группах, относительно разных по значению средних. Когда средние и дисперсии в сравниваемых группах различны, на помощь приходит коэффициент вариации.
Коэффициент вариации
Этот коэффициент при наших обозначениях равен 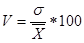
Он представляет собой долю вариации в процентах (%), приходящуюся на единицу средней. В нашем случае соответственно четырем группам: V1 = 66,7% (для социологов), V2 = 64,8% (для психологов), V3 = 77,8% (для политологов), V4 = 33,3% (для историков). Таким образом, группа историков более однородна по продолжительности затрат времени на учебу, чем все остальные группы. Самая неоднородная группа ¾ политологи. Это означает, что среди них оказались и очень много, и очень мало занимающиеся.
Среднее арифметическое и дисперсия интерпретируются всегда вместе. Например, существует так называемое правило «трех сигм», очень важное при работе с эмпирией. Оно означает, что если все значения признака находятся в интервале от -З s до +3 s, то считается, что закон распределения признака нормальный, т. е., как минимум, эмпирическая кривая имеет унимодальный характер (одна мода, один горб). На рис. 3.2.5 изображен идеальный нормальный закон распределения. Запомните его, ибо математический аппарат для анализа нормальных распределений очень богат. Для идеально нормального распределения мода, медиана и среднее арифметическое равны.
Если для анализа распределений использовать «язык» статистического анализа, то сами рассмотренные характеристики, например , являются величинами, имеющими свой собственный закон распределения. Представим себе, что каждый из вас для одного и того же исследования сформировал выборочную совокупность. Пусть у каждого будет самая из самых «хорошая» (репрезентативная) выборка. Если подсчитать, к примеру, средний возраст опрошенных по этим выборкам, то значения будут различны. Среднее этих значений и будет истинным значением среднего возраста в генеральной совокупности. Аналогичны рассуждения и в случае средней продолжительности затрат времени на учебу.
Отклонение средних от «истинной средней» будет носить случайный характер. Оказывается, эту случайность можно оценить. На этом основан подсчет так называемых доверительных интервалов, т. е. интервалов, в которых находится истинное (для генеральной совокупности) значение признака. Но это только для тех величин (характеристик), для которых известен закон распределения. Они называются статистиками. Среднее арифметическое и является статистикой с нормальным законом распределения. Для нее легко определяется доверительный интервал.
Другие меры вариации
Рассмотрим меру вариации, меру отклонения, меру рассеяния значений признака вокруг медианы. Такой мерой является квартильный размах, с которым мы встречались при построении шкалы Л. Терстоуна. Вспомним, что содержательно это интервал, в котором вокруг медианы сосредоточилось 50% экспертов. Это единственная мера вариации для порядковых шкал. На рис. 3.2.4 три пунктирные линии проведены для определения медианы и соответствующего ей квартильного размаха {он равен  }. Без сравнительного контекста трудно сказать, мало это или много. Для социолога познавательная возможность любого математического конструкта, а это пока простейшие формулы на уровне обыденного понимания, определяются только в сравнительном контексте, т. е. при сравнении значений, полученных в разных условиях.
}. Без сравнительного контекста трудно сказать, мало это или много. Для социолога познавательная возможность любого математического конструкта, а это пока простейшие формулы на уровне обыденного понимания, определяются только в сравнительном контексте, т. е. при сравнении значений, полученных в разных условиях.
Перейдем к самым трудным для понимания мерам ¾ мерам качественной вариации, т. е. мерам вариации для признаков, измеренных по номинальным шкалам. Самое главное, что любая такая мера характеризует степень отклонения распределения признака от равномерного, т. е. когда каждой градации признака соответствует одно и то же число объектов. Максимальное значение меры обычно соответствует ситуации равномерного распределения, а минимальное ¾ ситуации, когда все объекты сосредоточены в одной градации.
Как мы знаем, любой номинальный признак сводится к совокупности бинарных, дихотомических, т. е. принимающих значения 0 или 1. В этом случае столбец нашей исходной матрицы данных «объект-признак», соответствующий одному признаку, превращается как бы в несколько столбцов, каждый из которых соответствует отдельному свойству (быть социологом, быть политологом и т. д.). Анализировать мы должны теперь поведение «свойства», а не признака. По всем объектам это совокупность из нулей и единиц.
0000 1 1 1 1 1 1...00 1 1 1
Предположим, что этот ряд получен по свойству ¾ быть в будущем социологом. Если i-й студент ¾ социолог, то ему соответствует хi =1, а если он не социолог, то хi = 0. Оказывается, для такого вида данных имеет смысл среднее арифметическое. Она равна = k/n, где k ¾ число будущих социологов, a n ¾ число всех студентов-гуманитариев.
Почему имеет смысл средняя арифметическая для дихотомической шкалы? Потому что она содержательно интерпретируется. Если = 0, то это означает, что все студенты-гуманитарии в нашей выборке не социологи. Если = l, то все студенты ¾ социологи. Если = 0,5, то половина студентов будущие социологи, а половина ¾ не социологи. Продолжая наши рассуждения, можно сделать вывод и для случаев,_когда 0 < < 0,5 и 0,5 < < 1. Первый из них означает, что в совокупности меньше 50% студентов социологи. Второй ¾ в совокупности больше 50% социологов.
Таким образом, как это ни парадоксально, можно вычислять среднее арифметическое по признаку «пол». Только важно правильно интерпретировать полученный результат, исходя из того, каким образом закодирован этот признак. Разумеется, социологу нет никакого смысла в использовании такого рода средней, отражающей «центральную тенденцию». Он прекрасно работает с относительными частотами в %. Приведенная средняя интересна не для целей первичного анализа, а для анализа с применением сложных математических методов. К примеру, для такой средней можно подсчитать дисперсию. Если для дихотомических признаков имеет смысл использование характеристик метрической шкалы, значит, возможно использование и математических методов, работающих с метрическими данными. Дисперсия в данном случае равна:
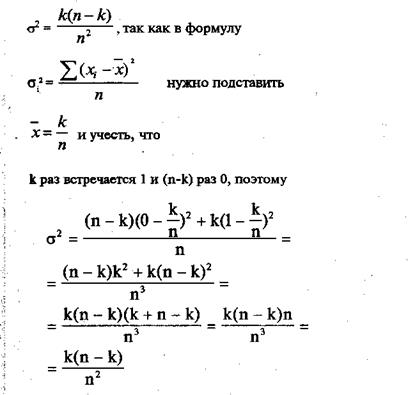
Эта дисперсия и является мерой вариации для бинарного (дихотомического) признака. При этом она равна нулю, если все объекты либо обладают, либо не обладают анализируемым свойством. Что естественно, так как вэтих случаях разброса в данных не наблюдается. Максимальное значение этой дисперсии достигается в случае равномерного распределения (k = n/2), и оно равно 1/4. При этом = 1/2, s= 1/2, V=100%.
Напомню вам одно правило из школьной арифметики. Если есть два целых числа, то среднее геометрическое этих чисел всегда меньше или равно среднему арифметическому. Равенство достигается, когда числа равны.

Этим соотношением и воспользуемся для введения коэффициента качественной вариации. Вначале предположим, что номинальный признак имеет только две градации, причем в первую градацию попало N1 объектов, а во вторую ¾ N2 объектов {число всех объектов равно n = N1 + N2,). И если теперь в соотношение между средней арифметической и средней геометрической подставить
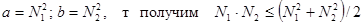
Максимальное значение N, • N2 будет только в случае N1 = N2, и оно будет равно п2 / 4. А это ведь случай равномерного распределения. Коэффициентом качественной вариации и будет отношение реального значения произведения (N, • N2) к максимальному его значению, равному п2 / 4.
Коэффициент равен нулю, если все объекты в одной градации, и единице, если распределение равномерное. Коэффициент легко обобщается на случай, когда число градаций равно k. Представим себе, что из всей совокупности объектов мы образовали всевозможные пары. Вспомним метод парных сравнений Терстоуна и вычисление числа всевозможных пар для сравнения объектов. Здесь ситуация аналогичная. Пары не повторяются, объект сам с собой пару не образует. В случае двух градаций произведение (N1 • N2) есть не что иное, как число пар, различных между собой.
Если градаций три и по ним частоты равны (N1, N2, N3), то число различных пар будет равно (N1×N2 + N1×N3 + N2×N3). Число членов в этой сумме вычисляется как число парных сочетаний из трех элементов по два. Вспоминаем, что это число равно k(k-l)/2, когда число элементов равно k.
Тогда коэффициент вариации вычисляется как отношение:
реального числа различных пар, равного (N1×N2 + N1×N3 + N2×N3);
к максимальному (случай равномерного распределения), равному {(n2 / 9)(3 • 2 / 2)}. В первых круглых скобках ¾ то, во что превращается каждый член суммы, а во вторых ¾ число членов в этой сумме.
В общем случае для k градаций реальное число пар равно
 . Таким образом, формула для вычисления коэффициента качественной вариации приведена по частям, т. е. отдельно числитель (реальное) и отдельно знаменатель (максимальное).
. Таким образом, формула для вычисления коэффициента качественной вариации приведена по частям, т. е. отдельно числитель (реальное) и отдельно знаменатель (максимальное).
Коэффициентом вариации (R) может служить и величина, равная среднему геометрическому из относительных частот в долях (частости) умноженному на число градаций, т. е.
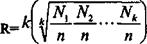
Для вычисления этой величины необходимо избавиться от пустых градаций, иначе она обратится в нуль. R=l при равномерном распределении.
Приведем еще один пример вычисления меры качественной вариации. В качестве такой меры служит энтропия, о которой мы упоминали в контексте «языка» анализа распределений, опирающегося на информационный подход. Энтропия ¾ это основное понятие так называемой теории информации. Распределение признака интерпретируется как некое сообщение, несущее определенный объем информации. Этот объем можно оценить энтропией как мерой «определенности»/«неопределенности». Ее трудно объяснить и трудно понять без знания логарифмов и логарифмических законов распределения. Более того, замечательные свойства этой меры могут быть оценены только при многомерном анализе. Пока вам придется просто этому поверить. Итак, энтропия Н(х) при числе градаций равном k и при обозначении i-й частости (доли) через р; равна:
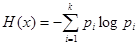
Логарифм может быть взят по любому основанию, ибо нетрудно перейти от одного основания к другому. Напомним, что есть натуральный логарифм (по основанию «е»), десятичный (по основанию «10»), двоичный (по основанию «2»).
Энтропия ¾ положительная величина, несмотря на то, что перед суммой стоит минус. Он погашается другим минусом, появляющимся за счет того, что логарифм берется от правильной дроби (это вам известно из школьной математики). Значение энтропии равно нулю, если все объекты сосредоточены в одной градации (но чтобы это показать, нужны знания о «пределах» ¾ lim). В самом деле, тогда мера неопределенности минимальная. Энтропия равна log k, если распределение равномерное, т. е. в этом случае максимальная неопределенность. Чтобы значение меры не зависело от числа градаций, можно использовать в качестве меры качественной вариации нормированную величину энтропии.
Термин нормировка будет дальше встречаться часто. Это процедура преобразования некоторой величины в необходимый для исследователя вид. Она нужна для того, чтобы какие-то показатели/коэффициенты/ индексы изменялись либо от 0 до 1, либо от -1 до +1. Тогда делается возможным сравнение их значений, полученных при разных условиях, например, для различных совокупностей объектов.
На практике пользуются в сравнительном контексте только одной мерой качественной вариации, ибо каждая мера отражает свое собственное понимание вариации. Потому значения, полученные по разным мерам, не имеет смысла сравнивать.
Date: 2015-09-24; view: 705; Нарушение авторских прав