Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Значение и смысл
|
|
Сложный процесс осмысления теста подчиняется определенным законам. Зная эти законы, мы можем научиться глубоко и полно понимать текст в режиме быстрого чтения. Но что именно нужно понимать в тек- сте? Скорее всего, многим читателям вопрос покажется довольно бессмысленным. Как это, что понимать? Надо понимать все! Однако это не так. Весь текст целиком читать не надо. Вполне достаточно найти и прочитать
его суть, то есть так называемое «золотое ядро». Это именно те 25% текста, что несут в себе нужную инфор- мацию и остаются после исключения избыточности.
Что же представляет собой «золотое ядро»? Для того чтобы разобраться в этом, нам потребуется рас- смотреть смысловые (семантические) принципы, по которым строится текст. Лингвисты считают, что все тексты обладают единством внутренней логической организации, то есть строятся по неким определенным логическим правилам связности изложения. «Золотое ядро» и есть то, что несет в себе основную смысловую нагрузку, остальные 75% – избыточная информация. Сжатие текста в процессе чтения можно условно счи- тать выделением и формированием «золотого ядра». На рис. 9 показана идеограмма последовательности выполнения операции свертывания текста. Любой текст включает в себя некую информацию, которую читатель в нем видит.
Математик и лингвист Ю.А. Шрейдер разработал семантическую теорию информации, согласно которой


 Рис. 9. Уровни сжатия текста
Рис. 9. Уровни сжатия текста
читатель, воспринимая информацию, сравнивает ее с объемом уже накопленных знаний и дает оценку посту- пающим сведениям. Это значит, что если изначально чи- татель не понял текста, далее текст оказывается для него
«пустым», не несущим смысловой нагрузки. Однако впо следствии, получив новые знания и снова обратившись к тексту, читатель становится способным к восприятию значимой текстовой информации. Но что же происходит с информацией далее? Изучая текст, читатель постигает его основной смысл, преобразующийся затем в значение. Для того чтобы вам был понятен механизм происходяще- го далее процесса, попробуем разобраться, что имеется в виду под словами «смысл» и «значение».
Пионером в изучении понятий «смысл» и «значение» был немецкий математик и логик Готлоб Фреге, пред- принявший попытку объяснить суть данных понятий в работе «О смысле и значении». Несмотря на то, что работа Г. Фреге увидела свет еще в 1892 году, до сих пор она продолжает оставаться для исследователей чрезвы- чайно значимой. По Г. Фреге, смысл есть содержание выражения языка, иначе говоря, это мысль, которая прослеживается в словах. Под другим же термином, а именно «значение языкового выражения» Г. Фреге понимает конкретный предмет, словесно закрепленный в сознании человека. Так, слово Луна, по сути, значит небесное тело или естественный спутник Земли.
Отсюда следует, что значение есть некое свойство имени, реализуемое путем многообразного называния вещей, а смыслом, по Г. Фреге, являются множествен- ные способы формального обозначения предметов именами. Сочетания слов типа Николай II; последний русский император; отец русской царевны Анастасии Рома- новой различаются по смыслу, но при этом совершенно одинаковы по значению. В русском и других языках
используются различные способы применения имен, например: шофер – водитель; варежки – рукавицы; конь – жеребец и пр. Приведенные примеры дают раз- ную информацию об одном и том же. Смысл является тем, что передается и принимается в сообщении как важная для людей информация, при этом она должна быть понята принимающим информацию человеком однозначно. Несколько выражений могут иметь одно и тоже значение, но разный смысл, если структура реали- зации текста отлична. Возьмем, к примеру, цифровые выражения «8», «4 + 4» и «10 – 2». Как видите, смысл цифровых выражений различный, а значение каждого из них одинаково.
Теперь рассмотрим рис. 9, на котором изображена идеограмма уровней свертывания текста. Из рисунка следует, что окончанием преобразования фрагмента текста является переход содержания языкового выраже- ния (смысла) в значение. Всегда ли уровни сжатия текста должны «работать» по определенному действенному алгоритму? Безусловно, нет. Приведенная схема выдер- живает строгую четырехуровневость далеко не во всех текстах, однако, в любом случае содержание каждого элемента схемы идет по убывающей. Тексты практи- чески всегда несут в себе определенную информацию и являются осмысленными, но случается, что некоторые из них не содержат значения. Таким образом, данная схема уровней компрессии текста может быть также составлена из меньшего количества компонентов.
Приведем два примера отсутствия значения в тек- сте. Так, понятие, выраженное словосочетанием король Франции, становится пустым, ибо смысл, конечно, име- ет, но его значение в нашем веке отсутствует. И второй пример – научный текст с приведенным ниже кратким анализом.
Рассмотрим некоторый тотальный и, следовательно, уни- кальный экземпляр «А». Установление тождества экземпляра с самим собой можно рассматривать как отображение, приво- дящее образы «А» в соответствие с прообразом «А». Экземпляр
«А» по определению может быть сопоставлен только с самим собой. Поэтому отображение является внутренним и, согласно теореме Стилова, может быть представлено в виде суперпози- ции топологического и последующего аналитического отобра- жения. Совокупность образов «А» составляет точечную систему, элементы которой являются эквивалентными точками…
Лингвист И.Ф. Севбо провела аналитическое иссле- дование текста, цитируемого выше. Краткое содержание анализа свидетельствует об отсутствии значения в дан- ном тексте, несмотря на его формальную связанность и научный стиль изложения.
Возвращаясь к вопросу сжатия текста путем выде- ления «золотого ядра» его содержания, теперь можно с уверенностью сказать, что при чтении текста нужно уметь находить его значение. Как на практике читатель может научиться этому умению?
По исследованиям Н.И. Жинкина, человеческий мозг содержит в себе программу извлечения значения из любого читаемого осмысленного текста, а значит, вы уже обладаете этой способностью. Другие психо- логические исследования в данной области также подтвердили мнение Н.И. Жинкина, показав, что для человеческого мозга при обработке текста является значимым не столько способ формального выражения или смысл текстового материала, сколько его «ядер- ное» значение. Например, в одном из экспериментов группе испытуемых было дано задание нажимать оп- ределенную клавишу всякий раз, когда на мониторе
появлялась надпись «доктор». На остальные появляю- щиеся надписи, включая даже близкие по написанию к исходному слову, например, «диктор», испытуемым было предложено не реагировать нажатием клавиши, сидеть спокойно. С этой частью экспериментального задания большинство испытуемых справились без особых проблем. Однако далее, когда на мониторе безо всякого предупреждения появилось слово «врач», прак- тически вся группа испытуемых ответила на сигнал нажатием клавиши, хотя предложенное слово по напи- санию никак не подходило под словостимул («доктор»). Обратите внимание на рис. 10, на котором показана фильтрующая способность мозга. Изза присутствия в мозге алгоритмического фильтра мозг отсеивает фразу «Зеленые идеи яростно спят». Для второй фразы («Моя твоя не понимай») мозг находит соответствующее выражение. И, наконец, мозг реагирует одинаково на слова «врач» и «доктор», при этом не пропуская слово
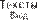

 «диктор». Приведенное описание хода эксперимента является ярким доказательством реагирования мозга на содержание воспринимаемой текстовой информа- ции, а не на ее языковую структуру.
«диктор». Приведенное описание хода эксперимента является ярким доказательством реагирования мозга на содержание воспринимаемой текстовой информа- ции, а не на ее языковую структуру.

Рис. 10. Фильтрующая способность мозга
Содержание дифференциального алгоритма чтения
Патент России № 2113731
При чтении любого текста человек толкует содержа- ние получаемой информации посвоему. В этот момент в мозге происходит перекодирование сообщения на язык мыслей читателя, выделяется основное «ядро» содержа- ния текста. К сожалению, не всегда этот процесс бывает продуктивным. Вместе с тем, текст может быть понят глубоко и полно лишь при осмысленном, сосредоточен- ном чтении. Отсюда следует, что, осваивая быстрое чте- ние, читатель должен сформировать у себя навык произ- вольного использования столь важной программы мозга перекодирования сообщений и извлечения из текста
«ядра».
Эксперименты показывают, что некоторые упраж- нения, основанные на дифференциальном алгоритме чтения, позволяют решить задачу обучения выделению
«ядерного» значения. На рис. 11 приведены три блока этого алгоритма.
Опытные читатели при чтении охватывают с од- ного взгляда много слов сразу, и этого оказывается достаточно, чтобы уяснить суть получаемой информа-
|


|
3 Доминанта – значение
Рис. 11. Три блока дифференциального алгоритма чтения
мысли, прослеживающиеся в тексте, часто не являются соразмерными количеству
слов, охваченных взглядом неопытного читателя, а простираются гораздо дальше, захватывая одно, два и более предложений. Таким образом, мысли, восприни- маемые неопытным читателем, рассекаются на множес- тво маленьких кусочков, а это, естественно, затрудняет понимание и осмысление данного фрагмента текста.
Нам уже известно, что применение интегрального алгоритма чтения значительно способствует поиску нужной информации во всем тексте. Но для каждого предложения или абзаца такую последовательность действий, конечно же, составить нельзя. Что делать? Для того чтобы каждый смысловой отрезок текста не оставался для читателя «пустым», следует применять дифференциальный алгоритм чтения. Алгоритм на- зван дифференциальным потому, что с его помощью возможно разделять каждый самостоятельный кусок текстового материала (любой его смысловой абзац) на отдельные логические элементы: ключевые слова, смысловые ряды и доминанту. При этом обратите внима- ние на то, что печатный абзац книги и смысловой абзац текстового материала могут не совпадать, например, в смысловой абзац может входить несколько печатных абзацев и т.д.
Теперь рассмотрим каждый из отдельных логических элементов, или блоков дифференциального алгоритма чтения отдельно.
1. Ключевые слова
Ключевые слова обозначают признак предмета, состояние или действие и несут основную смысловую нагрузку в тексте. Случается, что смысловой абзац тек- стового материала в целом является вспомогательным и не содержит ключевых слов. Как правило, местоиме- ния не относятся к ключевым словам, однако в случае,
если они замещают уже употребляемое ранее в тексте предметное (ключевое) слово, их также можно условно считать ключевыми. Предлоги, союзы и междометия ключевыми словами не считаются.
2. Смысловые ряды
Смысловые ряды являются соединениями ключевых слов и некоторых вспомогательных дополняющих их слов в логические цепочки. Именно этот блок диффе- ренциального алгоритма есть основа «золотого ядра» всего текста, он помогает при чтении понять суть каж- дого абзаца. При чтении сознание читателя объединяет ключевые слова в смысловые ряды, несущие основную идею автора текста. Таким образом, текст подвергается компрессии и уже в свернутом виде (в виде непрерывных цепочек пар слов) «записывается» в память читателя.
Тем не менее, это только промежуточный этап. Далее вступает в действие третий блок алгоритма.
3. Доминанта
Подвергаясь сжатию, текстовой материал претер- певает не только количественные изменения, но и изменения качественные, вычленяя из составленных в процессе применения первых двух блоков алгоритма сжатых цепочек пар слов единую, главенствующую идею, основной замысел автора – доминанту текста.
Известно, что, пересказывая любой текст, люди, как правило, не передают его слово в слово, а добав- ляют нечто свое, заменяя, как им кажется, ненужные сведения. При чтении мозг человека перекодирует со- общение и трактует его, исходя из собственного опыта и приобретенных ранее знаний. Поэтому в пересказе люди могут изменять первоначальный текст автора, становясь как бы его соавторами. Подобная творческая позиция читателя значительно отличается от так назы-
ваемой «школьной зубрежки» любого текста, так как способствует более глубокому и полному осмыслению прочитанной информации.
Итак, последний блок алгоритма выявляет «ядерное» значение содержания текстового материала. Поэтому обучение чтению с применением блоков дифференци- ального алгоритма способствует усвоению действитель- ного значения читаемого текста, а это, в свою очередь, является основной задачей чтения.
Date: 2015-09-24; view: 527; Нарушение авторских прав