Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Категории языка SQL (DDL, DML, DCL) и их применение (на примерах). Структура запроса с использованием одной или нескольких таблиц (пример)
|
|
Язык SQL. Дословно - язык структурированных запросов. Стандартизированный (вначале 1987, а затем в 1992 году) язык для доступа к базам данных реляционного типа. Язык SQL не является языком программирования, это язык доступа, язык, на котором можно сформулировать, какую информацию необходимо получить из хранящиейся в базе данных.
Язык SQL состоит из команд, которые сгруппированы по функциям. Эти группы команд даже получили названия самостоятель-ных языков: язык определения данных DDL, язык обработки данных DML, язык запросов к данным DQL, язык управления дан-ными DCL. Самой известной частью языка SQL является его подъязык DQL, состоящий по сути из единственной команды SELECT. Команда предназначена для выборки данных из базы данных.
Другой известной группой команд является подъязык DML, состоящий из команд INSERT, UPDATE, DELETE и предназначенных для добвления, обновления и удаления данных из базы данных соответственно. Все базы данных реляционного типа, а они сегодня преобладают на рынке, обязаны обрабатывать SQL команды.
Некоторые системы управления баз данных имеют свой диалект SQL, как правило отличающийся от стандарта незначительно, но учитывать это необходимо. На базе SQL некоторые компании предоставляют полноценные процедурные языки программирования - T-SQL (Microsoft SQL Server), PL/SQL (Oracle).
К числу основных операторов усеченного подмножества SQL относятся следующие:
CREATE ТАВLЕ - создание таблицы;
DROP TABLE - удаление таблицы;
CREATE INDEX - создание индекса;
DROP INDEX - удаление индекса;
ALTER TABLE - изменение структуры таблицы;
SELECT, UPDATE, INSERT, DELETE - выборка, изменение, вставка и удаление записей.
К дополнительным операторам SQL относятся следующие:,
CREATE DATABASE, SHOW/ DATABASE, START DATABASE, STOP DATABASE, DROP DATABASE - создание, просмотр, активизация, закрытие, удаление БД;
CREATE VIEW,,DROP VIEW - создание, удаление выборки (представления);
CREATE SYNONYM - создание синонима;
GRANT, REVOKE - назначение, удаление привилегии для работы с выборками таблицами.
Рассмотрим подробнее важнейший из перечисленных операторов - оператор SELECT.
B упрощенном виде оператор имеет следующий формат:
SELECT [АLL|DISTINCT] <список данных>
FROM <список таблиц>
[WHERE <условие выборки>]
[GROUP BY <имя столбца> [,<имя столбца>]...]
[HAVING <условие поиска>]
[ORDER ВУ <спецификация сортировки>[,<спецификация сортировки>]...]
Оператор SELECT позволяет выполнять выборку и вычисления над данными одной или нескольких таблиц. Результатом выполнения оператора является ответная таблица, которая может иметь (ALL) или не иметь (DISTINCT) повторяющиеся строки.
В списке данных можно задавать имена столбцов и выражения над ними, к примеру арифметические. Если записи отбираются из нескольких таблиц, то используют составные имена <имя таблицы>.<имя столбца>.
Пример. Имеется таблица Goods (товары) с полями: Соdе (код), Name (наименование) и Cost (стоимость). Требуется вывести стоимости и коды товаров, стоимость которых не превышает 500 единиц.
Для решения поставленной задачи можно записать оператор SELECT следующим образом:
SELECT Соdе, Cost
FROM Goods
WHERE Cost <=500
В различных СУБД состав операторов SQL может несколько отличаться от рассмотренного нами.
Основные типы данных SQL –INTEGER – целое число (обычно до 10 значащих цифр и знак); FLOAT – вещественное число; CHAR(n) – символьная строка фиксированной длины из n символов (0 < n < 256); VARCHAR(n) – символьная строка переменной длины, не превышающей n символов (n > 0 и разное в разных СУБД, но не больше 4096); DATE –специальной ко-мандой (по умолчанию hh.mm.ss); MONEY – деньги в формате, определяющем символ денежной единицы ($, руб,...) и его рас-положение (суффикс или префикс), точность дробной части и условие для показа денежного значения.
Таблицы создаются командой CREATE TABLE.
При записи синтаксических конструкций используются следующие обозначения:
– звездочка (*) для обозначения “все”
– квадратные скобки ([]) – означают, что конструкции, заключенные в эти скобки, являются необязательными (т.е. могут быть опущены);
– многоточие (...) – указывает на то, что непосредственно предшествующая ему синтаксическая единица факультативно может повторяться один или более раз;
– точка с запятой (;) – завершающий элемент предложений SQL;
– запятая (,) – используется для разделения элементов списков;
– пробелы () – могут вводиться для повышения наглядности между любыми синтаксическими конструкциями предложений SQL;
– термины таблица, столбец,... – заменяют (с целью сокращения текста синтаксических конструкций) термины имя_таблицы, имя_столбца,..., соответственно.
CREATE TABLE базовая_таблица (столбец тип_данных
[,столбец тип_данных]...);
Предложение для создания индекса обычно следующее:
CREATE INDEX ON (имя_столбца[,]...);
Таблица должна уже быть создана и должна содержать имя столбца. Однажды созданный индекс будет невидим пользователю. SQL самостоятельно решает, когда он необходим чтобы ссылаться на него, и делает это автоматически.
Представления (View) – это таблицы, чье содержание выбирается или получается из других таблиц. Они работают в за-просах и операторах точно так же, как и базовые таблицы, но не содержат никаких собственных данных. Представления подобны окнам, через которые вы просматриваете информацию, фактически хранящуюся в базовой таблице.
Представление создается командой CREATE VIEW. Она состоит из слов CREATE VIEW (создать представление), имени представления, которое нужно создать, слова AS (как) и, далее, запроса. Синтаксис предложения CREATE VIEW имеет вид:
CREATE VIEW имя_представления [(столбец[,столбец]...)] AS подзапрос;
Структура запросов с использованием одной таблицы
Запрос – это команда, которая дается СУБД и которая сообщает ей, чтобы она вывела определенную информацию из таб-лиц. Все запросы на получение практически любых данных в SQL осуществляются с помощью единственного предложения SELECT – предложения языка SQL, Предложение SELECT выглядит следующим образом:
Предикат – предикаты используются для ограничения числа возвращаемых записей:
ALL – возвращают все записи из таблицы. Если инструкция SQL не содержит ни одного предиката, то подразумевается предикат ALL;
FROM – указывает таблицы или запросы, которые содержат поля, перечисленные в инструкции SELECT;
WHERE – строки удовлетворяют перечню условий отбора строк. Кроме операторов сравнения (= | <> | < | <= | > | >=) в WHERE используются условия BETWEEN (между), LIKE (похоже на), IN (принадлежит), IS NULL (не определено):
GROUP BY – группирует по указанному перечню столбцов для того.
HAVING – имеет в результате лишь те группы, которые удовлетворяют указанному перечню условий отбора групп.
ORDER BY – упорядочить по – определяет упорядоченность результатов выполнения оператора.
Структура запросов с использованием нескольких таблиц
Объединения – это связь нескольких таблиц в запросе. Объединение соединяет все строки одной таблицы со строками другой таблицы.
Существует три типа объединений, используемых в предложении FROM: левое внешнее (LEFT JOIN), правое внешнее (RIGHT JOIN) и внутреннее (INNER JOIN).
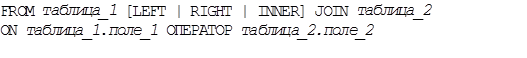
В левом внешнем всем записям в таблице_1 поставлены в соответствие записи из таблицы_2, отвечающие заданным критериям. Записи из таблицы_1 включаются даже тогда, если для них нет соответствующих записей в таблице_2.
Правое внешнее объединение аналогично левому, но в данном случае отображаются все записи таблицы_2 и соответствующие критерию записи таблицы_1.
4. Методы ускорения доступа к данным: адресная функция, построение хеш-функции. Разрешение коллизий. Индексы. Индексно–последовательная организация данных. Рандомизация индекса.
Ускорение доступа к данным достигается применением принципиально иных методов размещения информации, и ее поиска. Для этого создаются массивы вспомогательной информации о хранимых данных.
Эти же методы необходимы при организации доступа к информации по нескольким ключевым атрибутам одновременно.
Доступ к требуемым записям может осуществляться не только путем сравнения искомого значения ключа с ключами записей, извлекаемых из массива по определенному алгоритму (как это было в рассмотренных методах обработки данных), но и в результате вычисления местоположения требуемой записи. Сами записи могут быть упорядочены алгоритмом сортировки либо используется специальная расстановка записей.
Адресная функция
Расстановка записей происходит в соответствии с так называемой адресной функцией (другие общеупотребительные ее названия - "рандомизирующая функция" или"хэш-функция" от hashing – рассеянная память от глагола to hash – крошить рубить и делать из этого месиво).
Идея хеширования состоит в использовании некоторой частичной информации, полученной из ключа. В качестве основы поиска. Вычисляется хеш-адрес F(p) и используется для проведения поиска.
Рассмотрим знаменитый пример «парадокс дня рождения». Который обсуждался математиками в 30-е годы. Например, в компании из 23 человек более всего вероятно совпадение дней рождения у двух человек, чем то что у всех дни рождения окажутся различеиные. Иными словами, если выбрать случайную функции, отображающую 23 ключа в таблицу размером 365, вероятность, что никакие два ключа не будут отображены в одно и тоже место таблицы, составляет 0,4927, т.е. менее половины. Этот пример предупреждает нас, что вероятно найдутся различныеключи Pi ¹ Pj при которых F(pi)=F(pj). Такое событие именуется коллизией. Для разрешения коллизий разработаны некоторые подходы.
Поэтому для использования хеширования программист должен решить две практических задачи – выбрать хеш-функцию f(p) и способ разрешения коллизий.
Адресной функцией или хеш функциенй называется зависимость
i= f(p),
где i— номер (адрес) записи;
р - значение ключевого атрибута в записи.
К функции f предъявляются следующие требования:
• она должна быть задана аналитически и вычисляться достаточно быстро;
•ключевые атрибуты, подчиняющиеся произвольному распределению, функция должна переработать в равномерно распределенные номера записей; это условие обычно соблюдается приближенно;
• число записей-синонимов или коллизий должно составлять 10-20% от общего числа записей.
Построение хеш-функции.
Предположим, что хеш-функция имеет не более М различных значений, причем для всех ключей Р
0 <=F(p) < М. (1)
Известно достаточно много адресных функций, хорошо соответствующих этим требованиям. Простейшая адресная функция имеет вид:
i=р-а, где а - константа.
Пусть известны минимальное значение ключевого атрибута в массиве р' и максимальное значение р ". Тогда а = р' - 1. Необходимый участок памяти для данных оценивается в р" - р' +1 запись. Записи-синонимы связываются в цепочки с помощью адресов связи, они занимают дополнительную (резервную) память.
Пример размещения записей с ключами 13,11,14,11,15,18,14,16 согласно адресной функции i = р - а показан на рис. 6.1
|  Æ Æ
| Æ 
| ÆÆ | Æ | ÆÆ |
Рис. 6.1. Организация записей в соответствии с адресной функцией i = р - а
При доступе к записи с ключом q вычисляется i= f(q) и производится обращение к
i-й записи. При необходимости с помощью адресов связи извлекаются все синонимы.
Недостаток адресной функции вида i = р - а - большой объем неиспользуемой памяти, если р "- р 'много больше, чем количество записей М.
Многочисленные тесты показали хорошую работу двух основных типов хеш функций, один из которых основан на делении, а другой — на умножении.
Метод деления весьма прост; мы просто используем остаток от деления на М
i= ОСТ (р/m). (2)
Здесь m - целое число; ОСТ - остаток от деления р на m.
Значение m принимается равным простому числу, которое непосредственно больше либо непосредственно меньше числа записей М.
Рассмотрим работу данной функции на примере. Как уже говорилось, значение m принимается равным простому числу.
Выделяются 2 зоны памяти - основная и резервная. Основная зона содержит m записей. Резервная зона предназначена для размещения записей синонимов.
При формировании данных согласно адресной функции сначала производится заполнение основной зоны. Если при этом позиция основной зоны, полученная при вычислении, уже занята, то текущая запись помещается в резервную зону и адресуется из этой позиции основной зоны. В дальнейшем при такой ситуации наращивается цепочка записей в резервной зоне.
Например, для массива ключей со значениями 17, 9, 4, 14, 25, 21, 20, 11 необходимо выбрать m=7, поскольку М=8 (возможно также m=19). Содержимое основной и резервной зон иллюстрирует рисунок. Резервная зона заполняется последовательно. При поиске значения, например р=11, вычисляется i = ОСТ(11/7)=4, и далее последовательно сравниваются 4 и 11, 25 и 11 и т.д. В рассматриваемом примере число записей-синонимов составляет 3/8.
Мы уже говорили, что некоторые хеш-адреса могут быть одинаковыми для различных ключей. Вероятно, самый очевидный путь решения этой проблемы — поддержка М связных списков, по одному для каждого возможного значения хеш-кода.
Разрешение коллизий методом "цепочек".
Мы уже говорили, что некоторые хеш-адреса могут быть одинаковыми для различных ключей. Вероятно, самый очевидный путь решения этой проблемы — поддержка М связных списков, по одному для каждого возможного значения хеш-кода. Поле LINK должно быть включенс каждую запись; кроме того, следует иметь М головных узлов списков, перенумерованных, скажем, от 1 до М. После хеширования ключа мы просто выполня последовательный поиск в списке номер f(p) + 1
На рис. 38 показана простая схема с цепочками при М = 9 для последовательности из ключей
К = EN, TO, TRE, FIRE, FEM, SEKS, SYV (11)
(представляющих числа от 1 до 7 на норвежском языке), имеющих хеш-коды
f(p)+1=3, 1. 4, 1, 5, 9, 2 (12)
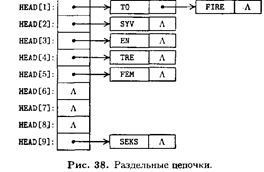 соответственно. В первом списке содержится два элемента, три списка пусты.
соответственно. В первом списке содержится два элемента, три списка пусты.
В связи с тем, что цепочки коротки, рассматриваемый здесь метод являет весьма быстродействующим. Если 365 человек соберутся вместе в одной комнате, вероятно, окажется много пар, имеющих один и тот же день рождения, однако среднее количество людей с данным днем рождения равно только 1! В общ случае, если имеется N ключей и М списков, средний размер списка будет равN/M; значит, хеширование приводит к уменьшению среднего количества обращений по сравнению с последовательным поиском, примерно в М раз.
Индексы
Для ускорения поиска записей в массиве используется дополнительная информация, организованная в виде массива индексов.
Индексом называется набор ключей и адресов записей, которые выбираются из основного массива по определенному закону.
Индексно-последовательный массив представляет собой последовательный массив, отсортированный по значениям ключевого атрибута, к которому создается дополнительный массив индексов.
В индекс выносится информация о записях, номера которых образуют арифметическую прогрессию с шагом d. Поиск значения q в индексно-последовательном массиве происходит в две стадии:
• в массиве индексов
• среди записей основного массива, расположенных между двумя соседними индексами, найденными на первой стадии.
Применение индексов приводит к ускорению доступа, если основной массив располагается на внешнем запоминающем устройстве, а массив индекса может быть полностью размещен в оперативной памяти ЭВМ.
5. Системы управления базами данных: назначение, содержание, функции. Примеры СУБД.
База данных – это информационная модель, позволяющая упорядоченно хранить данные о группе объектов, обладающих одинаковым набором свойств.
Программное обеспечение, предназначенное для работы с базами данных, называется система управления базами данных (СУБД). СУБД используются для упорядоченного хранения и обработки больших объемов информации.
СУБД организует хранение информации таким образом, чтобы ее было удобно:
- просматривать,
- пополнять,
- изменять,
- искать нужные сведения,
- делать любые выборки,
- осуществлять сортировку в любом порядке.
· Систе́ма управле́ния ба́зами да́нных (СУБД) — совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных.
· Основные функции СУБД
· управление данными во внешней памяти (на дисках);
· управление данными в оперативной памяти с использованием дискового кэша;
· журнализация изменений, резервное копирование и восстановление базы данных после сбоев;
· поддержка языков БД (язык определения данных, язык манипулирования данными).
· Обычно современная СУБД содержит следующие компоненты:
· ядро, которое отвечает за управление данными во внешней и оперативной памяти, и журнализацию,
· процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода,
· подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД
· а также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
Date: 2015-07-27; view: 4905; Нарушение авторских прав