Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Языковая форма представления данных
|
|
Наиболее распространенной, традиционной является языковая форма представления данных. Языковые системы, используемые для представления данных подразделяют на:
- естественные, например, естественные языки человеческого общения (русский, английский и др.);
- формальные (искусственные), например, математический язык, алгоритмический язык, языки программирования и др.
Языковая система − это совокупность знаков (алфавит), а также правил и соглашений, используемых для общения, отображения и передачи данных.

Алфавит − это набор знаков, используемых для отображения данных. Основные свойства алфавита:
- алфавит должен быть фиксированным и конечным;
- знаки алфавита могут иметь любую природу;
- знаки алфавита должны быть попарно различны;
- знаки алфавита не интерпретируются, т.е. не объявляется их смысл.
Примерами алфавитов могут служить: алфавиты естественных языков; цифровые алфавиты; азбука Брайля (для слепых и слабовидящих людей); знаки зодиака; знаки планет; ноты; международный семафорный и флажковый коды; и др.
Языковые системы могут включать в себя знаки разных алфавитов, например в химии используются латинские буквы, спецсимволы и цифровые знаки.
Основные правила и соглашения, принятые в языковых системах:
- Правила интерпретации знаков алфавита (алфавитов), т.е. объявления их смысла:

Однозначного соответствия «знак − символ», принятого во всех языковых системах, не существует. Знаки могут использоваться в разных языковых системах с разным смысловым значением и наоборот.
Примеры:
· ♂ и ♀ − в биологии означают мужскую и женскую особь; в астрономии означают планеты Марс и Венера.
· I, V, X, C… − в латинском языке − буквы; в римской системе счисления − цифры.
· операция умножения обозначается разными знаками: в математике − × или ·, в языках программирования − *.
2. Правила построения из символов более сложных конструкций языковых систем − слов, словосочетаний и предложений. Слова и словосочетания конструируются в соответствии с грамматическими правилами, предложения − в соответствии с синтаксическими правилами. В естественных языковых системах эти правила не очень строгие.
Примеры:
· Многие слова в русском языке склоняются и спрягаются: вопрос − именительный падеж, ед. число; (о) вопросе − предложный падеж, ед. число; вопросы − именительный падеж, множ. число; вопросам − дательный падеж, множ. число.
· Строгих правил относительно порядка слов в русских предложениях нет, поэтому из одинаковых слов можно построить несколько правильных предложений: Я учусь в вузе. В вузе я учусь. Я в вузе учусь.
В формальных языковых системах правила очень строгие, не допускают никаких исключений.
Примеры:
· Правило записи вещественного числа в математике: сначала записывается целая часть числа, затем ставится разделитель − запятая, затем записывается дробная часть числа.
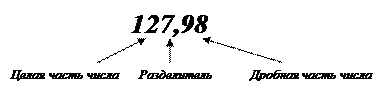
· В языке программирования Basic зарезервированные командные слова (REM, PRINT, INPUT, DIM, IF, THEN, ELSE, FOR, NEXT и др.) не склоняются и не спрягаются; правила записи операторов очень строгие.
PRINT <список вывода> Правильный оператор
<список вывода> PRINT Неправильный оператор
3. Правила выявления смыслового значения конструкций языковых систем − семантические правила. В естественных языках одинаковые конструкции могут быть неоднозначными и наоборот, разные конструкции могут иметь одинаковое значение.
Примеры:
· В русском языке, как и в других языках, широко используются слова-синонимы (разные по написанию, но одинаковые или близкие по значению), слова-омонимы (одинаковые по написанию, но разные по значению). Так слово «процесс», в значении «движение», имеет следующие синонимы: «течение», «ход», «общее направление». С другой стороны, слово «процесс» − это омоним, т.к. имеет следующие значения: «движение», «дело», «тяжба», «разбирательство», «развивающаяся болезнь».
· Разные по конструкции предложения: Я учусь в вузе. В вузе я учусь. Я в вузе учусь. − имеют одинаковое смысловое значение.
· Косой шел с косой. Сколько смысловых значений может иметь это предложение?
В формальных языковых системах семантические правила жестко связаны с грамматическими и синтаксическими правилами: смысловое значение конструкции однозначно определяется ее формой, т.е. написанием.
Пример:
· INPUT a,b Данный оператор языка Basic имеет единственное значение: ввести с клавиатуры значения переменных a и b.
КОДИРОВАНИЕ ДАННЫХ
Кодирование данных − это переход от исходного представления данных к более удобному представлению в каком-либо конкретном случае.
Кодирование данных осуществляют с целью:
· повышения эргономичности, достоверности и защищенности информации;
· повышения экономичности информационных процессов за счет уменьшения объемов обрабатываемых данных, увеличения скорости обработки и передачи данных;
· удобства технической реализации информационных процессов.
Указанные цели могут противоречить друг другу.
Примеры:
- Денежные суммы в бухгалтерских документах записывают цифрами и прописью: 500 руб. 48 коп. и Пятьсот руб. 48 коп. Такая запись повышает достоверность информации (ошибка в цифровой записи изменит сумму, а в словесной − нет), однако увеличивает объем данных.
- Различные сокращения и аббревиатуры, используемые в записях, уменьшают объем данных, увеличивают скорость записи, однако снижают эргономичность информации.
- Шифрование данных повышает защищенность информации, однако снижает экономичность информационных процессов.
Т.к. на разных этапах информационного процесса меняется приоритет целей, происходит постоянное кодирование и декодирование данных. Декодирование − возврат к исходному представлению данных.
Обобщенная схема процесса кодирования:

Сущность процесса кодирования − каждому знаку исходного алфавита ставится в соответствие (единственное и однозначное) кодовая комбинация из знаков кодирующего алфавита.
Кодовая комбинация − это конструкция из знаков кодирующего алфавита, соответствующая одному знаку исходного алфавита. Совокупность кодовых комбинаций, используемых для кодирования всех знаков исходного алфавита, называется кодом.
Основной характеристикой кода является его длина (разрядность) − длина кодовых комбинаций, входящих в код. Различают:
- коды переменной длины (неравномерные);
- коды постоянной длины (равномерные).
Длина кодовых комбинаций в неравномерных кодах различна. Как правило, ее подбирают с учетом частоты использования знака исходного алфавита − чем чаще используется знак, тем короче соответствующая ему кодовая комбинация. Примером неравномерного кода может служить азбука Морзе. Ее кодирующий алфавит включает два знака: точку (·) и тире (−). Часто используемой в русском языке букве «е» в азбуке Морзе соответствует комбинация из одной точки (·), реже используемой букве «ш» − комбинация из четырех тире (− − − −).
В равномерных кодах длина всех кодовых комбинаций одинакова (постоянна). Это не совсем экономично, однако упрощает техническую реализацию информационных процессов. Длина кодовых комбинаций в равномерных кодах зависит от мощности исходного и кодирующего алфавитов. Она должна быть минимальной, но достаточной, чтобы обеспечить неповторимость всех кодовых комбинаций.
Пусть N − мощность исходного алфавита, m − мощность кодирующего алфавита, тогда оптимальная длина кода k может быть рассчитана по следующей формуле: 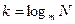 .
.
С помощью средств вычислительной техники обрабатываются различные типы данных: символьные (текстовые), графические, числовые, звуковые данные и их комбинации. С целью унификации формы представления данных различных типов была принята универсальная система цифрового двоичного кодирования. Кодирующий алфавит содержит два цифровых знака 0 и 1. Такая система кодирования данных имеет ряд достоинств:
- обеспечивает простоту и надежность технической реализации информационных процессов: есть сигнал электрического тока − 1, нет − 0; есть магнитное поле − 1нет − 0; есть отраженный световой сигнал − 1, нет − 0;
- предполагает использование двоичной системы счисления при обработке данных, которая отличается простотой арифметических и логических операций;
- дает удобный инструмент для измерения количества информации (данных), независимый от содержательной сущности данных.
Двоичные коды, используемые в вычислительной технике, являются равномерными. Длина кодов зависит от мощности исходного алфавита, подлежащего кодированию (N): 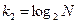 .
.
СИСТЕМЫ СЧИСЛЕНИЯ.
Date: 2016-11-17; view: 684; Нарушение авторских прав