Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Примеры формулировок задач при использовании методов OLAP и Data Mining
|
|
| OLAP | Data Mining |
| Каковы средние показатели травматизма для курящих и некурящих? | Встречаются ли точные шаблоны в описаниях людей, подверженных повышенному травматизму? |
| Каковы средние размеры телефонных счетов существующих клиентов в сравнении со счетами бывших клиентов отказавшихся от услуг телефонной компании)? | Имеются ли характерные портреты клиентов, которые, по всей вероятности, собираются отказаться от услуг телефонной компании? |
| Какова средняя величина ежедневных покупок по украденной и не украденной кредитной карточке? | Существуют ли стереотипные схемы покупок для случаев мошенничества с кредитными карточками? |
Важное положение Data Mining – нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные регулярности в данных, составляющие так называемые скрытые знания. К обществу пришло понимание, что «сырые» данные (raw data) содержат глубинный пласт знаний, при грамотной раскопке которого могут быть обнаружены настоящие знания (рис. 51).
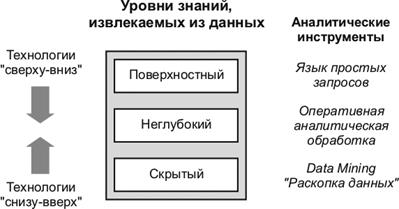
Рис. 51. Уровни знаний, извлекаемых из данных
Data Mining является мультидисциплинарной областью, возникшей и развивающейся на базе достижений прикладной статистики, распознавания образов, методов искусственного интеллекта, теории баз данных и др. Отсюда обилие методов и алгоритмов, реализованных в различных действующих системах Data Mining (рис. 52).
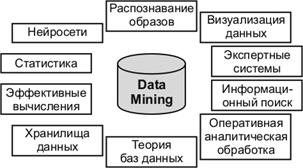
Рис. 52. Методы и теории, являющиеся основой Data Mining
Многие из таких систем интегрируют в себе сразу несколько подходов. Тем не менее, как правило, в каждой системе имеется какая-то ключевая компонента, на которую делается главная ставка. Ниже приводится классификация указанных ключевых компонент.
Предметно-ориентированные аналитические системы. Наиболее популярный подкласс таких систем, который получил распространение в области исследования финансовых рынков, носит название «технический анализ». Эти системы используют несложный статистический аппарат и максимально учитывают сложившуюся в предметной области специфику.
Статистические пакеты. Основное внимание в данных пакетах уделяется классическим методикам статистического анализа – корреляционному, регрессионному, факторному анализу. В качестве примеров наиболее мощных пакетов можно назвать SAS (компания SAS Institute), SPSS (SSPS), STATGRA-PICS (Manugistics), STATISTICA и др.
Нейронные сети. Примерами нейросетевых систем являются системы BrainMaker (CSS), NeuroShell (Ward Systems Group), OWL (HyperLogic) и др.
Система рассуждений на основе аналогичных случаев. Идея такой системы (их еще называют Case Based Reasoning (CBR)) заключается в том, чтобы сделать прогноз на будущее или выбрать правильное решение, находя аналогичные ситуации в прошлом. Примеры систем, использующих CBR, – KATE tools (Acknosoft, Франция), Pattern Recognition Workbench (Unica, США).
Деревья решений. Это наиболее популярный подход к решению задач Data Mining, основанный на создании иерархической структуры классифицирующих правил типа «Если …., то…». Самые известные в этом классе систем – See5/C5.0 (RuleQuest, Австралия, http://www.rulequest.com/), SIPINA (University of Lion, Франция) и др.
Эволюционное программирование. В таких системах гипотеза о виде зависимости целевой переменной от других переменных выстраивается в виде программ, из которых выбирается та, которая удовлетворительно описывает искомую зависимость, затем выполняется ее корректировка на основе дочерних программ, повышающих точность.
Date: 2015-09-23; view: 1416; Нарушение авторских прав