Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Архитектура OLAP-систем
|
|
Остановимся на способах реализации OLAP-систем подробнее. OLAP- система включает в себя два основных компонента:
– OLAP-сервер − обеспечивает хранение данных, выполнение над ними операций и формирование многомерной модели данных. В настоящее время OLAP-серверы объединяют с ХД или ВД;
– OLAP-клиент − представляет пользователю интерфейс к многомерной модели данных, обеспечивая возможность выполнения анализа.
Многомерный OLAP (MOLAP)
При реализации MOLAP-системыиспользуются специализированные СУБД, основанных на многомерном представлении данных. Данные организованы в виде упорядоченных многомерных массивов: гиперкубов (все хранимые в БД ячейки должны иметь одинаковую мерность, т. е. находиться в максимально полном базисе измерений) или поликубов (каждая переменная хранится с собственным набором измерений, и все связанные с этим сложности обработки перекладываются на внутренние механизмы системы). Использование многомерных БД в OLAP-системах имеет следующие достоинства:
1. Поиск и выборка данных осуществляются значительно быстрее, чем при многомерном взгляде на реляционную базу данных, так как многомерная база данных денормализована, содержит заранее агрегированные показатели и обеспечивает оптимизированный доступ к запрашиваемым ячейкам.
2. Легкое включение в информационную модель разнообразных встроенных функций, тогда как объективно существующие ограничения языка SQL делают выполнение этих задач на основе реляционных СУБД достаточно сложным, а иногда и невозможным.
Следует заметить, что использование многомерных СУБД оправдано в случаях, когда:
1) объем исходных данных для анализа не слишком велик (не более нескольких гигабайт), т. е. уровень агрегации данных достаточно высок;
2) набор информационных измерений стабилен (поскольку любое изменение в их структуре почти всегда требует полной перестройки гиперкуба);
3) время ответа системы на нерегламентированные запросы является наиболее критичным параметром;
4) требуется широкое использование сложных встроенных функций для выполнения кроссмерных вычислений над ячейками гиперкуба, в том числе возможность написания пользовательских функций.
Реляционный OLAP (ROLAP)
ROLAP-системы реляционных БД обеспечивают более высокий уровень защиты данных и хорошие возможности разграничения прав доступа. При этом они имеют существенный недостаток − меньшую, по сравнению с MOLAP-системами, производительность. Для устранения этого недостатка реляционные системы требуют тщательной проработки схемы базы данных и настройки индексов, т. е. больших усилий со стороны администраторов БД. В настоящее время распространены две основные схемы реализации многомерного представления данных с помощью реляционных таблиц: схема «звезда» и схема «снежинка».
Идея схемы «звезда» (star schema) заключается в том, что имеются таблицы для каждого измерения, а все факты помещаются в одну таблицу, индексируемую множественным ключом, составленным из ключей отдельных измерений (рис. 46). Каждый луч схемы «звезда» задает направление консолидации данных по соответствующему измерению.
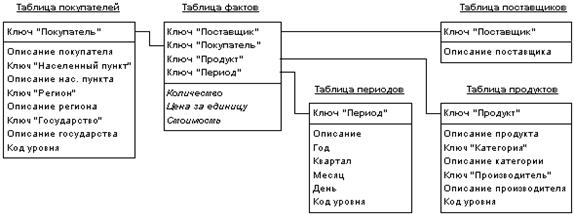
Рис. 46. Пример схемы «звезда»
В сложных задачах с многоуровневыми измерениями имеет смысл обратиться к расширениям схемы «звезда» − схеме «созвездия» (fact constellation schema) и схеме «снежинки» (snowflake schema). В этих случаях отдельные таблицы фактов создаются для возможных сочетаний уровней обобщения различных измерений (рис. 47). Это позволяет добиться лучшей производительности, но часто приводит к избыточности данных и к значительным усложнениям в структуре базы данных, в которой оказывается огромное количество таблиц фактов.

Рис. 47. Пример схемы «снежинка» (фрагмент для одного измерения)
Увеличение числа таблиц фактов в БД может проистекать не только из множественности уровней различных измерений, но и из того обстоятельства, что в общем случае факты имеют разные множества измерений. При абстрагировании от отдельных измерений пользователь должен получать проекцию максимально полного гиперкуба, причем далеко не всегда значения показателей в ней должны являться результатом элементарного суммирования. Таким образом, при большом числе независимых измерений необходимо поддерживать множество таблиц фактов, соответствующих каждому возможному сочетанию выбранных в запросе измерений, что также приводит к неэкономному использованию внешней памяти, увеличению времени загрузки данных в БД схемы «звезда» из внешних источников и сложностям администрирования. Частично решают эту проблему расширения языка SQL (операторы GROUP BY CUBE, GROUP BY ROLLUP и GROUP BY GROUPING SETS). Кроме того, некоторые авторы предлагают механизм поиска компромисса между избыточностью и быстродействием, рекомендуя создавать таблицы фактов не для всех возможных сочетаний измерений, а только для тех, значения ячеек которых не могут быть получены с помощью последующей агрегации более полных таблиц фактов (рис. 48).
В любом случае, если многомерная модель реализуется в виде реляционной базы данных, следует создавать длинные и «узкие» таблицы фактов и сравнительно небольшие и «широкие» таблицы измерений. Таблицы фактов содержат численные значения ячеек гиперкуба, а остальные таблицы определяют содержащий их многомерный базис измерений. Часть информации можно получать с помощью динамической агрегации данных, распределенных по незвездообразным нормализованным структурам, хотя включающие агрегацию запросы при высоконормализованной структуре БД могут выполняться довольно медленно.
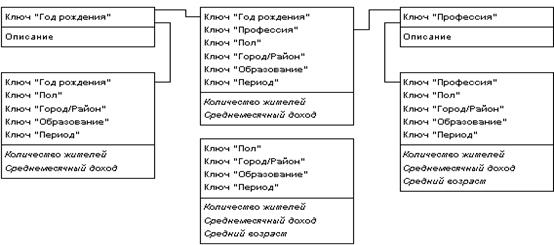
Рис. 48. Таблицы фактов для разных сочетаний измерений в запросе
Ориентация на представление многомерной информации с помощью звездообразных реляционных моделей позволяет избавиться от проблемы оптимизации хранения разреженных матриц, остро стоящей перед многомерными СУБД. Хотя для хранения каждой ячейки используется целая запись, которая помимо самих значений включает вторичные ключи − ссылки на таблицы измерений, несуществующие значения просто не включаются в таблицу фактов.
Date: 2015-09-23; view: 3786; Нарушение авторских прав