Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Экспериментальным данным
|
|
1. Регрессионный анализ:
Результат оценки соответствия модели экспериментальными данными дает ответ на вопрос, является ли модель адекватной? Для решения этой задачи предусматривается анализ двух статистических гипотез.
1) значимо ли отличаются параметры модели (коэффициенты) от нуля. Этим проверяется степень влияния учитываемых переменных Vm, m=1,…,M на выходную переменную y. При этом предполагается, что если коэффициент am значимо отличаются от нуля, то фактор Vm значимо влияет на y. Оценка этой гипотезы осуществляется с помощью доверительных интервалов, которые рассчитываются на базе t-критерия Стьюдента. При этом в математической статистике под доверительным интервалом понимают такой интервал значений оценок любой статистической характеристики, полученной расчетным путем, который с заданной доверительной вероятностью покрывает истинное значение этой характеристики.
Величина полученного таким образом доверительного интервала характеризует меру неопределенности этой характеристики при проверке статистических гипотез. Чем больше доверительный интервал, тем больше эта неопределенность.
Например, если мы находим значения коэффициентов a0, a1 для выражения:
y = a0 + a1v1, (71)
то доверительные интервалы для этих коэффициентов будут соответственно равны: a 0 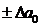 ;
; 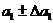 , при этом
, при этом
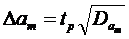 , m=1,…,U (72)
, m=1,…,U (72)
где tp – рассчитанное значение критерия Стьюдента, определенное по специальным по таблицам;
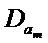 – дисперсия оценки am.
– дисперсия оценки am.
Здесь предполагается, что оценка коэффициента am является случайной величиной и подчинена закону t-распределения, которое называется законом Стьюдента.
Для оценивания коэффициента дисперсии а0, используются следующие формулы:
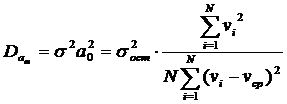 ; (73)
; (73)
Для оценивания доверительного интервала коэффициента a1 используют:
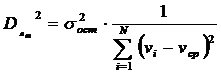 ; (74)
; (74)
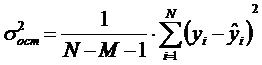 ; (75)
; (75)
где N – число опытов;
M – число учитываемых входных факторов;
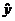 - расчетное значение у с использованием найденной модели.
- расчетное значение у с использованием найденной модели.
Расчетное значение критерия Стьюдента определяется по t-распределению в зависимости от величины доверительной вероятности и числа (N – M – 1). Его величину можно определить по таблицам. Величина доверительной вероятности задается исследование в большом диапазоне 0,9-0,99.
Если выполняется условие | am| > | 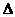 am|, то это означает, что ноль внутрь доверительного интервала не попадает и соответственно фактор vm значимо влияет на y.
am|, то это означает, что ноль внутрь доверительного интервала не попадает и соответственно фактор vm значимо влияет на y.
Если выполняется условие |am| 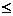 | am|, то это означает, что действительное значение am может быть равно нулю. Для этого могут быть две причины:
| am|, то это означает, что действительное значение am может быть равно нулю. Для этого могут быть две причины:
1) аргумент vm не влияет на y;
2) аргумент vm влияет на y, но эксперимент проведен некорректно, то есть был выбран малый диапазон изменения vm. Поэтому, прежде чем отбраковывать фактор vm, необходимо увеличить величину интервала изменения этого фактора, и повторить эксперимент. Если повторно получается справедливым условие |am| | am|, то фактор vm можно исключить из уравнения.
Таким образом, с помощью оценки значимости коэффициентов проверяется, действительно ли необходимо учитывать все те M переменных, которые были включены в модель на этапе выбора её структуры.
Поскольку с помощью регрессионного анализа отображаются существующие в объекте-оригинале причинно-следственные связи, то в случае одномерной зависимости коэффициент передачи будет близок к действительному. При многомерной регрессии, когда М > 1 оценить близость полученных оценок коэффициента к действительному практически невозможно. В этом случае необходимо тщательно проверить, например, с помощью коэффициента корреляции, наличие или отсутствие статистической взаимосвязи между учитываемыми факторами V m, где i≠j. Лишь убедившись в отсутствии этих связей, можно предполагать, что полученные оценки являются несмещенными.
2. Проверка адекватности модели с помощью F-критерия Фишера.
Fp=  ;
;  . (76)
. (76)
Возникает вопрос: почему при помощи критерия Фишера, можно проверить адекватность модели.
Фишер предложил критерий, как отношение большой дисперсии к меньшей: т.е. дисперсия числителя больше дисперсии знаменателя. Он проверил гипотезу: выборки данных, по которой определяются дисперсии 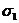 2 и
2 и 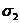 2 принадлежат одной и той же генеральной совокупности, а их различие определяется лишь малостью данных. В нашем случае для проверки адекватности модели рассчитывается критерий Фишера, остаточной дисперсии к дисперсии опыта. Где останочная дисперсия:
2 принадлежат одной и той же генеральной совокупности, а их различие определяется лишь малостью данных. В нашем случае для проверки адекватности модели рассчитывается критерий Фишера, остаточной дисперсии к дисперсии опыта. Где останочная дисперсия:
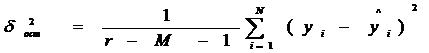
Дисперсия опыта есть характер разброса экспериментальных данных относительно модели расчетной кривой. Т.о. она отражает эффекты влияния не учтенных моделью факторов.
Строго говоря дисперсия опыта может рассчитываться только на основе данных активного эксперимента.
Если Fp Fтабл , то 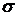 1 и 2 принадлежат одной генеральной совокупности.
1 и 2 принадлежат одной генеральной совокупности.
 ; (77)
; (77)
Если выполняется условие Fp < Fm, то модель адекватна и структура модели выбрана правильно. Иначе структуру модели нужно менять.
Табличное значение критерия Фишера Fm определяют по специальным таблицам в любой книге по мат.статистике. Fm находят в зависимости от степеней свободы α1 и α2, где под степенью свободы α1 понимается знаменатель 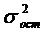 , а под α2 – знаменатель
, а под α2 – знаменатель 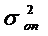 .
.
Нахождение дисперсии опыта. Пусть имеется K дублирующих экспериментов в пределах vmin - vmax. На каждый фиксированный момент времени найдем y срk и σ2k. Учитывая, что по одной из предпосылок МНК дисперсии однородны:
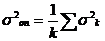
Таким образом, для остаточной дисперсии знаменатель будет равен α 1=N-M-1, а для дисперсии опыта α 2=(n-1)k.
3. Корреляционный анализ.
Этот метод рекомендуется для параметрического оценивания опосредованных связей. В этом случае говорить о действительности значений параметров модели не имеет смысла. Под опосредованными связями для нашего примера понимаются связи
y1=φ3{y2}; (78)
y2=φ4{y1}. (79)
Они названы опосредованными потому, что их статистическая связь обусловлена одновременным влиянием факторов v 1 и v 2 как на у 1, так и на у 2. И в этом случае мы с одинаковым основанием можем строить зависимость у 1 от у 2, так и наоборот у 2 от у 1.
В корреляционном анализе соответствие между моделью и экспериментальными данными осуществляется с помощью коэффициента множественной корреляции для многомерного случая, а в случае одномерной зависимости с помощью обычного коэффициента корреляции.
Коэффициент множественной корреляции или коэффициент детерминации:
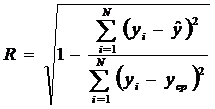 . (80)
. (80)
R - коэффициент множества корреляции;
где числитель – остаточная дисперсия (разброс фактических данных относительно линии регрессии), а знаменатель – дисперсия, как характеристика разброса относительно выборочной средней по y.
Чем больше R, тем теснее связь между у и v, тем точнее можно рассчитать значение у. Эта дробь показывает степень неопределенности, которую мы убрали.
Рассмотренные нами способы оценки соответствия полученной модели экспериментальным данным как для регрессионного, так и для корреляционного анализов являются эффективными, если выполняются все предпосылки этих методов. В свою очередь, предпосылки регрессионного и корреляционного анализа выполняются крайне редко, следовательно, часто могут быть расхождения между теоретическими результатами, полученными по критерию Стьюдента и Фишера, и фактическими результатами, полученными в конкретных задачах применения этих моделей.
В связи с этим при решении прикладных задач идентификации часто используются другие приемы оценки практической эффективности (полезности) построенных моделей.
В реальных системах можно для оценки полезности модели использовать целевой критерий, например, связанный с точностью модели. В простейшем случае, можно оценить остаточную дисперсию по отношению к дисперсии среднего, насколько уменьшилась неопределенность. Либо можно использовать критерии виде множественного коэффициента корреляции, т.к. в этом случае можно оценить насколько уменьшается среднее квадратичная ошибка с использованием полученных моделей по критерию Фишера или Стьюдента, то достаточно рассчитать Fp и сравнить его FT, чтобы проверить полезность модели, необходимо провести имитационное моделирование причем многократно.
Эти приемы в основном ориентируются на использование имитационного моделирования. Два случая:
Первый случай – формируется не одна, а несколько выборок экспериментальных данных. Часть из них используется в качестве обучающих выборок, т.е. на основе данных этих выборок решается задача структурного и параметрического оценивания. Вторая часть – контрольная выборка. На контрольных выборках реализуется оценка эффективности построенных моделей. При этом эту эффективность сравнивают по критериям точности и воспроизводимости результатов использования модели. Точность может оцениваться по коэффициенту множественной корреляции R, либо по среднеквадратической ошибке, а воспроизводимость результатов модели использования оценивается по изменению значения критерия точности, полученных на разных выборках. Если отклонения этих невелики (не более 5-10% от их уровня), то говорят, что результаты воспроизводятся, и модель может быть использована в практических приложениях. Воспроизводимость можно оценить следующим образом: пусть на n контрольных выборках получены следующие значения критериев точности q 1, q 2,..., q n. Их ранжируют, определяют q max и q min и в случае, если
| δq | = | q max - q min | ≤ 0,1 q max, (81)
то считают, что модель воспроизводится.
Второй случай – оценка практической полезности модели может так же производиться с помощью целевого критерия, т.е. того показателя, с помощью которого оценивается эффективность решения инженерной задачи с использованием построенной модели. Например, алгоритм регулирования, использующий ранее типовой закон, например ПИ, заменен на ВП-алгоритм. Для реализации последнего требуется модель канала регулирования. Такая модель построена, но возможность проверки ее полезности на множестве контрольных выборок отсутствует. В этом случае целесообразно практическую полезность модели проверить непосредственно по целевому критерию системы регулирования, например, по точности регулирования. И если по результатам испытаний новой системы, в алгоритме которой используется эта модель, полученно существенное повышение точности регулирования, например в 1,5-2 раза, то можно эту модель использовать для этой задачи.
Именно такие приемы оценки практической полезности математических моделей вместо традиционных Фишеровских и Стьюдентовских процедур считаются в настоящее время вполне пригодными и более эффективными.
Рассмотрим два чуть подробнее эти два подхода к оценке соответствия полученных моделей экспериментальных данных.
1. Имитационное моделирование с применением натурных данных
Натурные данные получают из действующих систем контроля по результатам пассивного, активного или комбинированного эксперимента. Главное здесь в том, что необходимо с комбинацией этих данных отобразить все основные особенности и условия функционирования объекта. Если эти условия могут существенно изменится, то, как правило, экспериментальные данные будут отражать изменения этих условий. Они (данные) будут характеризоваться различными статистическими свойствами, в частности, различен и характер изменения тренда (опорного уровня): постоянный, линейный, более сложный полиноминальный тренд; различная изменчивость около этих уровней. Чем больше изменчивость условий, тем больше нужно набрать таких групп данных, внутри которых их статистические свойства примерно одинаковы Но каждая группа друг от друга будет отличаться характером изменения тренда, изменчивостью около тренда и т.д. Причем в каждой группе должно быть не менее двух выборок, одна из них должна быть обучающей, а другие – контрольные. На обучающей выборке с помощью методов оптимизации, например поисковых процедур, осуществляется настройка параметров модели, а если это необходимо и ее структуры. Чаще всего в качестве начальных оценок искомых параметров модели при такой настройке берут значения, полученные расчетным путем с использованием, например, метода наименьших квадратов. Полученные модели на обучающих выборках проверяются затем на контрольных, то есть для каждой выборки рассчитывается критерий точности. На контрольных выборках точность всегда ниже, чем на обучающих. Если обучающих выборок несколько в каждой группе, то результат исследования выразится в конкретном диапазоне значений критерия. Такая процедура повторяется для каждой группы выборок данных. Это связано с тем, что эффективность проверяемых с помощью имитационного моделирования моделей, алгоритмов, систем должна оцениваться многократно, поскольку эффективность такой процедуры аналитически не доказана. В качестве критериев эффективности моделирования используют: точностные (среднемодульные, среднеквадратические) и критерии воспроизводимости (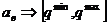 ). Критерий воспроизводимости может быть выражен через диапазон изменения точностных критериев. Чем меньше этот диапазон, тем воспроизводимость результатов лучше.
). Критерий воспроизводимости может быть выражен через диапазон изменения точностных критериев. Чем меньше этот диапазон, тем воспроизводимость результатов лучше.
2. Проверка полезности модели с помощью целевого критерия
В этом случае модель, построенная методами идентификации, проверяется с помощью целевого критерия. И если путем, например, имитационного моделирование будет показано с помощью целевого критерия, что конечный результат лучше, чем без этой модели, то модель можно считать полезной и использовать ее для решения этой конкретной задачи. Например, построенная модель используется в задаче управления, причем в состав алгоритма управления такая модель используется в явном виде. В данном случае целесообразно проверять не только повышение уровня целевого критерия, но и воспроизводимость его значений при функционировании системы для различных условий, т.е. в этом случае, как и в первом, используется моделирование, причем на множестве выборок многократно
Рассмотренные выше методы идентификации относятся к построению статических моделей, т.е. модели без учета времени. Классические методы идентификации объекта с помощи динамических моделей были даны в ТАУ раздел получение и обработка кривых разгона. Кроме этого, для этой цели также используются динамический корреляционный анализ, где оцениваются весовые или импульсные функции. Этот раздел находится на страницах 61 – 71. Следует понимать, что метод нельзя применять для управляемых объектов. В принципе его можно использовать выполнение, некоторых условий или активности эксперимента. Для такого случая исследования воздействий, должны изменять скачки или импульса, в виде случайного процесса или случайной функции.
Идентификация линейных динамических систем методами пассивного эксперимента (для ОУ не применим)
Date: 2015-07-22; view: 490; Нарушение авторских прав