Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Имитационное моделирование Монте-Карло
|
|
Метод имитационного моделирования Монте-Карло создает дополнительную возможность при оценке риска за счет того, что делает возможным создание случайных сценариев. Применение анализа риска использует богатство информации, будь она в форме объективных данных или оценок экспертов, для количественного описания неопределенности, существующей в отношении основных переменных проекта и для обоснованных расчетов возможного воздействия неопределенности на эффективность инвестиционного проекта. Результат анализа риска выражается не каким-либо единственным значением NPV, а в виде вероятностного распределения всех возможных значений этого показателя. Следовательно, потенциальный инвестор, с помощью метода Монте-Карло будет обеспечен полным набором данных, характеризующих риск проекта. На этой основе он сможет принять взвешенное решение о предоставлении средств.
В общем случае имитационное моделирование Монте-Карло — это процедура, с помощью которой математическая модель определения какого-либо финансового показателя (в нашем случае NPV) подвергается ряду имитационных прогонов с помощью компьютера. В ходе процесса имитации строятся последовательные сценарии с использованием исходных данных, которые по смыслу проекта являются неопределенными, и потому в процессе анализа полагаются случайными величинами. Процесс имитации осуществляется таким образом, чтобы случайный выбор значений из определенных вероятностных распределений не нарушал существования известных или предполагаемых отношений корреляции среди переменных. Результаты имитации собираются и анализируются статистически, с тем, чтобы оценить меру риска.
Процесс анализа риска может быть разбит на следующие стадии.
| Прогнозная модель Подготовка модели, способной прогнозировать расчет эффективности проекта | ® | Распределение вероятности (шаг 1) Определение вероятностного закона распределения случайных переменных | ® | Распределение вероятности (шаг 2) Установление границ диапазона значений переменных | ® |
| ® | Условия корреляции Установление отношений коррелированных переменных | ® | Имитационные прогоны Генерирование случайных сценариев, основанных на наборе допущений | ® | Анализ результатов Статистический анализ результатов имитации |
Рис. 8.2. Процесс анализа риска
Первая стадия в процессе анализа риска — это создание прогнозной модели. Такая модель определяет математические отношения между числовыми переменными, которые относятся к прогнозу выбранного финансового показателя. В качестве базовой модели для анализа инвестиционного риска обычно используется модель расчета показателя NPV
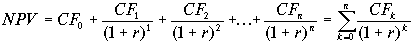 .
.
Использование этой формулы в анализе риска сопряжено с некоторыми трудностями. Они заключаются в том, что при генерировании случайных чисел, годовой денежный поток выступает как некое случайное число, подчиняющееся определенному закону распределения. В действительности же это совокупный показатель, включающий множество компонент рассмотренных в предыдущих публикациях. Этот совокупный показатель изменяется не сам по себе, а с учетом изменения объема продаж. То есть ясно, что он коррелирован с объемом. Поэтому необходимо тщательно изучить эту корреляцию для максимального приближения к реальности.
Общая прогнозная модель имитируется следующим образом. Генерируется достаточно большой объем случайных сценариев, каждый из которых соответствует определенным значениям денежных потоков. Сгенерированные сценарии собираются вместе и производится их статистическая обработка для установления доли сценариев, которые соответствуют отрицательному значению NPV. Отношение таких сценариев к общему количеству сценариев дает оценку риска инвестиций.
Распределения вероятностей переменных модели (денежных потоков) диктуют возможность выбора величин из определенных диапазонов. Такие распределения представляют собой математические инструменты, с помощью которых придается вес всем возможным результатам. Этим контролируется случайный выбор значений для каждой переменной в ходе моделирования.
Необходимость применения распределения вероятностей обусловлена попытками прогнозирования будущих событий. При обычном анализе инвестиций используется один тип распределения вероятности для всех переменных, включенных в модель анализа. Такой тип называют детерминированным распределением вероятности, и он придает всю вероятность одному значению. При оценке имеющихся данных аналитик ограничен выбором единственного из множества возможных результатов или расчетом сводного показателя. Затем аналитик должен принять, что выбранное значение обязательно реализуется, то есть он придает выбранному наиболее обоснованным образом показателю с единственным значением вероятность, равную 1. Поскольку такое распределение вероятности имеет единственный результат, итог аналитической модели можно определить на основании всего одного расчета (или одного прогона модели).
В анализе рисков используется информация, содержащаяся в распределении вероятности с множественными значениями. Именно использование множественных значений вместо детерминированных распределений вероятности и отличает имитационное моделирование от традиционного подхода.
Определение случайных переменных и придание им соответствующего распределения вероятности является необходимым условием проведения анализа рисков. Успешно завершив эти этапы, можно перейти к стадии моделирования. Однако непосредственный переход к моделированию будет возможен только в том случае, если будет установлена корреляция в системе случайных переменных, включенных в модель. Под корреляцией понимается случайная зависимость между переменными, которая не носит строго определенного характера, например, зависимость между ценой реализации товара и объемом продаж.
Наличие в модели анализа коррелированных переменных может привести к серьёзным искажениям результатов анализа риска, если эта корреляция не учитывается. Фактически наличие корреляции ограничивает случайный выбор отдельных значений для коррелированных переменных. Две коррелированные переменные моделируются так, что при случайном выборе одной из них другая выбирается не свободно, а в диапазоне значений, который управляется смоделированным значением первой переменной.
Хотя очень редко можно объективно определить точные характеристики корреляции случайных переменных в модели анализа, на практике имеется возможность установить направление таких связей и предполагаемую силу корреляции. Для этого применяют методы регрессионного анализа. В результате этого анализа рассчитывается коэффициент корреляции, который может принимать значения от -1 до 1.
Стадия "прогонов модели" является той частью процесса анализа риска, на которой всю рутинную работу выполняет компьютер. После того, как все допущения тщательно обоснованы, остается только последовательно просчитывать модель (каждый пересчет является одним "прогоном") до тех пор, пока будет получено достаточно значений для принятия решения (например, более 1000).
В ходе моделирования значения переменных выбираются случайно в границах заданных диапазонов и в соответствии с распределениями вероятностей и условиями корреляций. Для каждого набора таких переменных вычисляется значение показателя эффективности проекта. Все полученные значения сохраняются для последующей статистической обработки.
Для практического осуществления имитационного моделирования можно рекомендовать пакет "Risk Master", разработанный в Гарвардском университете. Генерирование случайных чисел этот пакет осуществляет на основе использования датчика псевдослучайных чисел, которые рассчитываются по определенному алгоритму. Особенностью пакета является то, что он умеет генерировать коррелированные случайные числа.
Окончательной стадией анализа рисков является обработка и интерпретация результатов, полученных на стадии прогонов модели. Каждый прогон представляет вероятность события, равную
p = 100: n,
где p — вероятность единичного прогона, %;
n — размер выборки.
Например, если количество случайных прогонов равно 5000, то вероятность одного прогона составляет
p = 100: 5000 = 0,02 %.
В качестве меры риска в инвестиционном проектировании целесообразно использовать вероятность получения отрицательного значения NPV. Эта вероятность оценивается на основе статистических результатов имитационного моделирования как произведение количества результатов с отрицательным значением и вероятности единичного прогона. Например, если из 5000 прогонов отрицательные значения NPV окажутся в 3454 случаях, то мера риска составит 69.1%.
Date: 2015-10-22; view: 664; Нарушение авторских прав