Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Синтаксический анализ арифметических выражений
|
|
Задача синтаксического анализа заключается в том, чтобы по имеющейся строке, содержащей арифметическое выражение, и известным значениям, входящих в нее переменных, вычислить значение выражения.
Процесс вычисления арифметических выражений можно представить в виде бинарного дерева. Действительно, каждый из арифметических операторов (+, –, *, /) требует двух операндов, которые также будут являться арифметическими выражениями и, соответственно могут рассматриваться как поддеревья. Рис. 8 показывает пример дерева, соответствующего выражению:
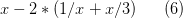
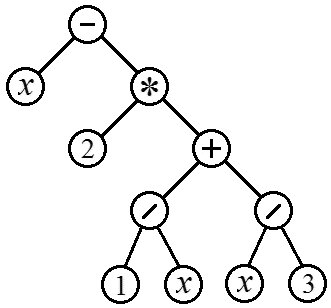
Рис. 8. Синтаксическое дерево, соответствующее арифметическому выражению (6).
В таком дереве концевыми узлами всегда будут переменные (здесь x) или числовые константы, а все внутренние узлы будут содержать арифметические операторы. Чтобы выполнить оператор, надо сначала вычислить его операнды. Таким образом, дерево на рисунке следует обходить в концевом порядке. Соответствующая последовательность узлов
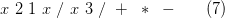
называется обратной польской записью арифметического выражения.
При построении синтаксического дерева следует обратить внимание на следующую особенность. Если есть, например, выражение
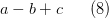
и операции сложения и вычитания мы будем считывать слева на право, то правильное синтаксическое дерево будет содержать минус вместо плюса (рис. 9а). По сути, это дерево соответствует выражению 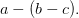 Облегчить составление дерева можно, если анализировать выражение (8) наоборот, справа налево. В этом случае получается дерево с рис. 9б, эквивалентное дереву 8а, но не требующее замены знаков.
Облегчить составление дерева можно, если анализировать выражение (8) наоборот, справа налево. В этом случае получается дерево с рис. 9б, эквивалентное дереву 8а, но не требующее замены знаков.
Аналогично справа налево нужно анализировать выражения, содержащие операторы умножения и деления.
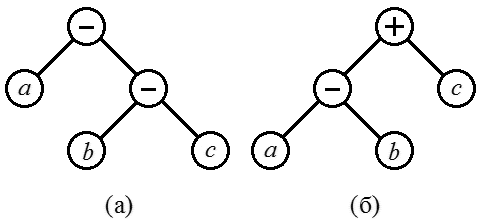
Рис. 9. Синтаксические деревья для выражения a – b + c при чтении слева направо (а) и справа налево (б).
В файле SynAn.pas приведен пример функции, вычисляющей значения выражений, содержащих только одну переменную x. Дадим краткое описание реализованного там алгоритма:
1. Вычисляющая выражение функция (CalcExpression) находит в строке все знаки «+» и «–», не заключенные в скобки. Эти знаки разбивают выражение на части, содержащие (вне скобок) только операции умножения и деления. Для вычисления значений этих частей вызывается функция CalcMultDiv.
2. Функция CalcMultDiv находит в строке все знаки «*» и «/», не заключенные в скобки. Эти знаки разбивают выражение на части, содержащие числовые константы, переменную x или выражения в скобках. Для вычисления значений этих частей вызывается функция CalcValuesOrOpenParentheses.
3. Функция CalcValuesOrOpenParentheses определяет тип попавшего ей на вход выражения. Если это числовая константа или переменная x, то она возвращает их значение. Если это выражение в скобках, то для его вычисления рекурсивно вызывается процедура CalcExpression.
Заметим, что в данном примере вычисления производятся одновременно с анализом строкового выражения. Это приводит к тому, что для некоторых выражений вычисления могут происходить в 100 – 1000 раз медленнее, чем, если бы эти выражения были скомпилированы как часть программы. Если одно и то же выражение требуется вычислить много раз при различных значения переменных, то следует разделить анализ строки и вычисления. Такой подход может позволить ускорить вычисления в сотни раз.
Результатом анализа строки должна быть последовательность узлов дерева в концевом порядке. Каждый узел должен хранить информацию о подузлах и о той операции, которая в нем совершается. Например, узлы можно реализовать в виде записей, одно из полей который имеет процедурный тип. Другой вариант – каждый узел это объект, где операция реализована как виртуальный метод.
Быстрые сортировки
Простые методы сортировки вроде метода выбора или метода пузырька сортируют массив из n элементов за O(n 2) операций. Однако с помощью принципа «разделяй и властвуй» удается построить более быстрые, работающие за O(n log2 n) алгоритмы. Суть этого принципа в том, что решение получается путем рекурсивного разделения задачи на несколько простые подзадачи того же типа до тех пор, пока они не станут элементарными. Приведем в качестве примеров несколько быстрых алгоритмов такого рода.
Алгоритм 1: «Быстрая» сортировка (quicksort).
1. Выбирается опорный элемент (например, первый или случайный).
2. Реорганизуем массив так, чтобы сначала шли элементы меньшие опорного, потом равные ему, затем большие. Для этого достаточно помнить, сколько было найдено меньших (m 1) и больших (m 2), чем опорный и ставить очередной элемент на место с индексом m 1, а очередной больший на место с индексом n -1- m 2.
После выполнения такой операции опорный элемент и равные ему стоят на своем месте, их переставлять больше не придется. Между «меньшей» и «большей» часть массива перестановок также быть не может. То есть эти части можно сортировать независимо друг от друга.
3. Если «меньшая» или «большая» часть состоит из одного элемента, то она уже отсортирована и делать ничего не надо. Иначе сортируем эти части с помощью алгоритма быстрой сортировки (то есть, выполняем для нее шаги 1-3).
Как видите, быстрая сортировка состоит из выполнения шагов 1 и 2 и рекурсивного вызова алгоритма для получившихся частей массива.
Алгоритм 2: Сортировка слиянием (merge sort).
1. Делим массив на две части примерно одинакового размера и, если получившаяся половина массива содержит больше одного элемента, то сортируем ее с помощью сортировки слиянием. Как видите, этот пункт содержит рекурсивное обращение ко всему алгоритму в целом.
2. Соединяем две отсортированные половины так, чтобы получился один отсортированный массив. Для этого помещаем во вспомогательный массив элементы из первой половины, пока они не превосходят очередного элемента из второй половины. Затем начинаем помещать туда элементы второй половины, пока они не превосходят очередного элемента из первой половины. Затем снова берем элементы первой половины и т.д. Эта операция называется слиянием и требует столько шагов, сколько элементов в обоих соединяемых массивах.
Алгоритм 3: Сортировка деревом (tree sort).
Прежде чем переходить к объяснению сути алгоритма введем одно понятие. Двоичным деревом поиска называется бинарное дерево, в узлах которого располагаются числа таким образом, что в левом поддереве каждого узла находятся числа меньшие, чем в этом узле, а в правом поддереве больше или равные тому, что в этом узле. На рис. 10 показано два примера деревьев поиска, составленных из одних и тех же чисел.
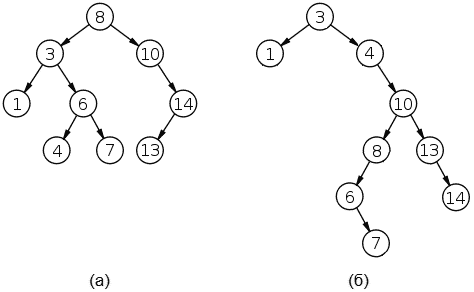
Рис. 10. Двоичные деревья поиска, составленные из чисел 1, 3, 4, 6, 7, 8, 10, 13, 14.
Если для каждой вершины высота поддеревьев различается не более чем на единицу, то дерево называется сбалансированным. Сбалансированные деревья поиска также называются АВЛ-деревьями (по первым буквам фамилий изобретателей Г. М. Адельсона-Вельского и Е. М. Ландиса). Как видно на рис. 10а показано сбалансированное дерево, на рис. 10б несбалансированное.
Заметим, что расположение чисел по возрастанию получится, если обходить эти деревья в обратном прядке.
Сортировка деревом получится, если мы сначала последовательно будем добавлять числа из массива в двоичное дерево поиска, а затем обойдем его в обратном порядке.
Если дерево будет близко к сбалансированному, то сортировка потребует примерно n log2 n операций. Если не повезет и дерево окажется максимально несбалансированным, то сортировка займет n 2 операций.
Date: 2016-07-18; view: 647; Нарушение авторских прав