Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Расчет стандартного отклонения ^ для фона контрольной группы
|
|
Испытуемые Число пора- Средняя Отклоне- Квадрат от-женных мише- ние от клонения от ней в серии средней (d) средней (d2)
19 10
15,8 15,8 15,8
-3,2 +5.8 +3,8
10.24 33,64 14,44
15 22 15,8 -6,2 38,44
Сумма (^)d2 = 131,94
131,94
Варианса (s2} = • = 9,42.
Н-1 14 Стандартное отклонение (?) = ^'варианса = л/9,42 == 3,07.
' Формула для расчетов и сами расчеты приведены здесь лишь в качестве иллюстрации В наше время гораздо проще приобрести гакой карманный микрокалькулятор, в котором подобные расчеты уже заранее запрограммированы, и для расчета стандартного отклонения достаточно лишь ввести данные, а затем нажать клавишу s.
О чем же свидетельствует стандартное отклонение, равное 3,07? Оказывается, оно позволяет сказать, что большая часть результатов (выраженных здесь числом пораженных мишеней) располагается в пределах 3,07 от средней, т.е. между 12,73 (15,8 - 3,07) и 18,87 (15,8 + 3,07).
Для того чтобы лучше понять, что подразумевается под «большей частью результатов», нужно сначала рассмотреть те свойсгва стандартного отклонения, которые проявляются при изучении популяции с нормальным распределением.
Статистики показали, что при нормальном распределении «большая часть» результатов, располагающаяся в пределах одного стандартного отклонения по обе стороны от средней, в процентном отношении всегда одна и та же и не зависит от величины стандартного отклонения: она соответствует 68% популяции (т.е. 34% ее элементов располагается слева и 34%-справа от средней):
Приложение Б 
Точно так же рассчитали, что 94,45% элементов популяции при нормальном распределении не выходит за пределы двух стандартных отклонений от средней:
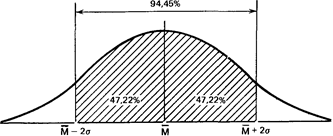
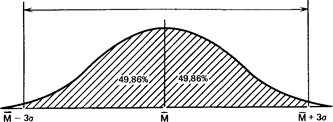
и что в пределах трех стандартных отклонений умещается почти вся популяция - 99,73 %.
99.73%
Учитывая, что распределение частот фона контрольной группы довольно близко к нормальному, можно полагать, что 68% членов всей популяции, из которой взята выборка, тоже будет получать сходные результаты, т.е. попадать примерно в 13-19 мишеней из 25. Распределение результатов остальных членов популяции должно выглядеть следующим образом:
Статистика и обработка данных
99,7%
95,4%
68,3%
34,1 % 34,1 % 2,2%
0,13%
13,6%
13,6%
0,13%
6,59 9,66 12,73 15,8 18,87 21,94 25,01
-Id +1(7
-2а +2о
-За +3а
Гипотетическая популяция,
из которой взята контрольная группа (фон)
Что касается результатов той же группы после воздействия изучаемого фактора, то стандартное отклонение для них оказалось равным 4,25 (пораженных мишеней). Значит, можно предположить, что 68% результатов будут располагаться именно в этом диапазоне отклонений от средней, составляющей 16 мишеней, т.е. в пределах от 11,75 (16 — 4,25) до 20,25 (16 + 4,25), или, округляя, 12 — 20 мишеней из 25. Видно, что здесь разброс результатов больше, чем в фоне. Эту разницу в разбросе между двумя выборками для контрольной группы можно графически представить следующим образом:
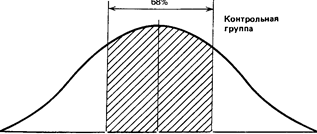
12,73 15,8 18,87
-la +lo Фон
294 Приложение Б
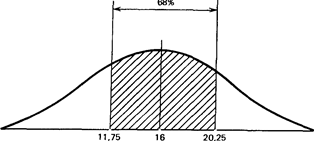
-1о +1о После воздействия
Поскольку стандартное отклонение всегда соответствует одному и тому же проценту результатов, укладывающихся в его пределах вокруг средней, можно утверждать, что при любой форме кривой нормального распределения та доля ее площади, которая ограничена (с обеих сторон) стандартным отклонением, всегда одинакова и соответствует одной и той же доле всей популяции. Это можно проверить на тех наших выборках, для которых распределение близко к нормальному,-на данных о фоне для контрольной и опытной групп.
Итак, ознакомившись с описательной статистикой, мы узнали, как можно представить графически и оценить количественно степень разброса данных в том или ином распределении. Тем самым мы смогли понять, чем различаются в нашем опыте распределения для контрольной группы до и после воздействия. Однако можно ли о чем-то судить по этой разнице - отражает ли она действительность или же это просто артефакт, связанный со слишком малым объемом выборки? Тот же вопрос (только еще острее) встает и в отношении экспериментальной группы, подвергнутой воздействию независимой переменной. В этой группе стандартное отклонение для фона и после воздействия тоже различается примерно на 1 (3,14 и 4,04 соответственно). Однако здесь особенно велика разница между средними-15,2 и 11,3. На основании чего можно было бы утверждать, что эта разность средних действительно достоверна, т.е.-достаточно велика, чтобы можно было с уверенностью объяснить ее влиянием независимой переменной, а не простой случайностью? В какой степени можно опираться на эти результаты и распространять их на всю популяцию, из которой взята выборка, i. е. утверждать, что потребление марихуаны и в самом деле обычно ведет к нарушению глазодвигатель-ной координации?
На все эти вопросы и пытается дать ответ индуктивная статистика.
Статистика и обработка данных 295
Date: 2015-09-22; view: 681; Нарушение авторских прав