Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Система освоения и исследования методов идентификации
|
|
Целью создания автоматизированной системы является освоение аппарата многовариантной идентификации зависимостей и приобретение умения применять методы и алгоритмы идентификации в реальных условиях. Освоение любых алгоритмов, в том числе и алгоритмов идентификации, представляет творческий процесс, в котором ведущая роль принадлежит человеку: Учителю и Обучаемому. Именно с этих позиций построена автоматизированная обучающая система, где компьютерная составляющая, методическое руководство и теоретические основы идентификации, изложенные в публикациях, служат подсобным материалом для Учителя и Обучаемого. Основное творческое освоение алгоритмов идентификации, включая методы их структурного и параметрического синтеза, анализа, предпосылки и области применения, должно, конечно, осуществляться на стадии изучения теоретических основ. Компьютерная же часть системы предназначена, главным образом, для наглядного представления исходных и расчетных данных, особенно их динамики, и существенного сокращения временных затрат на вычисления, в частности, при исследовании эффектов от нарушения предпосылок алгоритмов.
Данная обучающая система не охватывает весь круг задач идентификации, а ориентирована только на освоение одного из классов алгоритмов идентификации - многовариантных алгоритмов идентификации линейно-параметрических зависимостей и в начальной форме включает 7 алгоритмов. Однако оболочка системы сделана по открытому принципу и позволяет расширить набор алгоритмов без каких-либо изменений в существующей части программно-компьютерного обеспечения. Это же относится и к формированию исходных данных и к критериям эффективности идентификации. В основу построения системы положена многовариантная структура канального типа, включающая рабочий и нормативный каналы и являющаяся частным случаем автоматизированного тренажерно-обучающего комплекса.
Рассматриваемая обучающая система содержит следующие основные блоки получения, обработки и представления информации: блок формирования модельных, натурных и натурно-модельных данных; блок задания исходных условий и ограничений; информационно-справочный блок; блок идентификации зависимостей и воздействий с использованием обычных, робастных и многовариантных алгоритмов; блок оценивания точности идентификации; блок представления данных в табличной и графической форме, блок оценки эффективности обучения.
Блок задания исходных условий служит для задания начальных условий и ограничений: длины выборки, количества входных величин, количества рассчитываемых вариантов решений и так далее, а также для формирования модельных, натурно-модельных и натурных данных. При этом предусмотрена возможность формирования данных как Учителем, так и Обучаемым. Полученные выборки данных при необходимости могут храниться на дисках.
Модельные данные формируются по правилу
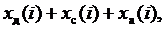 (9.20)
(9.20)
где x д (i) - детерминированная составляющая: xс(i) - статистически воспроизводимая случайная составляющая: x а (i) - составляющая, характеризующая редкие аномальные выбросы.
Детерминированная составляющая выбирается из следующего списка: постоянная величина; воздействие ступенчатого вида; кусочно-линейная зависимость; параболическая зависимость. Для формирования случайной составляющей используется генератор случайных чисел, для чего необходимо задать математическое ожидание и среднеквадратическое отклонение этой составляющей. Аномальные выбросы налагаются на сформированные данные x д (i) и xс(i), представленные в таблице (рис. 9.15). Данные можно корректировать вручную.
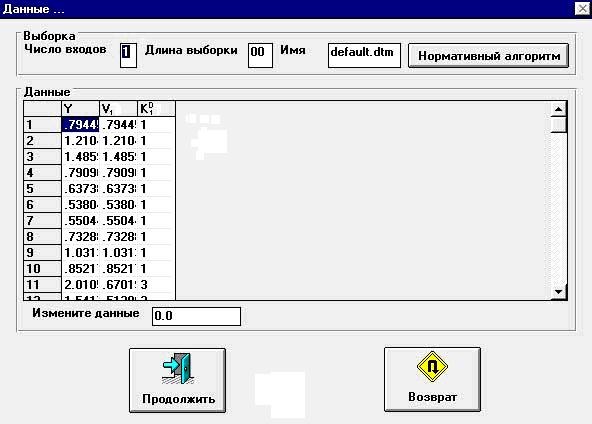
Рис.9.15. Пример таблицы сформированных данных
Натурные данные могут быть введены непосредственно с клавиатуры, либо выбраны из каталога, сформированного заранее (рис. 9.16). Предусмотрена возможность предварительной обработки натурных данных, а именно, выделение базовой составляющей. Для этих целей используется следующий алгоритм.
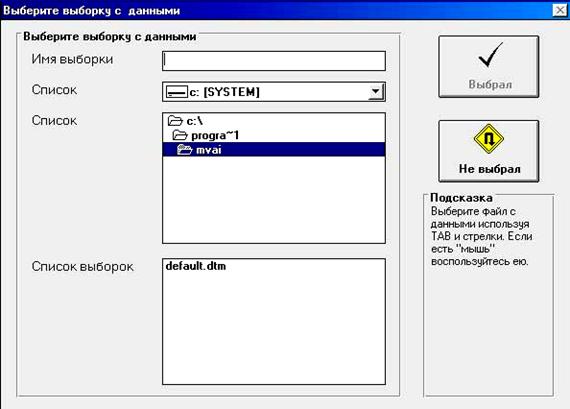
Рис. 9.16. Пример выбора заранее сформированных данных
1. Сглаживание временных рядов натурных данных по формуле
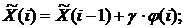
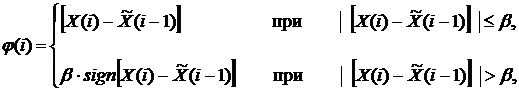
где 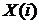 - вектор входных и выходных величин объекта идентификации в i –й дискретный момент времени;
- вектор входных и выходных величин объекта идентификации в i –й дискретный момент времени; 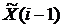 - вектор сглаженных значений входных и выходных величин в (i-1)- й момент времени;
- вектор сглаженных значений входных и выходных величин в (i-1)- й момент времени; 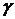 ,
, 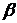 - настроечные коэффициенты.
- настроечные коэффициенты.
2. Вычисление отклонений 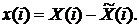
3. Нормирование (масштабирование) натурных данных  ,
,
где  - максимальное значение приращения величины, полученное при сглаживании.
- максимальное значение приращения величины, полученное при сглаживании.
После выполнения перечисленных операций, информация о сформированных данных в виде таблицы (рис. 9.15) выдаётся на экран монитора.
Натурно–модельные данные формируются следующим образом:
- детерминированная модельная составляющая x д (i) заменяется низкочастотной (базовой) составляющей натурных данных, выделенной, например, путем релейно–экспоненциального сглаживания, а составляющие x с (i) и x а (i) - остаются модельными;
- детерминированная составляющая x д (i) остается модельной, а составляющие x с (i) и x а (i) заменяются на отклонения натурных данных от их базовой составляющей.
Блок расчета оценок коэффициентов включает набор алгоритмов рекуррентной идентификации линейно-параметрических зависимостей.
Рассматриваемые в системе алгоритмы представлены на рисунках 9.17–9.22. После выполнения расчетов, полученные результаты представляются в виде таблицы (рис. 9.23) и в виде графиков (рис. 9.24). В системе заложены следующие критерии оценивания эффективности идентификации:
- при расчете с использованием модельных данных
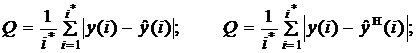
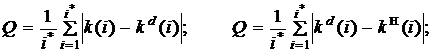
- при расчете с использованием натурных и натурно-модельных данных
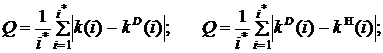
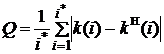 ,
,
где i* - объем фиксированной или скользящей выборки данных; у(i) - выходная переменная объекта идентификации; 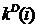 - действительные значения коэффициентов; k(i) - оценки коэффициентов, рассчитанные по выбранному алгоритму;
- действительные значения коэффициентов; k(i) - оценки коэффициентов, рассчитанные по выбранному алгоритму; 
 - оценки коэффициентов, рассчитанные по нормативному алгоритму, который при необходимости задается Учителем с указанием всех настраиваемых параметров и начальных условий.
- оценки коэффициентов, рассчитанные по нормативному алгоритму, который при необходимости задается Учителем с указанием всех настраиваемых параметров и начальных условий.
В ходе обучения решаются задачи освоения предпосылок применения алгоритмов идентификации; построения линейно-параметрических зависимостей; проведения сравнительного анализа нескольких вариантов решений. При этом выделены следующие основные предпосылки использования алгоритмов рекуррентной идентификации линейно–параметрических зависимостей:
1.Структура модели выходной переменной 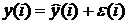 объекта идентификации задана в виде линейно-параметрической зависимости [17, c. 450, п.2]
объекта идентификации задана в виде линейно-параметрической зависимости [17, c. 450, п.2]
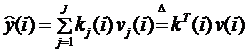 , (9.21)
, (9.21)
где 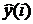 - расчетная выходная величина в i -й дискретный момент времени), k(i) - вектор подлежащих оцениванию параметров (коэффициентов), v(i) - вектор входных переменных,
- расчетная выходная величина в i -й дискретный момент времени), k(i) - вектор подлежащих оцениванию параметров (коэффициентов), v(i) - вектор входных переменных,  - неизменяемое возмущение.
- неизменяемое возмущение.
2. Величина y(i) распределена нормально [17, с 450, п.1, с. 536, п.1] для каждого фиксированного значения vj(i).
3. Дисперсия величины y(i) постоянна, т.е. не зависит от vj(i) или пропорциональна заданной линейно-параметрической зависимости от vj(i) [17, с.451, п.3, с.536, п.З].
4. Величины стохастически независимы, то есть значения vj(i) стохастически независимы от vj(i+1), а y(i) - от y(i+1), [17, с.536, п.4; 18, с.41].
5. Входные величины v1(i), v2(i), …, vj(i) некоррелированы между собой [17, с.536, 540, 524; 19, с.25].
6. Входные величины vj(i) не должны содержать ошибок измерения [17, с.525; 19, c.25-28].
7. Неизмеряемое возмущение представляет собой последовательность независимых случайных величин с нулевыми средними значениями и дисперсией (неизвестной)  [20, c.399; 21, с.29].
[20, c.399; 21, с.29].
8. Отсутствие корреляции между и vj(i) [20, с. 405].
9. Последовательности оценок коэффициентов имеют относительно медленно меняющуюся динамику по сравнению с изменением входных величин vj(i) [22, с.141].
10. "Наилучшие" оценки для параметров (коэффициентов) получаются при применении метода наименьших квадратов [17, с.451]. "Наилучшие" в том смысле, что они распределены нормально со средними значениями, равными искомым параметрам, и с наименьшими возможными дисперсиями [17 с.451].
Примеры последствий нарушения исходных предпосылок. Наиболее полезным для обучения в рамках решаемых задач представляется выявление и демонстрация характерных эффектов нарушения исходных предпосылок, среди которых можно перечислить следующие: наличие прямых и обратных регулирующих связей объекта идентификации; описание приведенной помехи с помощью "белого" и "небелого" шума; наличие ошибок измерения и расчета входных переменных; ограниченной выборки данных; неадекватной структуры модели; наличие или отсутствие априорной информации, аномальных данных; структуры критериев идентификации; динамических свойств рядов данных и изменений коэффициентов зависимостей. В качестве примера приведем некоторые результаты.
Использование одновариантного алгоритма (рис.9.17) для уточнения математической модели объекта идентификации, имеющего одну входную 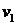 и одну выходную у переменных, при соблюдении перечисленных выше предпосылок приводит к результатам, представленных на рис. 9.25. Видно, что даже при
и одну выходную у переменных, при соблюдении перечисленных выше предпосылок приводит к результатам, представленных на рис. 9.25. Видно, что даже при 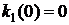 наблюдается быстрая сходимость оценок коэффициентов (при различных значениях параметра
наблюдается быстрая сходимость оценок коэффициентов (при различных значениях параметра 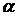 ).
).
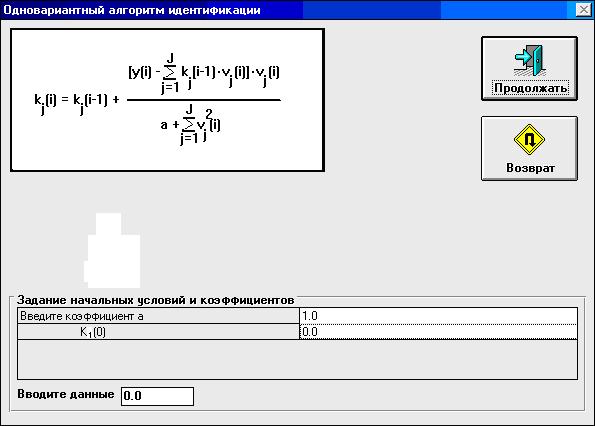
Рис. 9.17. Одновариантный алгоритм идентификации
Нарушение, например, шестой предпосылки, как видно из рис. 9.26, приводит к существенному искажению оценок коэффициента k1 и следовательно выходной величины 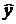 , рассчитанной по модели (9.21).
, рассчитанной по модели (9.21).
Аналогичный эффект наблюдается и в случае действия аномальных данных (выбросов) (рис. 9.27).
 Рис. 9.27. Эффект аномальных данных: - аномальные данные (выбросы)
Рис. 9.27. Эффект аномальных данных: - аномальные данные (выбросы)
Использование в этом случае робастных алгоритмов идентификации, например, следующего вида
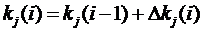 ;
; 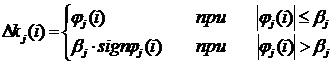 ,
,
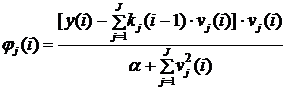 (9.22)
(9.22)
позволяет значительно улучшить результаты и получить хорошую сходимость оценок коэффициента (рис. 9.28).
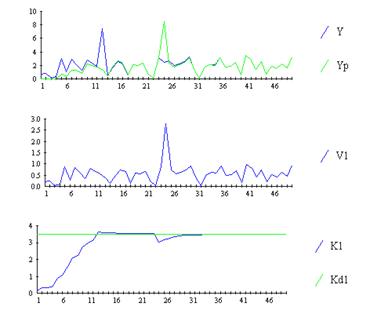
Рис. 9.28. Результаты идентификации при использовании робастного алгоритма
Эффекты нарушения пятой предпосылки продемонстрированы на примере объекта идентификации с двумя входными , 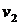 и одной выходной y переменными. Как видно из рис. 9.29, коррелированность входных величин приводит к смещению оценок коэффициентов
и одной выходной y переменными. Как видно из рис. 9.29, коррелированность входных величин приводит к смещению оценок коэффициентов 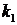 и
и 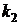 При этом значения выходной величины , рассчитанные по модели (9.22) совпадают с фактическим значением y.
При этом значения выходной величины , рассчитанные по модели (9.22) совпадают с фактическим значением y.
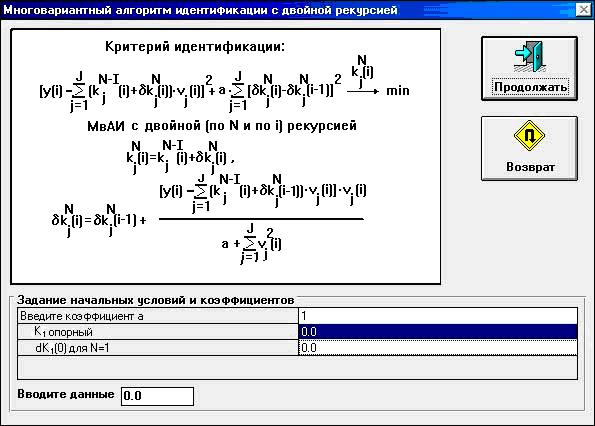
Рис. 9.22. Многовариантный алгоритм идентификации с двойной рекурсией
В этом случае для устранения такого существенного недостатка предлагается скорректировать известный алгоритм (2.36),? используя схему Гаммерштейна [15] с переопределением входного сигнала. Так, в рассматриваемом примере 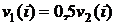 . В соответствии с этим получим и новые формулы для расчёта оценок коэффициентов и k2, а именно
. В соответствии с этим получим и новые формулы для расчёта оценок коэффициентов и k2, а именно
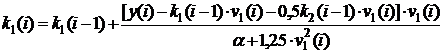 ,
,
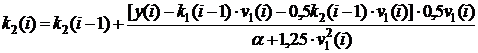 . (9.23)
. (9.23)
Использование этих формул приводит к хорошим результатам, представленным, например, на рисунке 9.30.
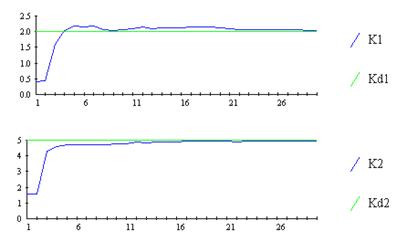
Рис. 9.30 Результаты идентификации при использовании алгоритма (9.23)
Отсюда следует, что использование в роли базовой структуры модели линейно–параметрической зависимости открывает широкие возможности для получения новых алгоритмов рекуррентной идентификации. Однако, применение этих алгоритмов для структуры модели другого типа (нарушение первой предпосылки) приводит к значительному искажению оценок коэффициентов (рис. 9.31).
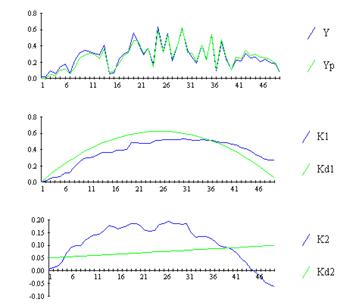
Рис. 9.31 Эффект неадекватной структуры модели
Эффект приведённой помехи типа «белого» и «небелого» шума показан на рис. 9.32, из которого следует, что при 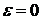 наблюдается достаточно быстрая сходимость оценок коэффициента
наблюдается достаточно быстрая сходимость оценок коэффициента 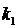 (рис. 9.32а). В случае действия приведённой помехи типа «белого» шума использование алгоритма также даёт хорошие результаты (рис. 9.32б). Действие же на выходе объекта идентификации «небелого» шума значительно затрудняет нахождение оценок коэффициента k1, близких к действительным значениям
(рис. 9.32а). В случае действия приведённой помехи типа «белого» шума использование алгоритма также даёт хорошие результаты (рис. 9.32б). Действие же на выходе объекта идентификации «небелого» шума значительно затрудняет нахождение оценок коэффициента k1, близких к действительным значениям 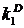 (рис. 9.32в).
(рис. 9.32в).
|
|
|
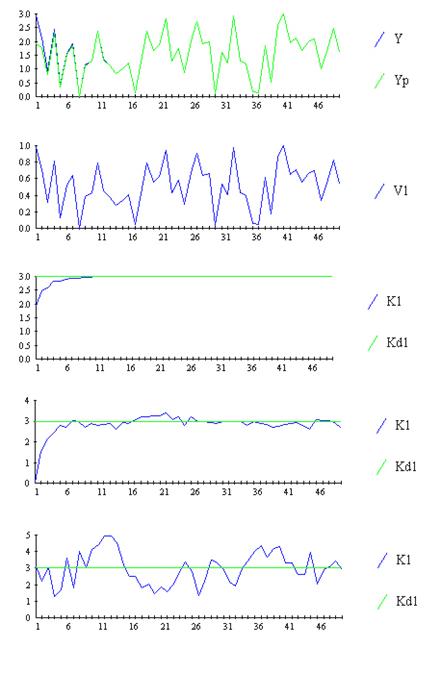
Рис. 9.32. Эффект приведённой помехи типа «белого» и «небелого шума
Изложенные выводы подтверждаются графиком, представленным на рис. 9.33, где показано изменение среднемодульного критерия
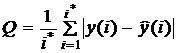
от величины дисперсии приведённой помехи 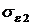 .
.
|
Для улучшения качества идентификации в таких случаях рекомендуется использовать процедуры сглаживания временных рядов данных, например, типа экспоненциального или релейно-экспоненциального сглаживания.
Представляет интерес изучение эффекта динамических свойств рядов данных и изменений коэффициентов зависимостей. Ниже рассмотрим три случая:
а) динамические свойства рядов данных и изменений коэффициентов зависимостей одинаковые;
б) более медленное изменение коэффициентов зависимостей по сравнению с изменением свойств рядов данных;
в) более быстрое изменение коэффициентов зависимостей по сравнению с изменением свойств рядов данных.
Полученные результаты, представленные на рис. 9.34, подтвердили необходимость обязательного выполнения девятой предпосылки. Последовательности оценок коэффициентов должны иметь относительно медленно меняющуюся динамику по сравнению с изменением входных величин.
Одной из наиболее важных предпосылок использования алгоритма рекуррентной идентификации является отсутствие корреляции между и vj(i). Нарушение этой предпосылки приводит к так называемому эффекту влияния прямых и обратных связей, имеющих место для управляемых объектов идентификации. Использование алгоритма рекуррентной идентификации для оперативного уточнения оценок коэффициентов математической модели даёт хорошие результаты для квазиразомкнутых систем, что характеризуется отсутствием корреляции между и vj(i) рис. 9.35.
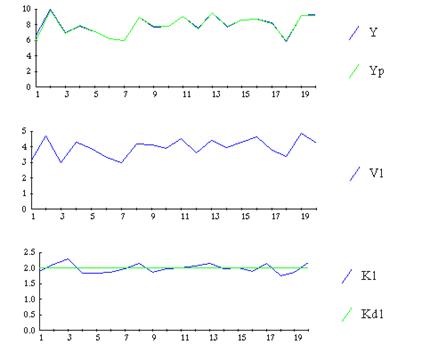
Рис. 9.35. Эффект прямых регулирующих связей (отсутствие корреляции между и vj(i))
Применение же алгоритма для уточнения оценок в системах регулирования приводит к значительному искажению получаемых оценок коэффициентов. Это для примера показано на рис. 9.36.
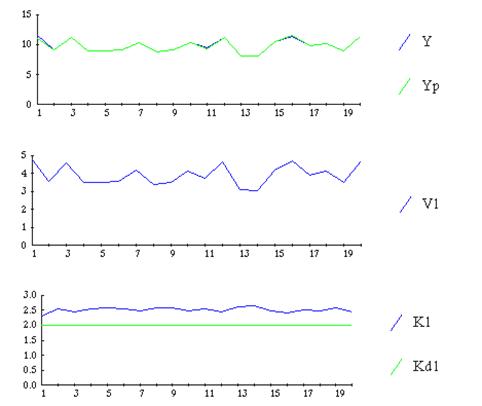
Рис. 9.36. Эффект обратных регулирующих связей (при наличии корреляции между и vj(i))
Разработанная обучающая система позволяет достаточно быстро освоить предлагаемые алгоритмы рекуррентной идентификации, выявить области их эффективного применения, проводить необходимые для теории и практики исследования.
Date: 2015-07-22; view: 595; Нарушение авторских прав