Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Взвешенный метод наименьших квадратов
|
|
Далеко не все задачи исследования взаимосвязей экономических переменных описываются обычной линейной регрессионной моделью. Во-первых, исходные данные могут не соответствовать тем или иным предпосылкам линейной регрессионной модели и требовать либо дополнительной обработки, либо иного модельного инструментария. Во-вторых, исследуемый процесс во многих случаях описывается не одним уравнением, а системой, где одни и те же переменные могут быть в одних случаях объясняющими, а в других - зависимыми. В-третьих, исследуемые взаимосвязи могут быть (и обычно являются) нелинейными, а процедура линеаризации не всегда легко осуществима и может приводить к искажениям. В-четвертых, структура описываемого процесса может обусловливать наличие различного рода связей между оцениваемыми коэффициентами регрессии, что также предполагает необходимость использования специальных методов.
Наиболее распространенным в практике статистического оценивания параметров уравнений регрессии является метод наименьших квадратов. Этот метод основан на ряде предпосылок относительно природы данных и результатов построения модели. Основные из них - это четкое разделение исходных переменных на зависимые и независимые, некоррелированность факторов, входящих в уравнения, линейность связи, отсутствие автокорреляции остатков, равенство их математических ожиданий нулю и постоянная дисперсия. Эмпирические данные не всегда обладают такими характеристиками, т.е. предпосылки МНК нарушаются. Применение этого метода в чистом виде может привести к таким нежелательным результатам, как смещение оцениваемых параметров, снижение их состоятельности, устойчивости, а в некоторых случаях может и вовсе не дать решения. Для смягчения нежелательных эффектов при построении регрессионных уравнений, повышения адекватности моделей существует ряд усовершенствований МНК, которые применяются для данных нестандартной природы.
Одной из основных гипотез МНК является предположение о равенстве дисперсий отклонений еi, т.е. их разброс вокруг среднего (нулевого) значения ряда должен быть величиной стабильной. Это свойство называется гомоскедастичностью. На практике дисперсии отклонений достаточно часто неодинаковы, то есть наблюдается гетероскедастичность. Это может быть следствием разных причин. Например, возможны ошибки в исходных данных. Случайные неточности в исходной информации, такие как ошибки в порядке чисел, могут оказать ощутимое влияние на результаты. Часто больший разброс отклонений єi, наблюдается при больших значениях зависимой переменной (переменных). Если в данных содержится значительная ошибка, то, естественно, большим будет и отклонение модельного значения, рассчитанного по ошибочным данным. Для того, чтобы избавиться от этой ошибки нам нужно уменьшить вклад этих данных в результаты расчетов, задать для них меньший вес, чем для всех остальных. Эта идея реализована во взвешенном МНК.
Пусть на первом этапе оценена линейная регрессионная модель с помощью обычного МНК. Предположим, что остатки еi независимы между собой, но имеют разные дисперсии (поскольку теоретические отклонения еi нельзя рассчитать, их обычно заменяют на фактические отклонения зависимой переменной от линии регрессии, для которых формулируются те же исходные требования, что и для єi). В этом случае квадратную матрицу ковариаций cov(ei, ej) можно представить в виде:
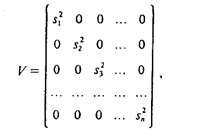
где cov(ei, ej)=0 при ij; cov(ei, ej)=S2; n - длина рассматриваемого временного ряда.
Если величины известны, то далее можно применить взвешенный МНК, используя в качестве весов величины и минимизируя сумму
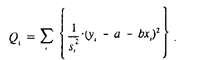
Формула Q, записана для парной регрессии; аналогичный вид она имеет и для множественной линейной регрессии. При использовании IVLS оценки параметров не только получаются несмещенными (они будут таковыми и для обычного МНК), но и более точными (имеют меньшую дисперсию), чем не взвешенные оценки.
Проблема заключается в том, чтобы оценить величины s2, поскольку заранее они обычно неизвестны. Поэтому, используя на первом этапе обычный МНК, нужно попробовать выяснить причину и характер различий дисперсий еi. Для экономических данных, например, величина средней ошибки может быть пропорциональна абсолютному значению независимой переменной. Это можно проверить статистически и включить в расчет МНК веса, равные.
Существуют специальные критерии и процедуры проверки равенства дисперсий отклонений. Например, можно рассмотреть частное от деления cуммсамых больших и самых маленьких квадратов отклонений, которое должно иметь распределение Фишера в случае гомоскедастичности.
Использование взвешенного метода в статистических пакетах, где предоставлена возможность задавать веса вручную, позволяет регулировать вклад тех или иных данных в результаты построения моделей. Это необходимо в тех случаях, когда мы априорно знаем о не типичности какой-то части информации, т.е. на зависимую переменную оказывали влияние факторы, заведомо не включаемые в модель. В качестве примера такой ситуации можно привести случаи стихийных бедствий, засух. При анализе макроэкономических показателей (ВНП и др.) данные за эти годы будут не совсем типичными. В такой ситуации нужно попытаться исключить влияние этой части информации заданием весов. В разных статистических пакетах приводится возможный набор весов. Обычно это числа от О до 100. По умолчанию все данные учитываются с единичными весами. При указании веса меньше 1 мы снижаем вклад этих данных, а если задать вес больше единицы, то вклад этой части информации увеличится. Путем задания весового вектора мы можем не только уменьшить влияние каких - либо лет из набора данных, но и вовсе исключить его из анализа. Итак, ключевым моментом при применении этого метода является выбор весов. В первом приближении веса могут устанавливаться пропорционально ошибкам не взвешенной регрессии. [1]
Date: 2015-06-11; view: 871; Нарушение авторских прав