Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Разработка алгоритма поиска пути
|
|
Вначале опишем процесс поиска оптимального пути на основе используемого интерфейса Google maps API. Для решения данной проблемы было рассмотрено 2 варианта алгоритмов. Первый из них это:
Общая задача коммивояжера (traveling salesmen problem, TSP состоит в следующем: используя заданную систему транспортных соединений (дорог и т.п.) между пунктами (городами, фирмами и т.п.) в конкретной зоне обслуживания, посетить все пункты в такой последовательности, чтобы пройденный путь был минимальным.
При этом в качестве маркера используется фермент, который тем концентрированный, чем больше муравьев прошли к цели неизвестен. В муравейник второй муравей пойдет к задаче коммивояжера.
Путь муравья – данная нам по условию задачи транспортная сеть. Исходный граф двунаправлен, значит, муравей может путешествовать вдоль грани в любом направлении.
Муравей – программный агент, который является членом большой в этом списке располагаются в порядке их посещения – позже этот список будет использован для определения длины пути. Фермент муравьи «оставляют» на пройденных ребрах графа.
Популяция. Перед началом движения муравьев случайным образом распределяют в популяции будет рассмотрена ниже, наряду со значениями остальных параметров.
Движение муравья (state transition rule). Направление движения муравья задается вероятностным уравнением. Формула устанавливает вероятность, с которой k-й муравей системы, находящийся в городе r, отправится в город s:
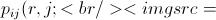
Бетта, параметр, контролирующий относительный приоритет фермента на пути в диапазоне [0...1], выбираемое каждый раз при пересчете формулы;

этот параметр, показывает относительную важность поиска новых маршрутк другому уровень фермента изменяется и длину пути каждого из муравьев. Повторный запуск осуществляется оговоренное число раз или до момента, когда на протяжении нескольких запусков не было отмечено изменений.
В целом алгоритм применительно к задаче коммивояжера можно сформулировать следующим образом:
Параметры существенно влияют на скорость нахождения качественного решения.
Параметр q0 отвечает за нахождение новых путей, a и p — за испарение фермента. Для задач небольшой размерности (n>100) используют значения q0=0,и качество решения. И времени работы алгоритм дает при соотношении, где m – численность муравьев; n – количество узлов.
Данный алгоритм не учитывает распределение нагрузки на участках, т.е. объёма перевозимого груза. Следовательно рассмотрим следующий алгоритм:
Поиск A* (произносится «А звезда» или «А стар», от англ. A star) — в информатике и математике, алгоритм поиска по первому наилучшему совпадению на графе, который находит маршрут с наименьшей стоимостью от одной вершины (начальной) к другой (целевой, конечной).
Порядок обхода вершин определяется эвристической функцией «расстояние + стоимость» (обычно обозначаемой как f(x)). Эта функция — сумма двух других: функции стоимости достижения рассматриваемой вершины (x) из начальной (обычно обозначается как g(x) и может быть как эвристической, так и нет) и эвристической оценкой расстояния от рассматриваемой вершины к конечной (обозначается как h(x)).
Функция h(x) должна быть допустимой эвристической оценкой, то есть не должна переоценивать расстояния к целевой вершине. Например, для задачи маршрутизации h(x) может представлять собой расстояние до цели по прямой линии, так как это физически наименьшее возможное расстояние между двумя точками.
Этот алгоритм был впервые описан в 1968 году Питером Хартом, Нильсом Нильсоном и Бертрамом Рафаэлем. Это по сути было расширение алгоритма Дейкстры, созданного в 1959 году. Он достигал более высокой производительности (по времени) с помощью эвристики. В их работе он упоминается как «алгоритм A». Но так как он вычисляет лучший маршрут для заданной эвристики, он был назван A*.
A* пошагово просматривает все пути, ведущие от начальной вершины в конечную, пока не найдёт минимальный. Как и все информированные алгоритмы поиска, он просматривает сначала те маршруты, которые «кажутся» ведущими к цели. От жадного алгоритма (который тоже является алгоритмом поиска по первому лучшему совпадению) его отличает то, что при выборе вершины он учитывает, помимо прочего, весь пройденный до неё путь (составляющая g(x) — это стоимость пути от начальной вершины, а не от предыдущей, как в жадном алгоритме). В начале работы просматриваются узлы, смежные с начальным; выбирается тот из них, который имеет минимальное значение f(x), после чего этот узел раскрывается. На каждом этапе алгоритм оперирует с множеством путей из начальной точки до всех ещё не раскрытых (листовых) вершин графа («множеством частных решений»), которое размещается в очереди с приоритетом. Приоритет пути определяется по значению f(x) = g(x) + h(x). Алгоритм продолжает свою работу до тех пор, пока значение f(x) целевой вершины не окажется меньшим, чем любое значение в очереди (либо пока всё дерево не будет просмотрено). Из множественных решений выбирается решение с наименьшей стоимостью.
Чем меньше эвристика h(x), тем больше приоритет (поэтому для реализации очереди можно использовать сортирующие деревья).
В рассматриваемом программном продукте данный алгоритм реализован следующим образом:
procedure SearchPath(x0, y0, x, y: Integer; PrintProc: TCurrentPoint);
type
pNode = ^TNode;
TNode = record
Parent: pNode;
Pos: TPoint;
Weight: Integer;
G: LongInt;
H, F: Extended;
end;
var
i, j, k: Integer;
OpenList, ClosedList: TList;
NewNode, Current: pNode;
FMin: Extended;
isClosed, isOpen, Complete: Boolean;
begin
OpenList:= TList.Create;
ClosedList:= TList.Create;
New(NewNode);
NewNode^.Parent:= nil;
NewNode^.Pos:= Point(x0, y0);
NewNode^.G:= 0;
NewNode^.H:= Sqrt(Sqr(x - x0) + Sqr(y - y0));
NewNode^.F:= NewNode^.G + NewNode^.H;
OpenList.Add(NewNode);
Complete:= False;
while (OpenList.Count > 0) and not Complete do
begin
FMin:= 77000;
Current:= nil;
for i:= 0 to OpenList.Count - 1 do
if pNode(OpenList[i])^.F < FMin then
begin
FMin:= pNode(OpenList[i])^.F;
Current:= pNode(OpenList[i]);
end;
ClosedList.Add(Current);
OpenList.Remove(Current);
for i:= Current^.Pos.X - 1 to Current^.Pos.X + 1 do
for j:= Current^.Pos.Y - 1 to Current^.Pos.Y + 1 do
begin
if (i = Current^.Pos.X) and (j = Current^.Pos.Y) then
Continue
else if not Complete then
Complete:= (i = x) and (j = y)
else
Break;
isClosed:= False;
for k:= ClosedList.Count - 1 downto 0 do //ищем в закрытом списке
if (pNode(ClosedList[k])^.Pos.X = i) and (pNode(ClosedList[k])^.Pos.Y = j) then
begin
isClosed:= True; //в закрытом списке
Break;
end;
if isClosed then
Continue;
isOpen:= False;
for k:= OpenList.Count - 1 downto 0 do //ищем в открытом списке
if (pNode(OpenList[k])^.Pos.X = i) and (pNode(OpenList[k])^.Pos.Y = j) then
begin
isOpen:= True; //в открытом списке
if pNode(OpenList[k])^.G > (Current^.G + pNode(OpenList[k])^.Weight) then
begin
pNode(OpenList[k])^.Parent:= Current;
pNode(OpenList[k])^.G:= Current^.G + pNode(OpenList[k])^.Weight;
pNode(OpenList[k])^.F:= pNode(OpenList[k])^.G + pNode(OpenList[k])^.H;
end;
Break;
end;
if not isOpen then //если еще не открыта
begin
//добавляем в открытый список
New(NewNode);
NewNode^.Parent:= Current;
NewNode^.Pos:= Point(i, j);
NewNode^.Weight:= Weights[i, j];
NewNode^.G:= Current^.G + NewNode^.Weight;
NewNode^.H:= Sqrt(Sqr(x - i) + Sqr(y - j));
NewNode^.F:= NewNode^.G + NewNode^.H;
OpenList.Add(NewNode);
end;
end;
end;
for i:= OpenList.Count - 1 downto 0 do
if (pNode(OpenList[i])^.Pos.X = x) and (pNode(OpenList[i])^.Pos.Y = y) then
begin
Current:= OpenList[i];
while Current <> nil do
begin
PrintProc(Current^.Pos.X, Current^.Pos.Y);
Current:= Current^.Parent;
end;
end;
for i:= OpenList.Count - 1 downto 0 do
Dispose(OpenList[i]);
OpenList.Free;
for i:= ClosedList.Count - 1 downto 0 do
Dispose(ClosedList[i]);
ClosedList.Free;
end;
Приведем пример работы алгоритма в графическом виде:

Как и алгоритм поиска в ширину, A* является полным в том смысле, что он всегда находит решение, если таковое существует.
Если эвристическая функция h допустима, то есть никогда не переоценивает действительную минимальную стоимость достижения цели, то A* сам является допустимым (или оптимальным), также при условии, что мы не отсекаем пройденные вершины. Если же мы это делаем, то для оптимальности алгоритма требуется, чтобы h(x) была ещё и монотонной, или преемственной эвристикой. Свойство монотонности означает, что если существуют пути A—B—C и A—C (не обязательно через B), то оценка стоимости пути от A до C должна быть меньше либо равна сумме оценок путей A—B и B—C. (Монотонность также известна как неравенство треугольника: одна сторона треугольника не может быть длиннее, чем сумма двух других сторон.) Математически, для всех путей x, y (где y — потомок x) выполняется:
g(x) + h(x) \le g(y) + h(y).
A* также оптимально эффективен для заданной эвристики h. Это значит, что любой другой алгоритм исследует не меньше узлов, чем A* (за исключением случаев, когда существует несколько частных решений с одинаковой эвристикой, точно соответствующей стоимости оптимального пути).
В то время как A* оптимален для «случайно» заданных графов, нет гарантии, что он сделает свою работу лучше, чем более простые, но и более информированные относительно проблемной области алгоритмы. Например, в неком лабиринте может потребоваться сначала идти по направлению от выхода, и только потом повернуть назад. В этом случае обследование вначале тех вершин, которые расположены ближе к выходу (по прямой дистанции), будет потерей времени.
Date: 2016-07-25; view: 1042; Нарушение авторских прав