Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Законы Зипфа и автоматизация извлечения метаданных из электронных изданий
|
|
Известный математик  Дж. Зипф (С. К. Zipf) показал, что все созданные человеком тексты подчиняются общим закономерностям, которые он сформулировал в 1946 г. в виде нескольких законов.
Дж. Зипф (С. К. Zipf) показал, что все созданные человеком тексты подчиняются общим закономерностям, которые он сформулировал в 1946 г. в виде нескольких законов.
Если взять любой текст, то можно подсчитать, какие слова в нем сколько раз встречаются. Количество повторов слова в тексте можно назвать частотой. Чаще всего встречающемуся слову можно приписать ранг 1, следующему по частоте - 2 и т. д. Если несколько разных слов имеют одинаковые частоты, то учитывается только одно из этих нескольких значений. Если разделить частоту повторения слова на общее количество значащих слов в тексте, то получим его относительную частоту или вероятность встречи этого слова в тексте. Первый закон Зипфа гласит, что произведение вероятности встречи слова в тексте на его частоту приблизительно постоянно для любых текстов определенного языка. Сказанное иллюстрируется рис. 7.3  , где представлена зависимость частоты встречи слова в тексте f от его ранга R.
, где представлена зависимость частоты встречи слова в тексте f от его ранга R.
Второй закон Зипфа определяет соотношение между частотой и количеством слов, которые с этой частотой встречаются в тексте. Если построить график зависимости количества слов и частоты, то окажется, что характеризующая ее кривая остается неизменной для любых текстов в пределах одного языка. Сказанное иллюстрируется да иным и рис. 7.4 , на котором показаны кривые для английского (самая нижняя), французского и русского языков (самая верхняя).
Данные рис. 7.3 могут успешно использоваться на практике для выделения значащих слов в тексте. Все значащие слова для данного текста размещаются в области средних значений ранга (область выделена на рис. 7.3 штриховкой). Действительно, самые часто встречающиеся слова обычно относятся к вспомогательным, а самые редко встречающиеся обычно также не имеют решающего смыслового значения для данного текста. От того, как будет задан диапазон значимых слов, зависит многое. Если сделать его слишком широким - нужные термины потонут в море вспомогательных слов, установив чрезмерно узкий диапазон мы рискуем потеряешь смысловые термины.
Если рассматривать совокупность изданий, в особенности, посвященных одной и той же тематике, то вероятность случайного попадания малозначащих слов в выделенную область для группы изданий (см. рис. 7.3 ) уменьшается. Чтобы учесть такую возможность избавиться от случайных слов вводят понятие инверсной частоты термина. Инверсная частота определяется как логарифм отношения общего количества рассматриваемых документов п кчислу документов, содержащих данный термин m (под термином может пониматься не только отдельное слово, но и единое по смыслу словосочетание), т. е.
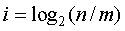 .
.
С учетом инверсной частоты вес или значимость термина в каждом документе определится как произведение
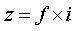 ,
,
где z - вес или значимость термина в издании; f - частота повторения термина в этом издании; i - инверсная частота этого термина в группе издании.
Процесс определения веса или значимости термина в издании легко алгоритмизируется. На этом принципе основана работа всех программ - экстракторов значащих слов. Надо сказать, что даже широко распространенный в нашей стране редактор Word, начиная с версии 1997 г., как-то выполняет функции извлечения терминов. Для этого используется команда «Реферат» в секции меню «Сервис». Соответствующее команде диалоговое окно показано на рис. 7.5 .
Как следует из данных рис. 7.5 , реферат можно поместить в начало реферируемого документа или оформить в виде отдельного файла. Можно также регулировать размер реферата, задавая в процентах от основного текста количество предложений в нем. В примере на рис. 7.5 в реферате содержатся два предложения, в то время как в исходном документе их было двадцать одно. Наряду с составлением реферата из текста документа извлекается пять наиболее значимых слов. Для их просмотра следует воспользоваться командой «Свойства» секции меню «Файл». Соответствующее диалоговое окно показано на рис. 7.6 .
Для того чтобы ключевые слова были занесены в нужное поле вкладки «Документ» окна «Свойства», в диалоговом окне, показанном на рис. 7.5 , должна быть задействована опция «Обновить сведения о документе»).
В поле «Ключевые слова» в примере отобрано пять слов, а именно: «в», «издательств», «области», «предусмотрен», «должен». Нетрудно за метить, что из пяти отобранных слов только одно соответствует тематике статьи «Современные издательства», причем одно из отобранных слов - предлог, который вообще не может иметь смысла, когда он берется отдельно от основного слова. Таким образом, качество отбора ключевых слов редактором Word 97 весьма низкое. Кстати, реферирование осуществляется только для работе названием на английском (а не на русском) языке. Надо сказать, что редактор Word 2000 ничем существенным не отличается от своего предшественника.
Date: 2015-05-22; view: 660; Нарушение авторских прав