Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Шаг 2. Выбор метода анализа данных
|
|
Перейти к выбору метода анализа можно несколькими способами: либо через пункт главного меню Анализ (рис. 1.5), либо нажав кнопку  в левом нижнем углу рабочей области STATISTICA, либо нажав кнопку, соответствующую конкретному методу, на Панели инструментов.
в левом нижнем углу рабочей области STATISTICA, либо нажав кнопку, соответствующую конкретному методу, на Панели инструментов.

Рис. 1.5. Выпадающее меню Анализ
После выбора строки с названием метода анализа появляется соответствующая ему стартовая панель.
Рассмотрим процесс формирования выборок в системе STATISTICA.
Создаем таблицу данных для 10 объектов, каждый из которых характеризуется 3-мя признаками x, y, z (рис. 1.6).

Рис. 1.6. Исходная выборка данных
Для проведения кластерного анализа методом K -средних на панели инструментов нажимаем на кнопку переключателя модулей STATISTICA Module Switcher (рис. 1.7).

Рис. 1.7. Переключатель модулей Module Switcher
В появившемся окне (рис. 1.8) выбираем модуль Cluster Analysis (Кластерный анализ), нажав кнопку Switch to (Переключиться в) или просто дважды щелкнув мышью по названию модуля Cluster Analysis.
На экране появится стартовая панель модуля (рис. 1.9) Clustering Method (методы кластерного анализа): Joining (tree clustering) (иерархические агломеративные методы или древовидная кластеризация), K-means clustering (метод K-средних), Two-way joining (двувходовое объединение).

Рис. 1.8. Окно Переключателя модулей Module Switcher

Рис. 1.9. Стартовая панель модуля Clustering Method
(Методы кластерного анализа)
Откроем файл с исходными данными (Open Data). Из стартовой панели модуля (рис. 1.9) Clustering Method (методы кластерного анализа) выберем K-means clustering (метод K - средних) (рис. 1.10).
После нажатия ОК появляется окно Cluster Analysis: K-means clustering (метод K - средних) (рис. 1.11), в котором кнопка Variables позволяет выбрать переменные, участвующие в классификации. Нажмем на Variables и выберем все переменные Select All.

Рис. 1.10. Стартовая панель модуля Clustering Method
(метод K-средних)
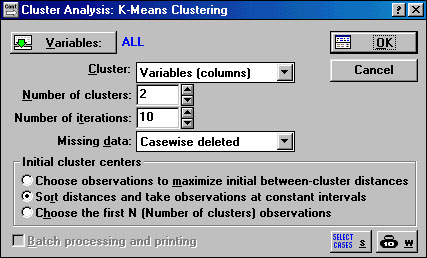
Рис. 1.11. Cluster Analysis: K - means clustering (метод К средних)
В строке Cluster указывается, как ведется классификация: при запуске установлен режим Variables (columns) – классифицируются переменные на основании их наблюдений, однако в подавляющем большинстве случаев используется режим Cases (rows) – классифицируются наблюдения. Для того чтобы включить режим Cases (rows) надо нажать на кнопку в конце строки, после чего в открывшемся окошке подвести курсор на надпись Cases (rows) и нажать левую кнопку.
В строке Number of iterations указывается количество итераций в расчетах кластеров. Как правило, установленных по умолчанию 10 итераций вполне достаточно. В строке Missing data устанавливается режим работы с теми наблюдениями (или переменными, если установлен режим Variables (columns) в строке Cluster) в которых пропущены данные. Если установить режим Substituted by means (Заменять на среднее), то вместо пропущенного числа будет использовано среднее по этой переменной (или наблюдению). Переключение в режим Substituted by means выполняется аналогично переключениям в строке Cluster. В качестве метода для начального определения центов кластеров выбираем: Sort distances and take observations at constant intervals (Отстоящие друг от друга на одинаковом расстоянии).
После соответствующего выбора нажимаем OK. Будут произведены вычисления, и появится новое окно: K-Means Clustering Results (рис. 1.12).
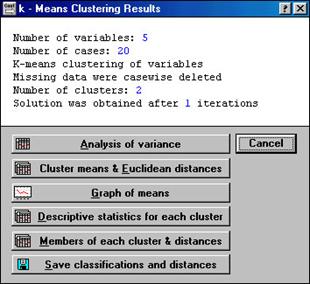
Рис. 1.12. K-Means Clustering Results
В верхней части окна (в том же порядке, как они идут на экране):
Number of variables – Количество переменных.
Number of cases – Количество наблюдений.
K-means clustering of variables – Классификация наблюдений (или переменных) методом K -средних (зависит от установки в предыдущем окне в строке Cluster).
Missing data were casewise deleted – Наблюдения с пропущенными данными удаляются (или заменяются средними значениями – зависит от установки в предыдущем окне в строке Missing data).
Number of clusters – Количество кластеров.
Solutions was obtained after k iterations – Решение достигнуто после k итераций.
В нижней части окна расположены кнопки для вывода различной информации по кластерам.
Date: 2015-11-15; view: 495; Нарушение авторских прав