Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Классификация Вычислительных Систем Флинна
|
|
Память
Память – один из блоков ЭВМ, состоящий из ЗУ и предназначенный для запоминания, хранения и выдачи информации (алгоритма обработки данных и самих данных).
Основными характеристиками отдельных устройств памяти (запоминающих устройств) являются емкость памяти, быстродействие и стоимость хранения единицы информации (бита).
Быстродействие (задержка) памяти определяется временем доступа и длительностью цикла памяти. Время доступа представляет собой промежуток времени между выдачей запроса на чтение и моментом поступления запрошенного слова из памяти. Длительность цикла памяти определяется минимальным временем между двумя последовательными обращениями к памяти.
Требования к увеличению емкости и быстродействия памяти, а также к снижению ее стоимости являются противоречивыми. Чем больше быстродействие, тем технически труднее достигается и дороже обходится увеличение емкости памяти. Стоимость памяти составляет значительную часть общей стоимости ЭВМ. Как и большинство устройств ЭВМ, память имеет иерархическую структуру. Обобщённая модель такой структуры, отражающая многообразие ЗУ и их взаимодействие, представлена на рисунке 8.1. Все запоминающие устройства обладают различным быстродействием и емкостью. Чем выше уровень иерархии, тем выше быстродействие соответствующей памяти, но меньше её емкость.
К самому высокому уровню - сверхоперативному - относятся регистры управляющих и операционных блоков процессора, сверхоперативная память, управляющая память, буферная память (кэш-память). На втором оперативном уровне, более низком, находится оперативная память (ОП), служащая для хранения активных программ и данных, то есть тех программ и данных, с которыми работает ЭВМ. На следующем более низком внешнем уровне размещается внешняя память.
Местная память или регистровая память процессора. Входит в состав ЦП (регистры управляющих и операционных блоков процессора) и предназначена для временного хранения информации. Она имеет малую ёмкость и наибольшее быстродействие. Построена на базе регистров общего назначения. РОН конструктивно совмещены с процессором ЭВМ. Этот тип ЗУ используется для хранения управляющих и служебных кодов, а также информации, к которой наиболее часто обращается процессор при выполнении программы.
Сверхоперативная память. Иногда в архитектуре ЭВМ регистровая память организуется в виде сверхоперативного ЗУ с прямой адресацией. Такая память имеет то же назначение как и РОН, служит для хранения операндов, данных и служебной информации, необходимой процессору.
Управляющая память предназначена для хранения управляющих микропрограмм процессора (см. раздел Устройство управления микропрограммного типа). Выполнена в виде постоянного ЗУ (ПЗУ) или программируемого постоянного ЗУ (ППЗУ). В системах с микропрограммным способом обработки информации УП применяется для хранения однажды записанных микропрограмм, управляющих программ, констант и т.п.
Буферная память. В функциональном отношении кэш-память рассматривается как буферное ЗУ, размещённое между основной (оперативной) памятью и процессором. Основное назначение кэш-памяти - кратковременное хранение и выдача активной информации процессору, что сокращает число обращений к основной памяти, скорость работы которой меньше, чем кэш-памяти. Кэш – память от английского cashe – тайник. Она не является программно доступной. Поэтому она оказывает влияние на производительность ЭВМ, но не влияет на программирование прикладных задач. В современных ЭВМ различают кэш первого и второго уровней. Кэш первого уровня интегрирована с блоком предварительной выборки команд и данных ЦП и служит, как правило, для хранения наиболее часто используемых команд. Кэш второго уровня служит буфером между ОП и процессором. В некоторых ЭВМ существует кэш память отдельно для команд и отдельно для данных.
ОП (ОЗУ) служит для хранения информации, непосредственно участвующей в вычислительном процессе (происходящем в операционном устройстве - АЛУ). Из ОЗУ в процессор поступают коды и операнды, над которыми производятся предусмотренные программой операции, из процессора в ОЗУ направляются для хранения промежуточные и конечные результаты обработки информации. ОЗУ имеет сравнительно большую ёмкость и высокое быстродействие, однако меньшее, чем ЗУ сверхоперативного уровня.
Внешняя память (ВнП) используется для хранения больших массивов информации в течении продолжительного времени. Обычно ВнП не имеет непосредственной связи с процессором. Обмен информацией носит групповой характер, что значительно сокращает время обмена. ВнП обладает сравнительно низким быстродействием (поиск информации). В качестве носителя используются магнитные диски (гибкие и жёсткие), лазерные диски(CD-room) и др.
2. Архитектура фон Неймана
Свойства и принципы работы машины фон Неймана.
• Линейное пространство памяти. Для оперативного хранения информации компьютер имеет совокупность ячеек с последовательной нумерацией (адресами) 0, 1, 2,… Данная совокупность ячеек называется оперативной памятью.
• Принцип хранимой программы. Согласно этому принципу, код программы и ее данные находятся в одном и том же адресном пространстве оперативной памяти.
• Принцип микропрограммирования. Суть этого принципа заключается в том, что машинный язык еще не является той конечной субстанцией, которая физически приводит в действие процессы в машине. В состав процессора (см. главу 1) входит устройство микропрограммного управления, поддерживающее набор действий-сигналов, которые нужно сгенерировать для физического выполнения каждой машинной команды.
• Последовательное выполнение программ. Процессор выбирает из памяти команды строго последовательно. Для изменения прямолинейного хода выполнения программы или осуществления ветвления необходимо использовать специальные команды. Они называются командами условного и безусловного переходов.
• Отсутствие разницы между данными и командами в памяти. С точки зрения процессора, нет принципиальной разницы между данными и командами. Данные и машинные команды находятся в одном пространстве памяти в виде последовательности нулей и единиц. Это свойство связано с предыдущим. Процессор, поочередно обрабатывая некоторые ячейки памяти, всегда пытается трактовать содержимое ячеек как коды машинных команд, а если это не так, то происходит аварийное завершение программы. Поэтому важно всегда четко разделять в программе пространства данных и команд.
• Безразличие к назначению данных. Машине все равно, какую логическую нагрузку несут обрабатываемые ею данные.
3. Гарвардская архитектура
В гарвардской архитектуре принципиально невозможно осуществить операцию записи в память программ, что исключает возможность случайного разрушения управляющей программы в случае ошибки программы при работе с данными или атаки третьих лиц. Кроме того, для работы с памятью программ и с памятью данных организуются отдельные шины обмена данными (системные шины), как это показано на рисунке 1.
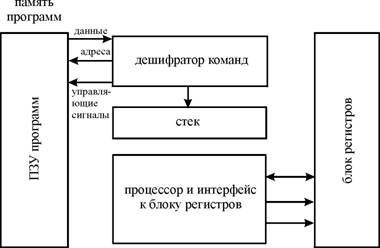
Рисунок 1. Структурная схема гарвардской архитектуры
Эти особенности определили области применения гарвардской архитектуры. Гарвардская архитектура применяется в микроконтролерах и в сигнальных процессорах, где требуется обеспечить высокую надёжность работы аппаратуры. В сигнальных процессорах Гарвардская архитектура дополняется применением трехшинного операционного блока микропроцессора. Трехшинная архитектура операционного блока позволяет совместить операции считывания двух операндов с записью результата выполнения команды в оперативную память микропроцессора. Это значительно увеличивает производительность сигнального микропроцессора без увеличения его тактовой частоты.
В Гарвардской архитектуре характеристики устройств памяти программ и памяти данных не всегда выполняются одинаковыми. В памяти данных и команд могут различаться разрядность шины данных и распределение адресов памяти. Часто адресные пространства памяти программ и памяти данных выполняют различными. Это приводит к различию разрядности шины адреса для этих видов памяти. В микроконтроллерах память программ обычно реализуется в виде постоянного запоминающего устройства, а память данных — в виде ОЗУ. В сигнальных процессорах память программ вынуждены выполнять в виде ОЗУ. Это связано с более высоким быстродействием оперативного запоминающего устройства, однако при этом в процессе работы осуществляется защита от записи в эту область памяти.
Применение двух системных шин для обращения к памяти программ и памяти данных в гарвадской архитектуре имеет два недостатка — высокую стоимость и большое количество внешних выводов микропроцессора. При использованиии двух шин для передачи команд и данных, микропроцессор должен иметь почти вдвое больше выводов, так как шина адреса и шина данных составляют основную часть выводов микропроцессора. Для уменьшения количества выводов кристалла микропроцессора фирмы-производители микросхем объединили шины данных и шины адреса для внешней памяти данных и программ, оставив только различные сигналы управления (WR, RD, IRQ) а внутри микропроцессора сохранили классическую гарвардскую архитектуру. Такое решение получило название модифицированная гарвардская архитектура.
Модифицированная гарвардская структура применяется в современных микросхемах сигнальных процессоров. Ещё дальше по пути уменьшения стоимости кристалла за счет уменьшения площади, занимаемой системными шинами пошли производители однокристалльных ЭВМ — микроконтроллеров. В этих микросхемах применяется одна системная шина для передачи команд и данных (модифицированная гарвардская архитектура) и внутри кристалла.
4. Архитектуры RISC и CISC
Аббревиатура RISC (reduced instruction set computer) появилась в середине 80-х годов XX века, когда ученые из Беркли сообщили о создании "компьютера с ограниченным набором команд". С тех пор остальные компьютеры стали называться CISC (complication instruction set computer – компьютеры со сложным (расширенным) набором команд.)
RISC – архитектура процессора, в котором быстродействие увеличивается за счёт упрощения инструкций, чтобы их декодирование было более простым, а время выполнения — меньшим.
RISC-процессоры характеризуются следующими особенностями:
- Из них удалены сложные (типа двоичного умножения) и редко используемые инструкции.
- Все инструкции имеют одну длину. При этом уменьшается сложность устройства управления процессора и увеличивается скорость дешифрации команд.
- Отсутствуют инструкции, работающие с памятью напрямую (типа команд "память - память", "регистр - память"). Возможна только загрузка данных из памяти в регистр и наоборот, из регистра в память. Соответственно на порядок увеличивается число регистров.
- Отсутствуют операции работы со стеком.
- Возможно использования конвейера и параллельных вычислений. АЛУ, например, одновременно может работать с 2-мя 32-х разрядными, 4-мя 16-ти разрядными, и 8-мью 8-ми разрядными числами. Смысл же конвейера – в накоплении последовательно выполняемых команд программы (т.н. линейных участков) в буфере для их ускоренного дешифрования и выполнения.
- Почти все операции осуществляются за один такт микропроцессора.
- Благодаря этим нововведениям тактовая частота RISC-процессоров (при прочих равных условиях) выше.
CISC – концепция проектирования процессоров, которая характеризируется нефиксированным значением длины команды, арифметическим действием, небольшим числом регистров.
Характеризуется:
· большим числом различных по формату и длине команд;
· введением большого числа различных режимов адресации;
· обладает сложной кодировкой инструкции.
Процессору с архитектурой CISC приходится иметь дело с более сложными инструкциями неодинаковой длины. Выполнение одиночной CISC-инструкции может происходить быстрее, однако обрабатывать несколько таких инструкций параллельно сложнее.
5. Систематика Флинна
Одним из наиболее распространенных способов классификации ЭВМ является систематика Флинна (Flynn), в рамках которой основное внимание при анализе архитектуры вычислительных систем уделяется способам взаимодействия последовательностей (потоков) выполняемых команд и обрабатываемых данных. Схематично класси- фикация Флинна показана на рисунке 2.1. При этом количество потоков команд и количество данных для каждого потока является классификационным признаком.
Классификация Вычислительных Систем Флинна
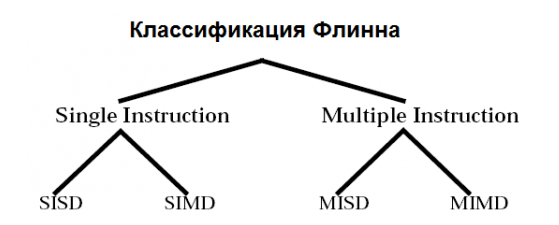
Рассмотрим каждый из видов вычислительных систем, получающихся по классификации Флинна, более подробно.
SISD (Single Instruction, Single Data) – системы, в которых существует одиночный поток команд и одиночный поток данных. К данному типу систем можно отнести обычные последовательные компьютеры.
SIMD (Single Instruction, Multiple Data) – системы c одиночным потоком команд и множественным потоком данных. SIMD компьютеры состоят из одного командного процессора (управляющего модуля), называемого контроллером, и нескольких модулей обработки данных, называемых процессорными элементами. В каждый момент времени может выполняться одна и та же команда для обработки нескольких информационных элементов. Управляющий модуль принимает, анализирует и выполняет команды. Если в команде встречаются данные, контроллер рассылает на все процессорные элементы команду, и эта команда выполняется на нескольких или на всех процессорных элементах. Каждый процессорный элемент имеет свою собственную память для хранения данных. Одним из преимуществ данной архитектуры считается то, что в этом случае более эффективно реализована логика вычислений. До половины логических инструкций обычного процессора связано с управлением выполнением машинных команд, а остальная их часть относится к работе с внутренней памятью процессора и выполнению арифметических операций.
MISD (Multiple Instruction, Single Data) – системы, в которых существует множественный поток команд и одиночный поток данных. Вычислительных машин такого класса практически нет и трудно привести пример их успешной реализации. Один из немногих - систолический массив процессоров, в котором процессоры находятся в узлах регулярной решетки, роль ребер которой играют межпроцессорные соединения. Все процессорные элементы управляются общим тактовым генератором. В каждом цикле работы каждый процессорный элемент получает данные от своих соседей, выполняет одну команду и передает результат соседям.
MIMD (Multiple Instruction, Multiple Data) – системы с множественным потоком команд и множественным потоком данных. К подобному классу систем относится большинство параллельных многопроцессорных высокопроизводительных вычислительных систем, являющихся предметом рассмотрения настоящего учебного пособия.
6. SMP-архитектура и MPP-архитектура
SMP (symmetric multiprocessing) – симметричная многопроцессорная архитектура. Главной особенностью систем с архитектурой SMP является наличие общей физической памяти, разделяемой всеми процессорами.
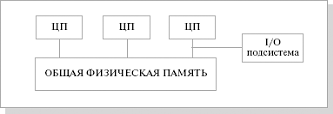
Память служит, в частности, для передачи сообщений между процессорами, при этом все вычислительные устройства при обращении к ней имеют равные права и одну и ту же адресацию для всех ячеек памяти. Поэтому SMP-архитектура называется симметричной. Последнее обстоятельство позволяет очень эффективно обмениваться данными с другими вычислительными устройствами. аиболее известными SMP-системами являются SMP-cерверы и рабочие станции на базе процессоров Intel (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.) Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT).
Основные преимущества SMP-систем:
- простота и универсальность для программирования. Архитектура SMP не накладывает ограничений на модель программирования, используемую при создании приложения: обычно используется модель параллельных ветвей, когда все процессоры работают независимо друг от друга. Однако можно реализовать и модели, использующие межпроцессорный обмен. Использование общей памяти увеличивает скорость такого обмена, пользователь также имеет доступ сразу ко всему объему памяти. Для SMP-систем существуют довольно эффективные средства автоматического распараллеливания;
- простота эксплуатации. Как правило, SMP-системы используют систему кондиционирования, основанную на воздушном охлаждении, что облегчает их техническое обслуживание;
- относительно невысокая цена.
Недостатки:
- системы с общей памятью плохо масштабируются.
Date: 2015-07-27; view: 1769; Нарушение авторских прав