Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
О комплексной диагностике сетей
|
|
О комплексной диагностике сетей
Saemon A., Компьютерная газета
Любопытнейший семинар проводили 27 марта в городе Минске компании ProLAN (Россия) и IBA (Беларусь). В течение 8 часов слушатели — системные и сетевые администраторы крупных белорусских компаний — знакомились с различными аспектами, методиками, технологиями и продуктами для диагностики компьютерных сетей.
Казалось бы, тема избитая и ничего нового в этой области уже невозможно себе представить, ан не тут-то было: компания ProLAN вышла на российский (а теперь, по видимому, и на белорусский) рынок с чрезвычайно интересной разработкой: технологией SLа-ON, представляющей собой набор диагностических средств и методику их использования, которые позволяют, во-первых, дать объективную оценку качества работы прикладных программ в сети и, во-вторых, дать аргументированные рекомендации, что надо сделать, чтобы улучшить их работу. По сути технология решает три весьма актуальные задачи:
• реализация "Соглашения об уровне обслуживания" (SLA, Service Level Agreement) на прикладное ПО, и объективная оценка быстродействия прикладных программ;
• контроль быстродействия прикладных программ в процессе их эксплуатации;
• определение зависимости быстродействия прикладных программ от характеристик работы всех компонент сети.
Попробую очешь сжато, буквально "на пальцах" объяснить в чем суть технологии.
Итак, у нас есть некий "генератор транзакций". Не пугайтесь термина: простейшим примером оного является любое наше пользовательское ПО:) Для успешной работы SLa-ON наш генератор транзакций должен принадлежать к одному из нижеуказанных типов:
1. реальное пользовательское приложение, изначально написанное с поддержкой SLa-ON API;
2. программы-роботы, циклично выполняющие некое определенное действие, за продуктивностью выполнения которого мы хотим проследить;
3. тестовые приложения (почти то же самое, что и роботы).
Через API генераторы транзакций взаимодействуют с так называемым SLa-ON-агентами, в задачу которых входит сбор информации от приложения о времени прохождения той или иной интересующей нас транзакции. На семинаре показывали пример с программой-роботом, с помощью специального скрипта настроенного таким образом, чтобы передавать агенту время, затраченное, например, на загрузку приложения с сервера.
Агент может поступать с полученными данными следующим образом: записывать их на диск, автоматически передавать в центральную БД или выдавать визуальную реакцию в виде светофора (зеленый — хорошо, желтый — не очень-то, красный — откровенно плохо, и промежуточные "мигающие" значения). Информацию о том, что такое хорошо и что такое плохо применительно к данной конкретной транзакции агент получает из так называемого профайла. Профайл представляет собой текстовый файл, составленный по принципу INI-файлов Windows и содержащий некий набор условий, на основании которых зажигается тот или иной свет на "светофоре". Проведя долговременное тестирование на "безглючной" — то бишь бездефектной — сети или системе вы можете сами создать профайл.
Но светофор — это дело десятое: не будет же наш юзер (а уж тем более — робот) с утра до ночи пялиться на мигающие лампочки. Ну допустим, горит она у него все время красным, то бишь плохи дела совсем. Что делать? Берем показатели, скинутые агентом в локальный файл или базу данных, добавляем к ним другие результаты замеров "поведения" системы в целом — информацию от SNMP-агентов, сетевых анализаторов и систем управления (скажем, Observer, HP Open View, снифферов там всяких, статистику от Apache и др.) — и закидываем все это дело в единую базу данных. Отображаем (внимание!) в единой временной шкале. И возможно уже при поверхностном осмотре невооруженным глазом обнаруживаем, что неудовлетворительное время прохождения той или иной транзакции прямо связано с неким измеренным нами параметром — загрузкой процессора на сервере или клиенте, скачками утилизации сети или чем-то еще. Если проблема не столь очевидна, нам может потребоваться анализ тучи таких разношерстных данных, для чего вместо глаз своих используем соотвествующее ПО, осуществляющее вероятностный, корреляционный и регрессионный анализ.
Вообще корреляционный анализ — будь он поверхностно-визуальный (смотрим на графики и делаем выводы) или автоматический (получаем коэффициенты корреляции различных величин) — центральная идея ProLAN'овского взгляда на диагностику систем. И это естественно и разумно. Как верно замечено в "девизе" интегрального взгляда на сеть от ProLAN "Сеть — это сложная система, в состав которой входит множество компонент: кабельная система, активное оборудование, сетевая операционная система и многое другое. Концепция "сквозной" диагностики сети предполагает умение эффективно, т.е. с минимальными затратами времени и денег, оценить, как работают все компоненты сети с учетом их взаимосвязей."
Беда значительного числа как администраторов, так и некоторых начальников — вечная гонка за более мощным оборудованием, при том что значительная часть бед сети кроется вовсе не в исчерпании существующим своего лимита, а проблемами взаимодействия аппаратуры, безграмотного конфигурирования, неправильной организации сети и работы пользователей. И беда номер 2 — зашоренность администраторов, зацикленность на одной-двух любимых методиках диагностики и мониторинга и полное игнорирование других. Кто-то помешан на SNMP и думает, что корректная работа устройств и сетевых тракотов, показываемая на консоли SNMP == истина в последней инстанции. Кто-то с утра до вечера в лупу пакеты в сниффере разглядывает и поднять голову до уровня сети в целом ему на ум не приходит. Кто-то вообще кроме ping'а ни черта не умеет...;(
Суть проводимого ProLAN семинара как раз и состояла не столько в ознакомлении с конкретными продуктами, сколько во вдалбливании в умы администраторов пресловутого "системного подхода". Позволю себе небольшую выдрежку из описания методики, сформулированной ProLAN как "Методика Сквозной Диагностики", описывающую поэтапность диагностики сети и инструментарий, рекомендуемый компанией для использования на каждом этапе.
‰ "На первом этапе производится диагностика кабельной системы сети с помощью кабельных сканеров. При этом выявляются ошибки физического уровня сети, которые программными средствами диагностики не обнаруживаются. Кабельное сканирование обязательно нужно проводить в первую очередь, так как для правильной интерпретации результатов дальнейшего тестирования мы должны быть уверены в том, что на физическом уровне в сети ошибок нет!
‰ На следующем этапе мы рекомендуем проводить диагностику рабочих станций сети путем стрессового тестирования сети с использованием пакета FTest 3.x в двух режимах. В режиме калибровки с нагрузкой только на сеть Вы можете достаточно легко выявить неоптимальные или просто дефектные драйверы и сетевые адаптеры на рабочих станциях. В режиме "Все станции" с нагрузкой только на сеть Вы можете выявить те дефекты станций, которые проявляются в результате взаимного влияния станций друг на друга. Заметим, что уже на этом этапе могут быть выявлены некоторые "узкие места" на сервере и в каналах связи.
‰ На следующем этапе следует провести диагностику каналов связи и серверов. Для этого мы рекомендуем использовать пакеты FTrend 1.х, Observer 7.0 с установленным расширением SNMP Extension for Observer, а также анализаторы серверов (Performance Monitor для NT-серверов, Monitor для серверов NetWare и др.). Пакет FTrend используется для мониторинга скоростных характеристик сети в выбранных трактах. Анализатор протоколов Observer используется для мониторинга характеристик сетевого трафика. SNMP Extension for Observer используется для мониторинга сетевого трафика на основе информации от SNMP-агентов на активном сетевом оборудовании, а также для мониторинга значений счетчиков сервера, используя SNMP-агенты на серверах. Для мониторинга характеристик сервера целесообразно также использовать Performance Monitor, Monitor и другие анализаторы серверов. Путем совместной обработки и анализа полученных в процессе тестирования скоростных характеристик, трендов характеристик сетевого трафика и счетчиков серверов Вы можете выяснить причину неправильного функционирования того или иного канала связи или сервера.
‰ После того, как Вы убедитесь в том, что все остальные сетевые компоненты функционируют нормально, Вы можете приступать к заключительному этапу сквозной диагностики сети — к диагностике прикладного сетевого программного обеспечения. На этом этапе мы рекомендуем вам воспользоваться нашей технологией SLa-ON"
На протяжении первой, теоретической части семинара народ сидел притихший, загруженный, и весь из себя непонятный, по поводу чего лектор во время кофе-брэйка заметил, что совсем чувствует эту аудиторию. "Они вообще понимают о чем речь?". Аудитория жаждала подкрепления теории практикой, и на вопрос, чему уделить большее внимание во второй части мероприятия все хором загудели — практике!
Практическая часть удалась: были произведены некоторые "живые" эксперименты на демонстрационном стенде и "разобраны" наиболее примечательные примеры из реальной трудовой жизни работников ProLAN. Не удержусь от пары наиболее иллюстративных примеров.
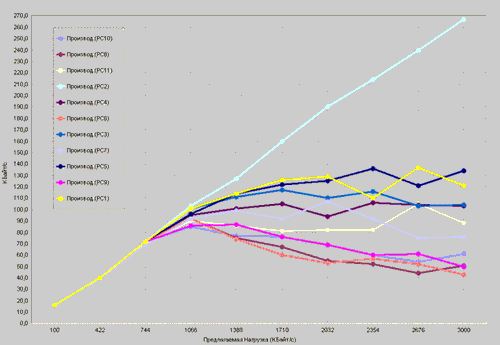
1. Пользователи некой организации жаловались что временами скорость работы в сети резко снижается сразу на нескольких рабочих станциях (в рамках одного домена коллизий). Поскольку карточки сетевые на всех рабочих станциях были... так себе карточки, администратор, не мудрствуя лукаво, заменил сетевые адапторы на нескольких первых попавшихся под руку станциях. Никакого результата. Что делает опытный специалист: производит исследование рабочих станций методом стрессового тестирования. В рамках данного примера использовался пакет FTest производства ProLAN. Пакет "умеет" три основых видов тестирования (просчитывается скорость работы на файловых операциях) — калибровка (все станци по очереди работают с сервером. остальные молчат), all stations (работают все, активность операций плавно повышается) и by steps (станции по одной подключаются к общему "разговору"). Калибровка, актуальная для вылавливания наиболее примитивных глюков и проблем, никакого результата не дала. А вот на режиме "все станции" стало очевидно, что при повышении нагрузки одна станция начинает "зажирать" всю полосу пропускания, "тянуть одеяло на себя", постоянно с ходом увеличения нагрузки получая желаемую скорость и постепенно вытесняя их общего канала конкурентов. Всего-то и осталось — выявить "нахалку" методом постепенного подключения станций (Рис. 1.).
2. Периодически в исследуемой сети наблюдались замедления в работе прикладных программ. Новый администратор сети, который устроился на работу недавно, быстро поставил диагноз и сразу назначил лечение. "Причина замедления в работе прикладных программ заключается в перегрузке канала связи сети. Чтобы программы работали быстрее, все концентраторы необходимо заменить на коммутаторы." Сеть и вправду была ни к черту — 70 рабочих станций и 4 сервера в одном коллизионном домене Ethernet (10 мегабит).
Чтобы подтвердить или опровергнуть диагноз администратора сети, было принято решение воспользоваться программой FTrend. Использование именно программы FTrend объясняется следующими причинами. Замедление в работе прикладных программ происходит в непредсказуемые моменты времени. Наблюдать же за работой сети и сервера постоянно и дожидаться поступления жалоб от пользователей сети, чтобы в этот момент посмотреть характеристики сети и сервера, не представляется возможным. Поэтому необходим некий инструмент, который, не требуя вмешательства администратора сети, собирает информацию о работе сети, достаточную для того, чтобы на ее основе сделать вывод о причинах медленной работы прикладных программ.
Исследование сети проводилось следующим образом. Во-первых, пользователей сети попросили отмечать время (с точностью до получаса), когда, с их точки зрения, прикладные программы работали медленно. Во-вторых, на двух компьютерах сети были запущены агенты FTrend. Агенты производили генерацию трафика в сеть, выполняя файловые операции с сервером. Чтобы не мешать работе пользователей сети, операции выполнялись с очень низкой интенсивностью. Смысл исследования сводился к следующему. Два Агента, находящиеся в одном коллизионном домене (т.е. в одинаковых условиях), одновременно и синхронно измеряют скорость выполнения сетевых операций. При этом один Агент работает с одним сервером, а другой — с другим. Поскольку тестовый сервер у каждого Агента свой, а канал связи общий, то можно предположить следующее.
Если оба Агента будут синхронно снижать свою скорость, то причина снижения скорости в сети. Если при этом пользователи сети отмечают медленную работу прикладных программ, значит причина медленной работы прикладных программ в сети. Если только какой-то один Агент будет снижать свою скорость, значит причина именно в этом сервере. Если, при этом, пользователи сети отмечают медленную работу прикладных программ, значит причина медленной работы прикладных программ в сервере. Если же пользователи отмечают медленную работу прикладных программ в те периоды времени, когда сеть и сервер работают быстро, значит причину замедления работы прикладных программ следует искать в самих прикладных программах (как это иногда бывает).
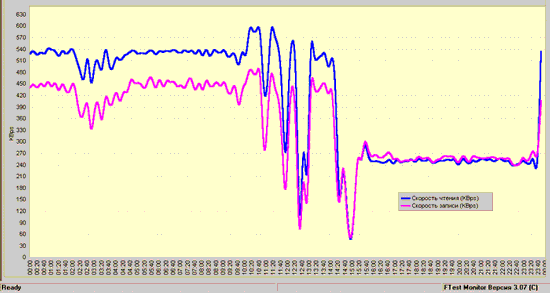
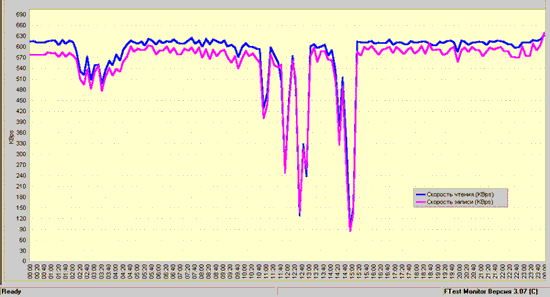 Сказано — сделано. В результате получились графики, изображенные на рисунках 2 и 3. Итак, что мы видим? А видим мы четкую закономерность. До 16 часов оба Агента практически синхронно снижают скорость выполнения файловых операций. В этот период времени несколько пользователей отметили некоторое замедление в работе прикладных программ. В соответствии с приведенными выше рассуждениями из этого можно сделать вывод, что до 16 часов именно загрузка канала связи сети оказывала наибольшее влияние на работу пользователей. Однако приблизительно в 16.20 поведение сети изменилось. В то время, как Агент 2 резко снизил свою скорость, скорость работы Агента 1 практически не изменилась. Именно в этот период времени большинство пользователей отметили замедление работы прикладных программ. Очевидно, что причину этого замедления следует искать в сервере № 2. И действительно, как позднее выяснилось, после 16 часов на втором сервере была активизирована программа, которая заняла большую часть ресурсов сервера, вызвав тем самым замедление в работе прикладных программ.
Сказано — сделано. В результате получились графики, изображенные на рисунках 2 и 3. Итак, что мы видим? А видим мы четкую закономерность. До 16 часов оба Агента практически синхронно снижают скорость выполнения файловых операций. В этот период времени несколько пользователей отметили некоторое замедление в работе прикладных программ. В соответствии с приведенными выше рассуждениями из этого можно сделать вывод, что до 16 часов именно загрузка канала связи сети оказывала наибольшее влияние на работу пользователей. Однако приблизительно в 16.20 поведение сети изменилось. В то время, как Агент 2 резко снизил свою скорость, скорость работы Агента 1 практически не изменилась. Именно в этот период времени большинство пользователей отметили замедление работы прикладных программ. Очевидно, что причину этого замедления следует искать в сервере № 2. И действительно, как позднее выяснилось, после 16 часов на втором сервере была активизирована программа, которая заняла большую часть ресурсов сервера, вызвав тем самым замедление в работе прикладных программ.
Это еще повезло, что проблема со вторым сервером оказалась столь тривиальна. В более тяжелом случае нам пришлось бы сделать что? Правильно, наложить на этот же график другие данные, например, показатели Performance Monitor'а на сервере
 Кстати о Performance Monitore... Был на семинаре чрезвычайно забавный пример, который, правда, я не могу привести для вас "во всей красе" по причине отсутствия иллюстрации к нему. Но суть в чем: исследуя ситуацию на одной рабочей станции было замечено, что скорость операций записи на сервер ведет себя вполне нормально (ну есть определенные проблемы, но они вполне понятного свойства), а вот график операций записи ведет себя курьезно. По форме он напоминает крышу средневековой башни — ---|__|---|__|--- — ну и так далее:) То бишь в некотороые моменты времени скорость операций записи катастрофически падает, что никак не коррелирует со скоростью операций чтения. Собрав за некоторый промежуток времени данные от Performance Monitor'а (на сервере), накладываем графики поведения десятка-другого параметров (видили как их там много всяких? ну скажите честно — больше штук 5 редко используете, а сколько их там всего и вовсе не знаете;))...так вот накладываем все это на общий график в единой временной шкале и видим, что один из графиков — почти брат близнец нашей "зигзаги", только в зеркальном отображении: __|----|__|----|__. Угадайте кто это был? Счетчик скорости дисковых операций на сервере (запись, разумеется). То есть проблема была не в сети и не в рабочей станции, проблема была в сервере.
Кстати о Performance Monitore... Был на семинаре чрезвычайно забавный пример, который, правда, я не могу привести для вас "во всей красе" по причине отсутствия иллюстрации к нему. Но суть в чем: исследуя ситуацию на одной рабочей станции было замечено, что скорость операций записи на сервер ведет себя вполне нормально (ну есть определенные проблемы, но они вполне понятного свойства), а вот график операций записи ведет себя курьезно. По форме он напоминает крышу средневековой башни — ---|__|---|__|--- — ну и так далее:) То бишь в некотороые моменты времени скорость операций записи катастрофически падает, что никак не коррелирует со скоростью операций чтения. Собрав за некоторый промежуток времени данные от Performance Monitor'а (на сервере), накладываем графики поведения десятка-другого параметров (видили как их там много всяких? ну скажите честно — больше штук 5 редко используете, а сколько их там всего и вовсе не знаете;))...так вот накладываем все это на общий график в единой временной шкале и видим, что один из графиков — почти брат близнец нашей "зигзаги", только в зеркальном отображении: __|----|__|----|__. Угадайте кто это был? Счетчик скорости дисковых операций на сервере (запись, разумеется). То есть проблема была не в сети и не в рабочей станции, проблема была в сервере.
И вот тут начался на семинаре цирк;)) Один из слушателей, не вникнув в то, что один зигзагобрразный график иллюстрирует замеры на рабочей станции, а другой — на сервере, минут 10 пытался доказать, что одно мол из другого прямо вытекает и ничего особенного в вашем "открытии" нет. Другого живо интересовало, что именно за беда случилась на сервере. Ну с первым вопросом все понятно — человек либо невнимательно слушал именно этот пример, либо вообще ни черта не понял из излагавшегося на семинаре;) А вот второй вопрос — философский и на него мне бы хотелось обратить ваше, господа, внимание. Вот говорит дядька "Что же эта у вас за технология, и что же вы за специалисты по диагностике, если не можете ответить, что именно случилось с сервером?". Лектор говорит, что, мол, ну не важно, что с ним случилось, может все пользователи в эти моменты начинали как не в себя записывать данные в некую базу данных, но ничего оттуда не читали. Суть же примера не в конкретике такого сорта, а в том, как проблема была локализована, благодаря чему отпали подозрения в перегрузке сети, некорректной работе железа и софта на клиенте. Но дядька не унимался и дискуссия затянулась. Мне по ходу вспомнилась прекрасная басня, которую (извините за offtopic) мне хочется привести в качестве иллюстрации. Стоит проповедник, рассказывает притчу: "Жил был старик и было у него два сына...", на что один из слушателей, перебивая, вопрошает: "А как их звали?". Проповедник: "Ну не важно как их звали, не знаю я.... не в этом суть...". "Как не знаешь???" — удивляются мужики. "Ну пусть их звали Вася и Петя. Так вот...". Мужики возмущаются: "Ну вот, а говорил, что не знаешь...".
Так вот, господа администраторы, задача эксперта по диагностике (и используемого им софта) — локализовать проблему (умозрительно или с помощью воспроизведения в ходе эксперимента), что уже — 99% ее решения. Снифферы, анализаторы и тестеры не будут приносить вам кофе в постель! И чинить винчестер на сервере или управлять вашими пользователями они тоже не будут! Это — ваша работа, и никто ее за вас делать не будет. Поэтому эксперт и не помнит, что случилось с тем сервером — это не его задача и не его головная боль. Аналогично софты. Даже самые умные и продвинутые — они лишь инструмент, а уж ваша проблема, как ими распорядиться, какую задачу перед ними поставить и как потом воспользоваться результатами их труда.
Date: 2015-07-23; view: 393; Нарушение авторских прав