Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Дисципліни заміщення сегментів. Організація, переваги і недоліки
|
|
Сегментний спосіб організації віртуальної пам'яті
Першим серед розривних методів розподілу пам'яті був сегментний. Для цього методу програму необхідно розбивати на частині і вже кожній такій частині виділяти фізичну пам'ять. Природним способом розбивки програми на частині є розбивка її на логічні елементи — так називані сегменти. Кожен сегмент розміщується в пам'яті як самостійна одиниця.
Логічно звертання до елементів програми в цьому випадку буде представлятися як вказівка імені сегмента і зсуву відносно початку цього сегменту. Фізично ім'я (або порядковий номер) сегменту буде відповідати деякій адресі, з якого цей сегмент починається при його розміщенні в пам’яті, і зсув повинний додаватися до цієї базової адреси.
Кожен сегмент, розташований у пам'яті, має відповідну інформаційну структуру, часто називану дескриптором сегмента. Саме операційна система будує для кожного процесу, що виконується, відповідну таблицю дескрипторів сегментів і при розміщенні кожного з сегментів в оперативній чи зовнішній пам'яті
в дескрипторі відзначає його поточне місцезнаходження.
Отже, якщо необхідного сегмента в оперативній пам'яті немає, то виникає переривання і керування передається через диспетчер пам'яті програмі завантаження сегмента. Поки відбувається пошук сегмента в зовнішній пам'яті і завантаження його в оперативну, диспетчер пам'яті визначає придатне для сегмента місце.
Якщо вільного місця немає, то приймається рішення про вивантаження якого-небудь сегмента і його переміщення в зовнішню пам'ять.
Для рішення проблеми заміщення (визначення того сегмента, який повинний бути або переміщений у зовнішню пам'ять, або просто заміщений новим) використовуються наступні дисципліни (їх наз. дисциплінами заміщення):
правило FIFO (first in — first out: «перший прийшов першим і вибуває»);
правило LRU (1еаst recently used: «довше всього невикористовуваний»);
правило LFU (1еаst frequently used: «використовуваний рідше всіх інших»);
випадковий (random) вибір сегмента.
Перша й остання дисципліни є найпростішими в реалізації, але вони не враховують, наскільки часто використовується той чи інший сегмент і, отже, диспетчер пам'яті може чи вивантажити той сегмент, до якого в найближчому майбутньому буде звертання.
Алгоритм FIFO асоціює з кожним сегментом час, коли він був поміщений у пам'ять. Для заміщення вибирається найбільш старший сегмент.
Для реалізації дисциплін LRU і LFU необхідно, щоб процесор мав додаткові апаратні засоби. Мінімальні вимоги — складання списку, упорядкованого або по тривалості не використання (для дисципліни LRU), або по частоті використання (для дисципліни LFU).
Сторінковий спосіб організації віртуальної пам'яті
При такому способі усі фрагменти програми, на які вона розбивається (за винятком останньої її частини), виходять однаковими. Ці однакові частини називають сторінками і говорять, що пам'ять розбивається на фізичні сторінки, а програма — на віртуальні сторінки. Частина віртуальних сторінок задачі розміщається в оперативній пам'яті, а частина — у зовнішній. Місце в зовнішній пам'яті називають файлом підкачки або сторінковим файлом (swap-файлом), тим самим підкреслюючи, що записи цього файлу — сторінки — заміщають один одного в оперативній пам'яті.
Розбивка всієї оперативної пам'яті на сторінки однакової величини приводить до того, що замість одномірного адресного простору пам'яті використовується двовимірний. Перша координата адресного простору — це номер сторінки, а друга координата — номер комірки всередині обраної сторінки (його називають індексом).
Для відображення віртуального адресного простору задачі на фізичну пам'ять, як і у випадку із сегментним способом організації, для кожної задачі необхідно мати таблицю сторінок для трансляції адресних просторів. Для опису кожної сторінки диспетчер пам'яті ОС заводить відповідний дескриптор, що відрізняється від дескриптора сегмента тим, що в ньому немає необхідності мати поле довжини — адже всі сторінки мають однаковий розмір.
При звертанні до віртуальної сторінки, якої не має в даний момент у оперативної пам'яті, виникає переривання і керування передається диспетчеру пам'яті, що повинний знайти вільне місце. Звичайно надається перша вільна сторінка. Якщо вільної фізичної сторінки немає, то диспетчер пам'яті по одній з вищезгаданих дисциплін заміщення (LRU, LFU, FIFO, random) визначить сторінку, що підлягає розформуванню або збереженню в зовнішній пам'яті.
Якщо обсяг фізичної пам'яті невеликий і навіть часто використовувані сторінки не вдається розмістити в оперативній пам'яті, то виникає так звана пробуксовка — ситуація, при якій завантаження потрібної нам сторінки викликає переміщення в зовнішню пам'ять тієї сторінки, з яким ми теж активно працюємо.
Таким чином, найважливішою перевагою сторінкового способу організації пам’яті є мінімальна фрагментація. Цей метод можна було назвати найкращим, якщо б не наступних дві обставини.
Перша – сторінкова трансляція віртуальної пам’яті вимагає суттєвих накладних витрат. Таблиці сторінок необхідно розміщати теж в пам’яті. Крім цього ці таблиці необхідно обробляти – з ними працює диспетчер пам’яті.
Друга – програми розбиваються на сторінки випадково, без обліку логічних зв’язків. Це приводить до того, що міжсторінкові переходи відбуваються частіше ніж міжсегментні і стає важко організовувати поділ програмних модулів між процесами, що виконуються.
Для того щоб уникнути другого недоліку, зберігши достоїнства сторінкового способу організації пам’яті, було запропоновано ще один спосіб – сегментно-сторінковий.
Сегментно-сторінковий спосіб організації віртуальної пам'яті
Як і в сегментному способі розподілу пам'яті, програма розбивається на логічно закінчені частини — сегменти — і віртуальна адреса містить вказівку на номер відповідного сегмента. Друга складова віртуальної адреси — зсув відносно початку сегмента — у свою чергу, може складатися з двох полів: віртуальної сторінки й індексу. Іншими словами, виходить, що віртуальна адреса тепер складається з трьох компонентів: сегмент, сторінка, індекс.
Цей спосіб організації віртуальної пам'яті вносить ще більшу затримку доступу до пам'яті. Необхідно спочатку обчислити адресу дескриптору сегмента і прочитати його, потім обчислити адресу елементу таблиці сторінок цього сегменту і витягти з пам'яті необхідний елемент, і вже тільки після цього можна до номера фізичної сторінки приписати номер комірки в сторінці (індекс). Затримка доступу до шуканої комірки виходить принаймні в три рази більше, ніж при простій прямій адресації.
Щоб уникнути цієї неприємності, вводиться кешування, причому кеш, як правило, будується по асоціативному принципі.
6. Транслятори, компілятори й інтерпретатори — загальна схема роботи
Визначення транслятора, компілятора, інтерпретатора
Транслятор – це програма, що переводить вхідну програму на вихідній (вхідній) мові в еквівалентну їй вихідну програму на результуючій (вихідній) мові.
Компілятор — це транслятор, що здійснює переклад вихідної програми в еквівалентну їй об'єктну програму мовою машинних команд або мовою ассемблера.
Таким чином, компілятор відрізняється від транслятора лише тим, що його результуюча програма завжди повинна бути написана мовою машинних кодів чи мовою ассемблера. Результуюча програма транслятора, у загальному випадку, може бути написана на будь-якій мові. Відповідно, усякий компілятор є транслятором, але не навпаки — не всякий транслятор буде компілятором.
Необхідність компіляторів з’явилася одночасно з появою мов програмування високого рівня.
Інтерпретатор — це програма, що сприймає вхідну програму вихідною мовою і виконує її.
інтерпретатор, так само як і транслятор, аналізує текст вихідної програми. Однак він не породжує результуючої програми, а відразу ж виконує вихідну відповідно до її змісту, заданим семантикою вхідної мови.
Етапи трансляції. Загальна схема роботи транслятора
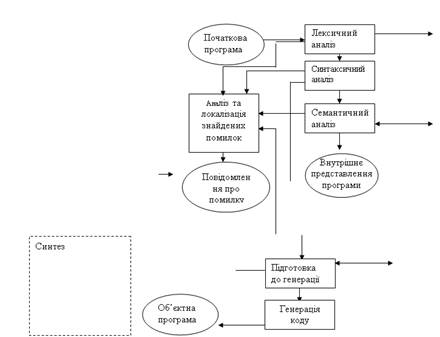
На мал.1 представлена загальна схема роботи компілятора. З неї видно, що в цілому процес компіляції складається з двох основних етапів — синтезу й аналізу.
На етапі аналізу виконується розпізнавання тексту вихідної програми, створення і заповнення таблиць ідентифікаторів. Результатом його роботи служить деяке внутрішнє представлення програми, зрозуміле компілятору.
На етапі синтезу на підставі внутрішнього представлення програми й інформації, що міститься в таблиці (таблицях) ідентифікаторів, породжується текст результуючої програми. Результатом цього етапу є об'єктний код.
7. Призначення й особливості побудови таблиць ідентифікаторів
Призначення й особливості побудови таблиць ідентифікаторів
Компілятор повинний мати можливість зберігати всі знайдені ідентифікатори і зв'язані з ними характеристики на протязі всього процесу компіляції, щоб мати можливість використовувати їх на різних фазах компіляції.
Для цієї мети у компіляторах використовуються спеціальні сховища даних, називані таблицями символів або таблицями ідентифікаторів.
Будь-яка таблиця ідентифікаторів складається з набору полів, кількість яких дорівнює числу різних ідентифікаторів, знайдених у вхідній програмі. Кожне поле містить у собі повну інформацію про даний елемент таблиці. Компілятор може працювати з однією або декількома таблицям ідентифікаторів — їхня кількість залежить від реалізації компілятора.
У таблицях ідентифікаторів може зберігатися наступна інформація:
для змінних:
ім'я змінної;
тип даних змінною;
область пам'яті, зв'язана із змінною;
для констант:
назва константи (якщо воно є);
значення константи;
тип даних константи (якщо потрібно);
для функцій:
ім'я функції;
кількість і типи формальних аргументів функції;
тип результату, що повертається;
адреса коду функції.
Як правило, кожен елемент у вхідній програмі однозначно ідентифікується своїм іменем. Тому компілятору часто доводиться виконувати пошук необхідного елемента в таблиці ідентифікаторів по його імені, у той час як процес заповнення таблиці виконуються нечасто – нові ідентифікатори описуються в програмі набагато рідше, ніж використовуються. Звідси можна зробити висновок, що таблиці ідентифікаторів повинні бути організовані таким чином, щоб компілятор мав можливість максимально швидкого пошуку потрібного йому елемента.
Найпростіші методи побудови таблиць ідентифікаторів
Найпростіший спосіб організації таблиці полягає в тому, щоб додавати елементи в порядку їх надходження. Тоді таблиця ідентифікаторів буде представляти невпорядкований масив інформації, кожна комірка якого буде містити дані про відповідний елементі таблиці.
Пошук потрібного елемента в таблиці буде в цьому випадку полягати в послідовному порівнянні шуканого елемента з кожним елементом таблиці, поки не буде знайдений придатний. Тоді, якщо за одиницю прийняти час, затрачуваний компілятором на порівняння двох елементів (як правило, це порівняння рядків), то для таблиці, що містить N елементів, у середньому буде виконане N/2 порівнянь.
Заповнення такої таблиці буде відбуватися елементарно просто — додаванням нового елемента в її кінець, і час, необхідний на додавання елемента (Тз), не буде залежати від числа елементів у таблиці N. Але якщо N дуже велике, то пошук зажадає значних витрат часу. Такий спосіб організації таблиць ідентифікаторів є неефективним.
Пошук може бути виконаний більш ефективно, якщо елементи таблиці впорядковані (відсортовані) в прямому чи зворотному алфавітному порядку. Ефективним методом пошуку в упорядкованому списку з N елементів є бінарний або логарифмічний пошук. Символ, який варто знайти, порівнюється з елементом (N+l)/2 всередині таблиці. Якщо цей елемент не є шуканим, то ми повинні переглянути тільки блок елементів, пронумерованих від 1 до (N+l)/2-l, чи блок елементів від (N+l)/2+1 до N у залежності від того, менше чи більше шуканий елемент від того, з яким його порівняли. Потім процес повторюється над потрібним блоком у два рази меншого розміру. Так продовжується доти, поки або елемент не буде знайдений, або алгоритм не дійде до чергового блоку, що містить один чи два елементи (з якими уже можна виконати пряме порівняння шуканого елемента).
Тому що на кожнім кроці число елементів, що можуть містити шуканий елемент, скорочується наполовину, то максимальне число порівнянь дорівнює l+log2(N).
Недоліком методу є вимога впорядкування таблиці ідентифікаторів.
Таким чином, при організації логарифмічного пошуку в таблиці ідентифікаторів ми отримуємо істотне скорочення часу пошуку потрібного елемента за рахунок збільшення часу на розміщення нового елемента в таблицю. Оскільки додавання нових елементів у таблицю ідентифікаторів відбувається істотно рідше, ніж звертання до них, то цей метод варто визнати більш ефективним, чим метод організації невпорядкованої таблиці.
8. Призначення й особливості побудови таблиць ідентифікаторів
Хеш-функціею F називається деяке відображення множини вхідних елементів R на множину цілих невід’ємних чисел Z: F(r) = n, r О R, n О Z.
існують різні варіанти хеш-функцій. Одержання результату хеш-функції — «хешування» — звичайно досягається за рахунок виконання над ланцюжком символів деяких простих арифметичних і логічних операцій.
Ситуація, коли двом чи більш ідентифікаторам відповідає те саме значення функції називається колізією.
Природно, що хеш-функція, що допускає колізії, не може бути прямо використана для хеш-адресації в таблиці ідентифікаторів.
Очевидно, що для повного виключення колізій хеш-функція повинна бути взаємно однозначна: кожному елементу з області визначення хеш-функції повинне відповідати одне значення з її множини значень, але і кожному значенню з множини значень цієї функції повинний відповідати тільки один елемент з області її визначення. Тоді будь-яким двом довільним елементам з області визначення хеш-функції будуть завжди відповідати два різні її значення.
Для рішення проблеми колізії можна використовувати багато способів. Одним з них є метод «рехешування» (або «розміщення»). Відповідно до цього методу, якщо для елемента А адреса h(А), обчислена за допомогою хеш-функції вказує на уже зайняту комірку, то необхідно обчислити значення функції n1=h1(А) і перевірити зайнятість комірки за адресою n1. Якщо і вона зайнята, то обчислюється значення h2(A), і так доти, поки або не буде знайдений вільна комірка, або чергове значення hi(А) співпаде з h(А). В останньому випадку вважається, що таблиця ідентифікаторів заповнена і місця в ній більше.
Таку таблицю ідентифікаторів можна організувати по наступному алгоритму розміщення елемента.
Крок 1. Обчислити значення хеш-функції n=h(A) для нового елемента А..
Крок 2. Якщо комірка за адресою n порожня, то помістити в неї елемент А і завершити алгоритм, інакше i:=l і перейти до кроку 3.
Крок 3. Обчислити ni=hi(А). Якщо комірка за адресою ni порожня, то помістити в неї, елемент А і завершити алгоритм, інакше перейти до кроку 4.
Крок 4. Якщо n=ni, то повідомити про помилку і завершити алгоритм, інакше і:=і+1 і повернутися до кроку 3.
Тоді пошук елемента А в таблиці ідентифікаторів, організованої таким чином, буде виконуватися по наступному алгоритму.
Крок 1. Обчислити значення хеш-функції n = h(A) для нового елемента А.
Крок 2. Якщо комірка за адресою n порожня, то елемент не знайдений, алгоритм завершений, інакше порівняти ім'я елемента в комірці n з ім'ям шуканого елемента А. Якщо вони збігаються, то елемент знайдений і алгоритм завершений, інакше і:=1 і перейти до кроку 3.
Крок 3. Обчислити ni=hi(А). Якщо комірка за адресою ni порожня чи n=ni, то елемент не знайдений і алгоритм завершений, інакше порівняти ім'я елемента в комірці ni з ім'ям шуканого елемента А. Якщо вони збігаються, то елемент знайдений і алгоритм завершений, інакше і:=і+1 і повторити крок 3.
9. Призначення й особливості побудови таблиць ідентифікаторів
Неповне заповнення таблиці ідентифікаторів при застосуванні хеш-функцій веде до неефективного використання всього обсягу пам'яті, доступного компілятору. Причому обсяг невикористовуваної пам'яті буде тим вище, чим більше інформації зберігається для кожного ідентифікатора. Цього недоліку можна уникнути, якщо доповнити таблицю ідентифікаторів деякою проміжною хеш-таблицею.
Такий підхід дозволяє отримати два позитивних результатів: по-перше немає необхідності заповнювати порожніми значеннями таблицю ідентифікаторів - це можна зробити тільки для хеш-таблиці; по-друге, кожному ідентифікатору буде відповідати тільки одна комірка у таблиці ідентифікаторів (у ній не буде порожніх невикористовуваних комірок). Порожні комірки в такому випадку будуть тільки в хеш-таблиці, і обсяг невикористовуваної пам'яті не буде залежати від обсягу інформації, збереженої для кожного ідентифікатора — для кожного значення хеш-функції буде витрачатися тільки пам'ять, необхідна для збереження одного покажчика на основну таблицю ідентифікаторів.
На основі цієї схеми можна реалізувати ще один спосіб організації таблиці ідентифікаторів за допомогою хеш-функцій, називаний «метод ланцюжків». Для методу ланцюжків у таблицю ідентифікаторів для кожного елемента додається ще одне поле, у якому може міститися посилання на будь-який елемент таблиці. Спочатку це поле завжди порожнє (нікуди не вказує). Також для цього методу необхідно мати одну спеціальну змінну, котра завжди вказує на першу вільну комірку основної таблиці ідентифікаторів (спочатку — указує на початок таблиці).
Метод ланцюжків працює в такий спосіб по наступному алгоритму.
Крок 1. В усі комірки хеш-таблиці помістити порожнє значення, таблиця ідентифікаторів не повинна містити ні одної комірки, змінна FreePtr (покажчик першої вільної комірки) указує на початок таблиці ідентифікаторів; і:=1.
Крок 2. Обчислити значення хеш-функції ni; для нового елемента Аi;. Якщо комірка хеш-таблиці за адресою ni порожня, то помістити в неї значення змінної FreePtr і перейти до кроку 5; інакше — перейти до кроку 3.
Крок 3. Покласти j:=l, вибрати з хеш-таблиці адреса комірки таблиці ідентифікаторів mj і перейти до кроку 4.
Крок 4. Для комірки таблиці ідентифікаторів за адресою mj перевірити значння поля посилання. Якщо воно порожнє, то записати в нього адресу з перемінної FreePtr і перейти до кроку 5; інакше j:=j+l, вибрати з поля посилання адресу mj і повторити крок 4.
Крок 5. Додати в таблицю ідентифікаторів нову комірка, записати в неї інформацію для елемента Aі (поле посилання повинне бути порожнім), у змінну FreePtr помістити адресу за кінцем доданої комірки. Якщо більше немає ідентифікаторів, які треба розмістити в таблиці, то виконання алгоритму закінчене, інакше і:=і+1 і перейти до кроку 2.
Пошук елемента в таблиці ідентифікаторів, організованої в такий спосіб буде виконуватися по наступному алгоритму.
Крок 1. Обчислити значення хеш-функції n для шуканого елемента А. Якщо комірка хеш-таблиці за адресою n порожня, то елемент не знайдений і алгоритм завершений, інакше покласти j:=l, вибрати з хеш-таблиці адресу комірки таблиці ідентифікаторів mj=n.
Крок 2. Порівняти ім'я елемента в комірки таблиці ідентифікаторів за адресою mj з ім'ям елемента А. Якщо вони співпадають, то шуканий елемент знайдений і алгоритм завершений, інакше - перейти до кроку 3.
Крок 3. Перевірити значення поля посилання в комірці таблиці ідентифікаторів за адресою mj. Якщо воно порожнє, то шуканий елемент не знайдений і алгоритм завершений; інакше j:=j+l, вибрати з поля посилання адреса mj і перейти до кроку 2.
При такій організації таблиць ідентифікаторів у випадку виникненні колізії алгоритм розміщає елементи в комірках таблиці, зв'язуючи їх один з одним послідовно через поле посилання. При цьому елементи не можуть попадати в комірки з адресами, що потім будуть співпадати зі значеннями хеш-функції. Таким чином, додаткові колізії не виникають. У підсумку, у таблиці виникають своєрідні ланцюжки зв'язаних елементів.
10. Призначення й особливості побудови таблиць ідентифікаторів. Комбіновані способи побудови таблиць ідентифікаторів
У реальних компіляторах практично завжди так чи інакше використовується хеш-адресація. Звичайно при розробці хеш-функції творці компілятора прагнуть звести до мінімуму кількість виникаючих колізій не на всій множині можливих ідентифікаторів, а на тих їхніх варіантах, що найбільше часто зустрічаються у вхідних програмах. Звичайно, узяти до уваги всі припустимі вхідні програми неможливо. Найчастіше виконується статистична обробка імен ідентифікаторів, що зустрічаються, на деякій множині типових вихідних програм, а також приймаються в увагу угоди про вибір імен ідентифікаторів, загальноприйняті для вхідної мови. Гарна хеш-функція — це крок до значного прискорення роботи компілятора, оскільки звертання до таблиць ідентифікаторів виконуються багаторазово на різних фазах компіляції.
Те, який конкретно метод застосовується в компіляторі для організації таблиць ідентифікаторів, залежить від реалізації компілятора. Той самий компілятор може мати навіть декілька різних таблиць ідентифікаторів, організованих на основі різних методів.
Як правило, застосовуються комбіновані методи. У цьому випадку, як і для методу ланцюжків, у таблиці ідентифікаторів організується спеціальне додаткове поле посилання. Але на відміну від методу ланцюжків воно має трохи інше значення. При відсутності колізій для вибірки інформації з таблиці використовується хеш-функція, поле посилання залишається порожнім. Якщо ж виникає колізія, то через поле посилання організується пошук ідентифікаторів, для яких значення хеш-функції збігаються по одному з розглянутих вище методів: неупорядкований список, упорядкований список або бінарне дерево. При добре побудованій хеш-функції колізії будуть виникати рідко, тому кількість ідентифікаторів, для яких значення хеш-функції збіглися, буде не настільки велике. Тоді і час пошуку одного серед них буде незначним (у принципі при високій якості хеш-функції підійде навіть перебір неупорядкованому списку).
Такий підхід має переваги в порівнянні з методом ланцюжків: для збереження ідентифікаторів зі співпадаючими значеннями хеш-функції використовуються області пам'яті, що не перетинаються з основною таблицею ідентифікаторів, а виходить, їхнє розміщення не приведе до виникнення додаткових колізій. Недоліком методу є необхідність роботи з динамічно поділюваними областями пам'яті. Ефективність такого методу, очевидно, у першу чергу залежить від якості застосовуваної хеш-функції, а в другу - від методу організації додаткових сховищ даних.
Хеш-адресація — це метод, що застосовується не тільки для організації таблиць ідентифікаторів у компіляторах. Даний метод знайшов своє застосування й в операційних системах, і в системах керування базами даних.
11. Хеш-функція і хеш-адресація
Хеш-функціею F називається деяке відображення множини вхідних елементів R на множину цілих невід’ємних чисел Z: F(r) = n, r О R, n О Z. Сам термін «Хеш-функція» походить від англійського терміна «hash function» (hash — «заважати», «змішувати», «плутати»).
Множина припустимих вхідних елементів R називається областю визначення хеш-функції. Множиною значень хеш-функції F називається підмножина М з множини цілих невід’ємних чисел Z: M Н Z (M є підмножиною Z, М вкючене в Z), що містить усі можливі значення, які повертаються функцією F: "r О R: F(r) ОМ (Для всіх r, які належ R; F(r) належ M.)
Процес відображення області визначення хеш-функції на безліч значень називається «хешуванням». При роботі з таблицею ідентифікаторів хеш-функція повинна виконувати відображення імен ідентифікаторів на множину цілих невід’ємних чисел. Областю визначення хеш-функції буде множина усіх можливих імен ідентифікаторів.
Хеш-адресація полягає у використанні значення, що повертається хеш-функцією, як адресу комірки з деякого масиву даних. Тоді розмір масиву даних повинний відповідати області значень використовуваної хеш-функціи. Отже, у реальному компіляторі область значень хеш-функціи ніяк не повинна перевищувати розмір доступного адресного простору комп'ютера.
Метод організації таблиць ідентифікаторів, заснований на використанні хеш-адресації, полягає в розміщенні кожного елемента таблиці в комірку, адресу якого повертає хеш-функція, обчислена для цього елемента. Тоді в ідеальному випадку для розміщення будь-якого елемента в таблиці ідентифікаторів досить тільки обчислити його хеш-функцію і звернутися до потрібної комірки масиву даних. Для пошуку елемента в таблиці необхідно обчислити хеш-функцію для шуканого елемента і перевірити, чи не є задана нею комірка масиву порожньою (якщо вона не порожня — елемент знайдений, якщо порожня — не знайдений).
Цей метод дуже ефективний — як час розміщення елемента в таблиці, так і час його пошуку визначаються тільки часом, затрачуваним на обчислення хеш-функції, що у загальному випадку незрівнянно менше часу, необхідного на багаторазові порівняння елементів таблиці.
Метод має два очевидних недоліки. Перший з них – неефективне використання обсягу пам'яті під таблицю ідентифікаторів: розмір масиву для її збереження повинний відповідати області значень хеш-функції, у той час як реально збережених у таблиці ідентифікаторів може бути істотно менше. Другий недолік – необхідність відповідного розумного вибору хеш-функції.
12. Способи внутрішнього представлення програм
Усі внутрішні представлення програми звичайно містять у собі дві принципово різні речі — оператори й операнди. Розходження між формами внутрішнього представлення полягають лише в тому, як оператори й операнди з'єднуються між собою. Також оператори й операнди повинні відрізнятися один від іншого, якщо вони зустрічаються в будь-якому порядку. За розрізнення операндів і операторів, як уже було сказано вище, відповідає розроблювач компілятора, що керується семантикою вхідної мови.
Відомі наступні форми внутрішнього представлення програм:
зв'язані облікові структури, що представляють синтаксичні дерева;
багатоадресний код з явно іменованим результатом (тетради);
багатоадресний код з неявно іменованим результатом (тріади);
обернений (постфиксна) польський запис операцій;
асемблерний код або машинні команди.
Синтаксичні дерева
Синтаксичні дерева – це структура, що представляє собою результат роботи синтаксичного аналізатора. Вона відображає синтаксис конструкцій вхідної мови і явно містить у собі повний взаємозв'язок операцій. Очевидно також, що синтаксичні дерева — це машинно-незалежна форма внутрішнього представлення програми.
Недолік синтаксичних дерев полягає в тому, що вони являють собою складні зв'язні структури, а тому не можуть бути тривіальним чином перетворені в лінійну послідовність команд результуючої програми. Проте вони зручні при роботі з внутрішнім представленням програми на тих етапах, коли немає необхідності безпосередньо звертатися до команд результуючої програми.
Синтаксичні дерева можуть бути перетворені в інші форми внутрішнього представлення програми, що представляють собою лінійні списки, з урахуванням семантики вхідної мови. Алгоритми такого роду перетворень розглянуті далі. Ці перетворення виконуються на основі принципів СК-компіляції.
Багатоадресний код з явно іменованим результатом (тетради)
операцій у формі з чотирьох складових: операції, двох операндів і результату операції. Наприклад, тетради можуть виглядати так: <операція>(<операнд1>,<операнд2>,<результат>).
Тетради являють собою лінійну послідовність команд. При обчисленні виразу, записаного у формі тетрад, вони обчислюються одна за іншою послідовно. Кожна тетрада в послідовності обчислюється так: операція, задана тетрадою, виконується над операндами і результат її виконання міститься в змінній, заданій результатом тетради. Якщо якийсь з операндів (чи оба операнда) у тетраді відсутні (наприклад, якщо тетрада являє собою унарну операцію), то він може бути опущений чи замінений порожнім операндом (у залежності від прийнятої форми запису і її реалізації).
Тетради являють собою лінійну послідовність, а тому для них нескладно написати тривіальний алгоритм, що буде перетворювати послідовність тетрад у послідовність команд результуючої грами (або послідовність команд асемблера). У цьому їхня перевага перед синтаксичними деревами. На відміну від команд асемблера тетради не залежать від архітектури обчислювальної системи, на яку орієнтована результуюча програма. Тому вони являють собою машинно-незалежну форму внутрішнього представлення програми.
тетради вимагають більше пам'яті для свого представлення, ніж тріади, вони також не відображають явний взаємозв'язок операцій між собою. Крім того, є складності з перетворенням тетрад у машинний код, тому що вони погано відображаються в команди асемблера і машинні коди, оскільки в наборах більшості сучасних комп'ютерів рідко зустрічаються операції з трьома операндами.
Багатоадресний код з неявно іменованим результатом (тріади)
тріади являють собою запис у формі трьох складових:
<операція>(<операнд1>;<операнд2>)
Їх особливістю є те, що один або обидва операнди можуть бути посиланнями на іншу тріаду. Це в тому випадку, якщо в якості операнда даної тріади виступає результат виконання іншої тріади. Тому тріади при записі нумерують послідовно для зручності посилань.
Кожна тріада обчислюється таким чином: операція, яка задана тріадою, виконується над операндами, якщо в якості одного із операндів або двох є посилання на іншу тріаду, то береться результат обчислення тієї тріади. Результат обчислення кожної тріади потрібно зберігати в тимчасовій пам’яті, так як він може знадобитися наступним тріадам. Якщо один операнд відсутній, він може бути упущений.
Переваги:
легке написання алгоритму;
легко перевести в асемблер ний код.
Недолік: необхідний алгоритм для зберігання в пам’яті проміжного результату.
Тріади є машинно незалежні, вимагають менше пам’яті ніж тетради.
Обернений польський запис
Перевага: ефективний для обчислення математичних виразів.
Недоліки:
необхідно використовувати стек
важко робити оптимізацію
Нехай задано арифметичний вираз виду: (A+B)*(C+D)-E
Представимо цей вираз у вигляді польського запису: AB+CD+*E-
Обернений польський запис володіє властивостями, які перетворюють його в ідеальну проміжну мову при трансляції:
1. обчислення виразу може проводитися шляхом одноразового перегляду, що зручно для генерації коду
2. отримання польського запису просто здійснити на основі алгоритму DX3.
13. Визначення формальної мови і граматики
Формальні мови - це математичний апарат, що дозволяє математично грамотно створити мови програмування і писати компілятори для них.
Формальну мову можна задати як послідовність слів. Слово – це послідовність символів. Тоді навіть програму можна вважати просто словом.
Словами даної мови може бути не довільний набір символів, а лексично і синтаксично правильно побудований. Для того, щоб задати граматику, треба задати множини термінальних і не термінальних символів.
Термінальні – це символи, які використовуються в мові, а проміжні або нетермінальні – це символи, які використовуються для створення слів мови. Створюються слова за граматичними правилами. Застосування правила полягає в заміні в перетворюваному рядку якоїсь послідовності символів, що співпадає з лівою або правою частиною правила.
Компілятор, отримавши на вхід програму, робить зворотну роботу. Він згортає за граматичними правилами від правої до лівої частини початкові символи.
Кінцева множина символів, яка є неподільною, називається словником або алфавітом, а символи, що входять в множину – буквами алфавіту. Послідовність букв алфавіту називається словом або ланцюжком цього алфавіту, число букв, що входить у слово, називається його довжиною.
Якщо задано алфавіт А, то А* - це множина всіх ланцюжків, які можна побудувати з алфавіту А. $ - порожній рядок (рядок, що не містить жодної букви) також входить в А. Для позначення всіх ланцюжків алфавіту А, що не містять порожнього використовується А+.
Формальною граматикою Г називається сукупність таких об’єктів:
Г={VT,VN,<I>,R},
Де VT – термінальний алфавіт (словник). З букв цього алфавіту будуються ланцюжки, які породжуються граматикою.
VN – нетермінальний (допоміжний) алфавіт. Його букви використовуються при побудові ланцюжків, вони можуть входити в проміжні ланцюжки, але не можуть входити в результат побудови.
<I> - початковий символ.
R – множина правил виведення.
Множина кінцевих ланцюжків термінального алфавіту VT граматики Г, виведених з початкового символу <I> називають мовою, яка породжена граматикою Г і позначається L(Г).
Якщо правило виведення граматики мінить один нетермінальний символ, як в лівій, так і в правій частині, то таке правило називається рекурсивним.
Типи формальних граматик
Виділяють 4 типи формальних граматик. Ці граматики визначаються шляхом накладання обмежень на правила граматики.
Граматика типу 0 – граматика загального вигляду, немає обмежень на правила породження.
Граматика типу 1 – контекстно залежна.
Правило: χ1<A>χ2→ χ1ωχ2.
Ланцюжки χ1 і χ2 залишаються незмінними при застосуванні правил, тому їх називають контекстом, а граматику – контекстно залежною.
Граматика типу 2 – контекстно вільна.
Правило: <A>→α, де Системне програмне забезпечення.
Ці правила слідують із правил граматики типу 1 за умови χ1 = χ2 = $.
Граматика типу 3 – автоматна.
Правила виведення: <A>→a або <A>→a<B> або <A>→<B>a, де
Способи задання схем граматик
Схема граматики містить правила виведення, які визначають синтаксис мови або всі ланцюжки породженої мови. Для задання правил використовують різні форми опису:
символічна
форма Бекуса-Наура (ФБН)
ітераційна
синтаксичні діаграми
Символьна мова передбачає використання елементів нетермінального словника і стрілки, як роздільника правої і лівої частини. Але при описі конкретних мов програмування доводиться вводити велику кількість не термінальних символів і символьна форма запису втрачає свою наочність.
Відповідь 14 і 15
14 Сімейство операційних систем UNIX. Історія розвитку ОС UNIX.
Зміст
Запровадження
1. Історія створення, призначення
2. Функциональные характеристики
3. Особливості архітектури ОС UNIX
4. Способи управління процесами і ресурсами
5. Умови експлуатації
6. Переваги й недоліки ОС UNIX
Укладання
Список використаної літератури
Запровадження
UNIX з'явилася 1969 року. За 30 років система стала досить популярну і поширилася машинами з різноманітною потужністю обробки, від мікропроцесорів до великих ЕОМ, забезпечуючи ними умови виконання програм. Система ділиться на частини. Одну частину складають програми розвитку й сервісні функції – це робить операційну середу UNIX такій популярній; дана частина ОС легко доступна користувачам, воно охоплює таких програм, як командний процесор, обмін повідомленнями, пакети обробки текстів і системи обробки вихідних текстів програм. Інша ж частина включає у собі власне операційну систему, підтримує ці програми розвитку й функції.
UNIX – традиційно мережна операційна система.
1. Історія створення, призначення
UNIX зародився до лабораторій Bell Labs фірми AT&T понад 30 тому. Тоді Bell Labs займалася розробкою многопользовательской системи поділу часу MULTICS (Multiplexed Information and Computing Service) що з MIT і General Electric, але це система зазнала невдачі. Bell Labs відмовилася від участі у проекті MULTICS, що дозволило одного з її дослідників, Кену Томпсону, зайнятися пошукової роботою у напрямі поліпшення операційній середовища Bell Labs. Томпсон, і навіть співробітник Bell Labs Денис Рітчі та інших розробляли нову файлову систему, багато рис якої вели своє походження від MULTICS. Для перевірки нової файловою системи Томпсон написав ядро ОС і пояснюються деякі програми для комп'ютера GE-645, який працював під керівництвом мультипрограммной системи поділу часу GECOS. У Кена Томпсона була яка написана ним ще у період роботи над MULTICS гра "Space Travel" - "Космічне подорож". Він запускала в комп'ютері GE-645, але вона працювала на не дуже добре через невисокою ефективності поділу часу. Крім цього, машинне час GE-645 варто було занадто дороге. Через війну Томпсон і Рітчі вирішили гру на машину PDP-7 фірми DEC, має 4096 18-битных слів, телетайп і добрий графічний дисплей. Але в PDP-7 було погане програмне забезпечення, і, закінчивши перенесення гри, Томпсон вирішив реалізувати на PDP-7 ту файлову систему, над що він працював на GE-645. З цієї праці та виникла перша версія UNIX. Вже вона включала властиву сучасної UNIX файлову систему, засновану на індексних дескрипторах inode, мала підсистему управління процесами і пам'яттю, і навіть дозволяла двом користувачам працювати у режимі розподілу часу. Система було написано на ассемблере. Ім'я UNIX (Uniplex Information and Computing Services) дали їй одним співробітником Bell Labs, Брайаном Керниганом,
Першими користувачами UNIX'а стали співробітники відділу патентів Bell Labs, знайдені її зручною середовищем до створення текстів. Вплинув долю UNIX справила перепис в мові високого рівня З, розробленого Денисом Рітчі спеціально цих цілей. Це сталося 1973 року, UNIX налічував на той час вже 25 інсталяцій, й у Bell Labs була створена спеціальна група підтримки UNIX.
Після описи системи Томпсоном і Рітчі в комп'ютерному журналі CACM 1974 р. UNIX набув широкого поширення. ОС стала затребувана в університетах, оскільки їм вона поставлялася безплатно разом із вихідними кодами на З. Широке поширення ефективних C-компиляторов зробило UNIX унікальної на той час ОС завдяки можливості перенесення різні комп'ютери. Університети внесли значний внесок у поліпшення UNIX і подальшу її популяризацію. Ще однією кроком шляху до визнанню UNIX, як стандартизованной середовища стала розробка Денисом Рітчі бібліотеки виводу-введення-висновку stdio. Завдяки використанню цієї бібліотеки для компілятора З, програми для UNIX стали легко стерпними.
ОС UNIX є інтерактивною операційній системою, це традиційно мережна операційна система.
2. Функциональные характеристики
До основним функцій ядра ОС UNIX відносять такі:
1) Инициализация системи - функція запуску і розкрутки. Ядро системи забезпечує засіб розкрутки (bootstrap), що забезпечує завантаження повного ядра на згадку про комп'ютера та запускає ядро.
2) Управління процесами і нитками - функція створення, завершення і відстежування існуючих процесів і ниток ("процесів", виконуваних на загальної віртуальної пам'яті). Оскільки ОС UNIX є мультипроцессной операційній системою, ядро забезпечує поділ між запущеними процесами часу процесора (чи процесорів в мультипроцессорных системах) та інших ресурсів комп'ютера до створення зовнішнього відчуття, що згадані процеси реально виконуються в паралель.
3) Управління пам'яттю - функція відображення практично необмеженої віртуальної пам'яті процесів в фізичну оперативну пам'ять комп'ютера, має обмежені розміри. Відповідний компонент ядра забезпечує поділюване використання одним і тієї ж областей оперативної пам'яті кількома процесами з допомогою зовнішньої пам'яті.
4) Управління файлами - функція, реалізує абстракцію файловою системи, - ієрархії каталогів і файлів. Файловые системи ОС UNIX підтримують кілька типів файлів. Деякі файли можуть утримувати дані в форматі ASCII, інші відповідатимуть зовнішнім пристроям. У файловій системі зберігаються об'єктні файли, що їх файли тощо. Файли зазвичай зберігаються на пристроях зовнішньої пам'яті; доступу до них забезпечується засобами ядра. У UNIX є кілька типів організації файлових систем. Сучасні варіанти ОС UNIX одночасно підтримують більшість типів файлових систем.
5) Комунікаційні кошти - функція, забезпечує можливості обміну даними між процесами, выполняющимися всередині одного комп'ютера (IPC - Inter-Process Communications), між процесами, выполняющимися у різних вузлах локальної чи глобальної мережі передачі, і навіть між процесами і драйверами зовнішніх пристроїв.
6) Програмний інтерфейс - функція, забезпечує доступом до можливостям ядра із боку користувальних процесів з урахуванням механізму системних викликів, оформлених як бібліотеки функцій.
3. Особливості архітектури ОС UNIX
Архітектура ОС UNIX – багаторівнева (мал.1). На нижньому рівні, безпосередньо над устаткуванням, працює ядро ОС. Функції ядра доступні через інтерфейс системних викликів, їхнім виокремленням другий. На наступному рівні працюють командні інтерпретатори, команди, і утиліти системного адміністрування, комунікаційні драйвери і протоколи, - усе те, які зазвичай належать до системному програмному забезпеченню. Нарешті, зовнішній рівень утворюють прикладні програми користувача, мережні та інші комунікаційні служби, СУБД і утиліти.
4. Способи управління процесами і ресурсами
Файли і процеси, є центральними поняттями моделі ОС UNIX. Малюнок 1.2 представляє блок-схему ядра системи, яка відображатиме склад модулів, із яких складається ядро, та його взаємозв'язку друг з одним. Зліва зображено файлова підсистема, а справа підсистема управління процесами – головні компоненти ядра.
точка перетину
Бібліотеки
Рівень користувача
Рівень ядра
Рівень ядра
технічні засоби (апаратура)
апаратури
Рисунок.1.2 Блок-схема ядра ОС
Звернення до операційній системі такі ж, як звичайні виклики функцій програми мовою Сі, і забезпечення бібліотеки встановлюють відповідність між тими викликами функцій і елементарними системними операціями. У цьому програми на ассемблере можуть звертатися до операційній системі безпосередньо, без використання бібліотеки системних викликів. Програми часто звертаються решти бібліотекам, таких як бібліотека стандартних підпрограм вводу-виводу, досягаючи цим повнішого використання системних послуг. І тому під час компіляції бібліотеки пов'язуються з програмами і лише частково входять у програму користувача. Сукупність інтерпретацій операційній системі розділена тих звернення, які взаємодіють із підсистемою управління файлами, й ті, які взаємодіють із підсистемою управління процесами. Файловая підсистема управляє файлами, розміщає записи файлів, управляє вільним простором, доступом до файлам шукатиме й даних для користувачів. Процеси взаємодіють із підсистемою управління файлами, використовуючи у своїй сукупність спеціальних інтерпретацій операційній системі, як-от open (у тому, щоб відкрити файл для читання чи запись),close, read, write, stat (запросити атрибути файла), chown (змінити запис з туристичною інформацією про власника файла) і chmod (змінити права доступу до файлу).
Подсистема управління файлами звертається до даних, які у файлі, використовуючи буферний механізм, управляючий потоком даних між ядром і пристроями зовнішньої пам'яті. Буферный механізм, взаємодіючи з драйверами пристроїв вводу-виводу блоками, ініціює передачу даних до ядру і навпаки. Драйверы пристроїв є такими модулями у складі ядра, які керують роботою периферійних пристроїв. Устройства вводу-виводу блоками ставляться програми користувача до типу запам'ятовувальних пристроїв із довільною вибіркою; їх драйвери побудовано в такий спосіб, що інші компоненти системи сприймають ці устрою як запам'ятовуючі пристрої із довільною вибіркою. Наприклад, драйвер запоминающего устрою на магнітної стрічці дозволяє ядру системи сприймати цей прилад як запам'ятовуючий пристрій із довільною вибіркою. Подсистема управління файлами також безпосередньо взаємодіє зі драйверами пристроїв "неструктурованого" виводу-введення-висновку, до втручання державних буферного механізму. До пристроям неструктурованого вводу-виводу, іноді іменованим пристроями посимвольного виводу-введення-висновку (текстовими), ставляться устрою, які від пристроїв вводу-виводу блоками.
Подсистема управління процесами відпо-відає синхронізацію процесів, взаємодія процесів, розподіл пам'яті і планування виконання процесів. Подсистема управління файлами і підсистема управління процесами взаємодіють між собою, коли файл завантажується на згадку про виконання: підсистема управління процесами читає на згадку про виконувані файли до того, як його виконати.
Прикладами інтерпретацій операційній системі, використовуваних при управлінні процесами, можуть бути fork (створення нової процесу), exec (накладення образу програми на що здійснюється процес), exit (завершення виконання процесу), wait (синхронізація продовження виконання основного процесу з моментом виходу з породженого процесу), brk (управління розміром пам'яті, виділеної процесу) і signal (управління реакцією процесу виникнення екстраординарних подій.
Модуль розподілу пам'яті контролює виділення пам'яті процесам. Якщо якусь мить система відчуває брак фізичної пам'яті для запуску всіх процесів, ядро пересилає процеси між основний рахунок і зовнішньої пам'яттю про те, щоб усе процеси мали змогу виконуватися. Існує дві способу управління розподілом пам'яті: вивантаження (підкачування) і заміщення сторінок. Програму підкачування іноді називають планувальником, т.к. вона "планує" виділення пам'яті процесам і сьогодні впливає працювати планувальника центрального процесора. «Планировщик» планує черговість виконання процесів до того часу, коли вони добровільно не звільнять центральний процесор, дочекавшись виділення будь-якого ресурсу, або поки що ядро системи не выгрузит їх кількість після того, як його час виконання перевищить наперед визначений квант часу. Планировщик вибирає виконання готова до запуску процес із найвищим пріоритетом; виконання попереднього процесу (припиненого) буде продовжено тоді, що його пріоритет буде найвищим серед пріоритетів всіх готові до запуску процесів. Є кілька форм взаємодії процесів між собою, від асинхронного обміну сигналами про події до синхронного обміну повідомленнями.
Нарешті, апаратний контроль відпо-відає обробку переривань і поза зв'язку з машиною. Такі устрою, як диски і термінали, можуть переривати роботу центрального процесора під час виконання процесу. У цьому ядро системи після обробки переривання може поновити виконання перерваного процесу. Прерывания обробляються не самими процесами, а спеціальними функціями ядра системи, перерахованими у контексті виконуваного процесу.
5. Умови експлуатації
UNIX - многопользовательская операційна система. Користувачі, займаються загальними завданнями, можуть об'єднуватись у групи. Кожен користувач обов'язково належить лише до або декільком групам. Усі команди виконуються від імені певного користувача, належить в останній момент виконання до певної групи.
У многопользовательских системах необхідно забезпечувати захист об'єктів (файлів, процесів), що належать одному користувачеві, від інших. ОС UNIX пропонує базові засоби захисту й спільного використання файлів з урахуванням відстежування користувача і групи, володіють файлом, трьох рівнів доступу (для пользователя-владельца, для користувачів группы-владельца, і всіх інших користувачів) й трьох базових прав доступу до файлам (для читання, на запис на виконання). Базові засоби захисту процесів засновані на відстежуванні приналежності процесів користувачам.
Для відстежування власників процесів і файлів використовуються числові ідентифікатори. Идентификатор користувача і групи - ціла кількість (зазвичай) буде в діапазоні від 0 до 65535. Присвоєння унікального ідентифікатора користувача виконується при закладі системним адміністратором нового реєстраційного імені. Значення ідентифікатора користувача і групи - непросто числа, які ідентифікують користувача, - вони сьогодні визначають власників файлів і процесів. Серед користувачів системи виділяється один користувач - системний адміністратор чи суперкористувач, у якого всю повноту прав використання і конфигурирование системи. Це користувач з ідентифікатором 0 і реєстраційним ім'ям root.
При поданні інформації людині зручніше використовувати замість відповідних ідентифікаторів символьні імена - реєстраційне ім'я користувача й ім'я групи. Відповідність ідентифікаторів і символьних імен, і навіть інша інформацію про користувачів і групах у системі (облікові записи), як більшість інший інформації конфігурацію системи UNIX, традиційно, представленій у вигляді текстових файлів. Ці файли - /etc/passwd, /etc/group і /etc/shadow.
6. Переваги й недоліки
Широке поширення UNIX породило проблему несумісності його численних версій. Для користувача дуже неприємний те що, що пакет, куплений одній версії UNIX, відмовляється працювати в інший версії UNIX. Періодично робилися і робляться спроби стандартизації UNIX, але вони мають обмежений успіх. Процес зближення різних версій UNIX та його розбіжності носить циклічний характер. Перед обличчям нової погрози з боку якась інша ОС різні виробники UNIX-версий зближують свою продукцію, але потім конкурентна боротьба змушує їх робити оригінальні поліпшення і версії знову розходяться. У процесі існує і позитивний сторона - поява нових ідей коштів, що поліпшують як UNIX, і багатьох інших операційні системи, перенявшие в нього довгі роки його існування багато чого
корисного. Найбільшого поширення набула отримали дві несумісні лінії версій UNIX: лінія AT&T - UNIX System V, і лінія університету Berkeley-BSD. Багато фірм з урахуванням цих версій розробили і підтримують свої версії UNIX: SunOS і Solaris фірми Sun Microsystems, UX фірми Hewlett-Packard, XENIX фірми Microsoft, AIX фірми IBM, UnixWare фірми Novell (проданий тепер компанії SCO), і список цей ще довго продовжувати.
Найбільшого впливу на уніфікацію версій UNIX надали такі стандарти як SVID фірми AT&T, POSIX, створений під егідою IEEE, і XPG4 консорціуму X/Open. У цих стандартах сформульовані вимоги до інтерфейсу між додатками і ОС, що дозволяє додатків успішно працювати під керівництвом різних версій UNIX.
Однією з основних переваг сімейства операційними системами типу UNIX і виниклого з їхньої основі підходи до стандартизації інтерфейсів операційними системами (важливу складову загального підходу відкритих систем) і те, що вони забезпечують єдину операційну середу за комп'ютерами з різною архітектурою.
Укладання
Операційна система UNIX, що є першою у історії мобільного ОС, які забезпечують надійну середу розробки та використання мобільних прикладних систем, одночасно є практичне підгрунтя для побудови відкритих програмно-апаратних систем і комплексів. Саме широке запровадження у практику ОС UNIX дозволило вийти з гасла Открытых Систем до практичної розробці цю концепцію. Вагомий внесок у розвиток напряму Открытых Систем внесла діяльність із стандартизації інтерфейсів ОС UNIX.
Можна виділити декілька гілок ОС UNIX, різняться як реалізацією, але часом інтерфейсами і семантикою (хоча, з розвитком процесу стандартизації, ці відмінності стають дедалі менше значними). Сьогодні популярний новий вільно який розповсюджується варіант ОС UNIX, званий FreeBSD. Ведуться роботи над розвиненішими версіями BSDNet.
Date: 2015-07-01; view: 1260; Нарушение авторских прав