Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Метод динамического программирования
|
|
Лекция № 10.
ДП представляет собой математический аппарат, разработанный с целью повышения эффективности вычислений при решении некоторого класса задач мат. программирования путем их декомпозиции на относительно небольшие и, следовательно, менее сложные задачи. Характерным для ДП является подход к решению задачи по этапам, с каждым из которых ассоциирована одна управляемая переменная. Набор рекуррентных вычислительных процедур, связывающий различные этапы, обеспечивает получение решения задачи при достижении последнего этапа.
Рассмотрим функционирование некоторого объекта в течение промежутка времени Т. Пусть в момент времени tj состояние объекта характеризуется вектором  , причем в начальный момент времени t1 состояние объекта задано, т.е. вектор
, причем в начальный момент времени t1 состояние объекта задано, т.е. вектор  известен. Объект меняет свое состояние под воздействием управления
известен. Объект меняет свое состояние под воздействием управления  в моменты времени
в моменты времени 
 . При этом управляющее воздействие выбирается из заданной области
. При этом управляющее воздействие выбирается из заданной области  , т.е.
, т.е.
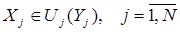 (1)
(1)
Рассматривается случай, когда будущее состояние объекта зависит только от состояния объекта в данный момент времени и управляющего воздействия в этот момент времени, т.е.

 . (2)
. (2)
Здесь  - заданная функция своих аргументов. Уравнение (2) является уравнением движения объекта, т.е. описывает динамику объекта во времени.
- заданная функция своих аргументов. Уравнение (2) является уравнением движения объекта, т.е. описывает динамику объекта во времени.
Обозначим  -выигрыш, получаемый от функционирования объекта на j -м участке времени, т.е. в полуинтервале
-выигрыш, получаемый от функционирования объекта на j -м участке времени, т.е. в полуинтервале  . Если в момент времени
. Если в момент времени 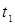 , когда объект находился в состоянии выбрать управление
, когда объект находился в состоянии выбрать управление  , то объект перейдет в состояние
, то объект перейдет в состояние  . Далее последовательно можно выбирать в соответствии с (1)
. Далее последовательно можно выбирать в соответствии с (1)  , в из (2) определять
, в из (2) определять 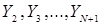 . Этим значениям
. Этим значениям  и
и 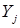 будет соответствовать вполне определенное значение дохода:
будет соответствовать вполне определенное значение дохода:
 (3)
(3)
Если выбирать другие значения управляющих воздействий, то им будут соответствовать другие состояния объекта, а следовательно, и другое значение общего дохода (3). Поэтому естественно поставить следующую оптимизационную задачу:
 (4)
(4)
. (5)
(6)
- задан. (7)
Здесь необходимо найти неизвестные и , которые удовлетворяли бы ограничениям (5)-(7) и максимизировали бы целевую функцию (4).
Эта задача является в общем случае задачей нелинейного программирования и обладает следующими особенностями:
1. Искомые переменные разбиты на N групп, в каждую j-тую из которых входят только и .
2. Целевая функция (4) является суммой функций  , каждая из которых зависит лишь от переменных соответствующей группы. В этом случае говорят, что целевая функция сепарабельна, или аддитивна.
, каждая из которых зависит лишь от переменных соответствующей группы. В этом случае говорят, что целевая функция сепарабельна, или аддитивна.
3. Уравнение (5) является рекуррентным, т.е. через значения и однозначно определяется  .
.
Многие реальные задачи ИСО сводятся к ММ вида (4)-(7), которая допускает различные интерпретации.
Решение задачи вида (4)-(7) обычными методами оказывается либо невозможным, либо неэффективным из-за большой размерности. Поэтому ее решение сводится к последовательному решению N связанных между собой задач меньшей размерности. Для выявления этих задач и связей между ними рассмотрим задачу вида (4)-(7), соответствующую последним этапам  . Она запишется в виде:
. Она запишется в виде:
 (8)
(8)
. (9)
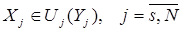 (10)
(10)
 - фиксирован. (11)
- фиксирован. (11)
В этой задаче мы не знаем, чему равно конкретное значение , но если его зафиксировать, то получим соответствующее максимальное значение (8). Если зафиксировать другое значение , то естественно максимальное значение целевой функции (8) будет другим. Обозначим максимальное значение целевой функции (8)при некотором зафиксированном через  :
:

Запишем это равенство в виде:
 (12)
(12)
Здесь первое слагаемое  не зависит от
не зависит от 
 , а вторая сумма функций зависит от
, а вторая сумма функций зависит от  . Поэтому выражение (12) можно переписать в виде:
. Поэтому выражение (12) можно переписать в виде:

Таким образом окончательно запишем:

 (13)
(13)
Данное соотношение справедливо для всех , а для 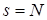 имеем:
имеем:
 (14)
(14)
Полученные рекуррентные соотношения являются основными соотношениями МДП. Это так называемые соотношения Беллмана. Они позволяют свести решение ЗНП (4)-(7) к последовательному решению N задач максимизации меньшей размерности.
Соотношение (13) позволяет вычислить , если известно  , а (14) позволяет вычислить максимальное значение целевой функции на последнем этапе. Тогда рекуррентный процесс решения задачи (13)-(14) должен проводиться в порядке
, а (14) позволяет вычислить максимальное значение целевой функции на последнем этапе. Тогда рекуррентный процесс решения задачи (13)-(14) должен проводиться в порядке 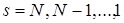 . Действительно, зная
. Действительно, зная 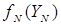 из (13) можно найти значения
из (13) можно найти значения 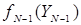 и т.д.
и т.д.
Рассмотрим алгоритм решения такой задачи.
1 шаг. Решается задача (14):
 .
.
Решается столько однотипных задач, сколько существует возможных значений фиксированных  . Здесь максимизируется функция
. Здесь максимизируется функция  по переменной
по переменной  для каждого возможного фиксированного значения . Решается столько однотипных задач, сколько существует возможных значений фиксированных . Поэтому для каждого в результате получаются условные точки максимума
для каждого возможного фиксированного значения . Решается столько однотипных задач, сколько существует возможных значений фиксированных . Поэтому для каждого в результате получаются условные точки максимума 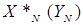 и максимальное значение функции
и максимальное значение функции  в этих точках.
в этих точках.
2 шаг. На этом шаге решается задача (13) при  :
:

Здесь решаются задачи максимизации функции  по переменной
по переменной 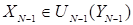 при каждом возможном фиксированном значении
при каждом возможном фиксированном значении  . В результате находятся условные точки максимума
. В результате находятся условные точки максимума  и значения суммы двух функций в этих точках .
и значения суммы двух функций в этих точках .
Далее, зная , решается задача (13) для 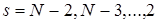 . Наконец, при
. Наконец, при 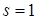 переходим к шагу N:
переходим к шагу N:
N шаг. ,  . На этом шаге решается только одна задача оптимизации, т.к. - задан. В результате получим точку максимума
. На этом шаге решается только одна задача оптимизации, т.к. - задан. В результате получим точку максимума  и значение
и значение  .
.
Для окончательного решение проводим обратное движение алгоритма:
1 шаг:  ;
;  .
.
2 шаг:  ;
;  .
.
3 шаг:  ;
;  .
.
…
N шаг:  ;
;  .
.
 .
.
Таким образом, определяется решение исходной ЗНП (4)-(7) как 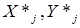 , при этом максимальное значение целевой функции (4) будет равно значению
, при этом максимальное значение целевой функции (4) будет равно значению  .
.
Date: 2016-05-25; view: 440; Нарушение авторских прав