Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Автоматы с магазинной памятью и контекстно-свободные языки
|
|
Для языков, которые не могут быть описаны регулярными выражениями, автоматные распознаватели должны иметь более сложную структуру, чем конечный автомат. Свойства конечного автомата не предполагают зависимости его переходов из текущего внутреннего состояния от истории попадания в это состояние. Автомат, в котором предусмотрена такая зависимость, можно считать более мощным с точки зрения множества распознаваемых им языков. Если для хранения некоторой информации об истории переходов автомата между внутренними состояниями воспользоваться стеком (магазином), получается распознаватель, именуемый автоматом с магазинной памятью. Структура такого автомата приведена на рис. 8.
 |
|



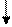


|





Рис. 8. Структура автомата с магазинной памятью
Управляющей таблицей в этой структуре названо некое подобие таблицы переходов конечного автомата. Схема на рисунке предполагает, что входные символы, размещенные на входной ленте, поставлены теперь в заголовках столбцов управляющей таблицы, а внутренние состояния – в заголовках ее строк. Текущее внутреннее состояние автомата определяется содержанием вершины стека, а прочая информация в стеке – это данные о предыдущих внутренних состояниях автомата. Ячейки управляющей таблицы содержат несколько больше информации, чем просто внутреннее состояние, в которое должен перейти автомат. Для того, чтобы можно было воспользоваться хранящейся в стеке историей переходов автомата, очевидно, необходимо не только добавлять данные в стек, но и удалять данные из стека, когда часть этой истории становится ненужной в определении дальнейшего поведения автомата. Поэтому содержание управляющей таблицы составляют команды какого-либо изменения содержания стека, перемещения по входной ленте, а также завершения процесса распознавания входной строки с выводом о ее принадлежности или непринадлежности языку, принимаемому автоматом.
Формальные языки, для которых может быть построен распознаватель в виде автомата с магазинной памятью, образуют класс контекстно-свободных языков (КС-языков). Характерной особенностью грамматик языков такого класса является вид их правил:
U::= α,
где U Î V, α Î(V È T)* (α – произвольная строка из терминалов и/или нетерминалов или пустая строка), а контекстно-свободными эти грамматики и описываемые ими языки называются потому, что, как следует из их правил, в сентенциальной форме символ U может быть заменен строкой α (или наоборот) независимо от какого-либо сопровождающего их контекста.
Практический интерес, с точки зрения программной реализации, представляют детерминированные автоматы с магазинной памятью, т.е. такие, с помощью которых задача распознавания (разбора) заданной строки решается за один просмотр этой строки без возвратов и перебора вариантов решения. Во внешнем виде управляющей таблицы детерминированность автомата проявляется в том, что каждая ячейка содержит ровно одну команду. К сожалению, не для любого КС-языка может быть построен именно детерминированный распознаватель. К наиболее распространенным КС-языкам, подлежащим детерминированному анализу, относятся LL(1)- и LR(1)-языки, которые описываются, соответственно, LL(1)- и LR(1)-грамматиками. Коротко используемую аббревиатуру можно прокомментировать так. Первая буква L означает, что анализатор, использующий грамматику, просматривает анализируемую строку слева направо. Вторая буква L или R означает, соответственно, использование грамматики для построения левого или правого разбора (вывода заданной строки с заменой в сентенциальных формах, соответственно, левых или правых нетерминалов). Число 1 в скобках указывает на то, что в разбираемой строке для принятия правильного решения на каждом шаге разбора анализатору достаточно «видеть» один текущий символ.
Date: 2015-10-19; view: 931; Нарушение авторских прав