Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Модульная структура программных продуктов
|
|
В ОС.
Запись - это наименьший элемент данных, который может быть обработан как единое целое прикладной программой при обмене с внешним устройством.
Причем в большинстве ОС размер записи равен одному байту. В то время как приложения оперируют записями, физический обмен с устройством осуществляется большими единицами (обычно блоками). Поэтому записи объединяются в блоки для вывода и разблокируются - для ввода. Вопросы распределения блоков внешней памяти между файлами рассматриваются в следующей лекции.ОС поддерживают несколько вариантов структуризации файлов. Простейший вариант - так называемый последовательный файл. То есть файл является последовательностью записей. Поскольку записи, как правило, однобайтовые, файл представляет собой неструктурированную последовательность байтов. Обработка подобных файлов предполагает последовательное чтение записей от начала файла, причем конкретная запись определяется ее положением в файле. Такой способ доступа называется последовательным (модель ленты). В реальной практике файлы хранятся на устройствах прямого (random) доступа, например на дисках, поэтому содержимое файла может быть разбросано по разным блокам диска, которые можно считывать в произвольном порядке. Причем номер блока однозначно определяется позицией внутри файла. Файл, байты которого могут быть считаны в произвольном порядке, называется файлом прямого доступа.
Таким образом, файл, состоящий из однобайтовых записей на устройстве прямого доступа, - наиболее распространенный способ организации файла. Базовыми операциями для такого рода файлов являются считывание или запись символа в текущую позицию. В большинстве языков высокого уровня предусмотрены операторы посимвольной пересылки данных в файл или из него.
Подобную логическую структуру имеют файлы во многих файловых системах, например в файловых системах ОС Unix и MS-DOS. ОС не осуществляет никакой интерпретации содержимого файла. Эта схема обеспечивает максимальную гибкость и универсальность. С помощью базовых системных вызовов (или функций библиотеки ввода/вывода) пользователи могут как угодно структурировать файлы. В частности, многие СУБД хранят свои базы данных в обычных файлах.
Известны как другие формы организации файла, так и другие способы доступа к ним, которые использовались в ранних ОС, а также применяются сегодня в больших мэйнфреймах (mainframe), ориентированных на коммерческую обработку данных. Первый шаг в структурировании - хранение файла в виде последовательности записей фиксированной длины, каждая из которых имеет внутреннюю структуру. Операция чтения производится над записью, а операция записи переписывает или добавляет запись целиком. Другой способ представления файлов - последовательность записей переменной длины, каждая из которых содержит ключевое поле в фиксированной позиции внутри записи. Базисная операция в данном случае - считать запись с каким-либо значением ключа. Записи могут располагаться в файле последовательно (например, отсортированные по значению ключевого поля) или в более сложном порядке. Метод доступа по значению ключевого поля к записям последовательного файла называется индексно-последовательным. В некоторых системах ускорение доступа к файлу обеспечивается конструированием индекса файла. Индекс обычно хранится на том же устройстве, что и сам файл, и состоит из списка элементов, каждый из которых содержит идентификатор записи, за которым следует указание о местоположении данной записи. Для поиска записи вначале происходит обращение к индексу, где находится указатель на нужную запись.
Такие файлы называются индексированными, а метод доступа к ним - доступ с использованием индекса. В этом случае ОС использует древовидную организацию блоков, при которой блоки, составляющие файл, являются листьями дерева, а каждый внутренний узел содержит указатели на множество блоков файла. Для больших файлов индекс может быть слишком велик. В этом случае создают индекс для индексного файла (блоки промежуточного уровня или блоки косвенной адресации).
39. Цифровые каналы передачи данных (Рома)
40. Управление проектом АСОИУ (свободен)
41. Понятия приоритета и очереди процессов (Мирош)
42. Задачи линейной оптимизации (Дима Кипоров, Ваня Семенов, =106)
43. Защита БД
Защита БД должна охватывать следующие моменты:
- используемое оборудование
- ПО
- персонал
- сами данные.
В многопользовательских вычислительных системах компьютерные средства контроля включают следующие моменты:
1. Авторизация пользователей.
2. Использование представлений.
3. Средства копирования и восстановления.
4. Шифрование.
5. Вспомогательные процедуры.
Авторизация пользователей заключается в предоставлении определенных прав, которые обеспечивают доступ к системе в целом, либо к ее отдельным объектам.
Аутентификация – механизм определений того, является ли пользователь тем, за кого се6я выдает.
Представление – это динамический результат выполнения одной или нескольких реляционных операций над базами отношения.
Резервное копирование – процесс периодического создания копий БД из файла журнала БД.
Средство поддержания целостности средства данных предназначены для исключения перехода данных в несогласованное состояние.
Шифрование данных – кодирование данных с помощью специальных алгоритмов, которые делают данные непригодными для чтения, если не известен ключ шифрования.
К основным средствам защиты относятся:
Защита паролем
Шифрование данных и программ
Разграничение прав доступа к обьектам баз данных
Защита полей и записей таблиц БД
Защита паролем это довольно простой и удобный метод защиты бд. Пароли и логины доступа хранятся в зашифрованном виде в системных файлах бд и так же являются бд.
Шифрование является более продвинутым способом защиты. Шифрование это преобразование информации, посредством алгоритма шифрования.
С целью контроля использования основных ресурсов БД во многих системах имеются средства установления прав доступа к объектам БД. Права доступа определяют возможные действия над объектом. Владелец объекта и администратор БД,имеют все права. Остальные пользователи могут иметь разные уровни доступа
Вот некоторые из них по отношению к таблицам:
Просмотр данных
Изменение данных
Добавление новых записей
Добавление или удаление данных
Изменение структуры таблицы
По отношению к полям относятся:
Полный запрет доступа
Только чтение
Полное разрешение всех операций
Защита отдельных полей таблицы(могут быть совсем скрыты от пользователя)
Дополнительные средства защиты БД:
Встроенные средства контроля значений данных в соответствии с типами
Повышение достоверности вводимых данных
Обеспечение целостности связей таблиц
Организации совместного использования объектов БД в сети
44. Разделение каналов по времени и частоте (Мирош)
45. Проектная документация АСОИУ (свободен)
46. Средства коммуникации процессов (свободен)
47. Задачи дискретной оптимизации (Юра, =111)
48. Целостность БД
Це́лостность ба́зы да́нных – соответствие имеющейся в базе данных информации её внутренней логике, структуре и всем явно заданным правилам.Каждое правило, налагающее некоторое ограничение на возможное состояние базы данных, называется ограничением целостности.
Целостность базы данных может быть нарушена вследствие сбоя оборудования, ошибки пользователя или программной ошибки. В системах со многими пользователями целостность может быть нарушена при одновременном обращении к одним и тем же фрагментам данных.
Целостность обеспечивается путем задания ограничений. В зависимости от источника можно выделить инструментальные ограничения, структурные ограничения и бизнес-правила.
К инструментальным ограничениям относят проверку правильности данных при вводе. Например, поле числа не может содержать текстовые символы, а поле даты должно содержать допустимое значение даты. Средства реализации инструментальных ограничений встроены в СУБД.
Структурные ограничения базируются на смысловых зависимостях между атрибутами отношений. Ссылочная целостность – это ограничение базы данных, гарантирующее, что ссылки между данными являются действительно правомерными и неповрежденными.
К структурным ограничениям относят также уникальность первичного ключа и уникальность возможных ключей. Бизнес-правила представляют собой условия того, что данные соответствуют предметной области. Бизнес-правила можно разделить на элементарные и расширенные. Элементарные правила ограничивают значения конкретного атрибута или агрегата атрибутов через ограничения домена. Расширенные правила выражаются в виде некоторой зависимости между атрибутами.
Ограничения могут быть статическими или динамическими. Статические ограничения должны выполняться для каждого состояния базы данных. Динамические ограничения проявляются при переходе базы данных из одного состояния в другое. Например, при повышении заработной платы служащего новое значение должно быть больше старого.
Ограничения могут найти свое выражение:
– при описании атрибутов отношений в концептуальной схеме;
– в запросе к базе данных;
– в процедуре базы данных;
– в правиле (в триггере).
Процедуры базы данных создаются проектировщиком базы данных и дополняют СУБД. В различных СУБД они носят название хранимых, присоединенных, разделяемых и т. д. В системах с архитектурой "клиент-сервер" использование процедур баз данных позволяет значительно снизить трафик сети. Прикладная программа, вызывающая процедуру, передает серверу лишь ее имя и параметры.
Структурные ограничения реализуются процедурой нормализации, использующей функциональные зависимости, действующие между сущностями и атрибутами.
Правило (триггер) – программа для наблюдения за ситуацией, возникающей при изменениях в базе данных. Правило придается таблице базы данных и применяется при выполнении над ней операций включения, удаления или обновления строк, а также при изменении значений в столбцах таблицы. Применение правила заключается в проверке условия, при наступлении истинности которого вызывается указанная внутри правила процедура базы данных. Правила (так же, как и процедуры баз данных) хранятся независимо от прикладных программ.
ПРототипом правил послужили триггеры (triggers), которые впервые появились в СУБД Sybase и впоследствии были реализованы в том или ином виде и под тем или иным названием в большинстве многопользовательских СУБД.
Транзакция – неделимая с точки зрения воздействия на БД последовательность операторов манипулирования данными (чтения, удаления, вставки, модификации), такая, что:
1) либо результаты всех операторов, входящих в транзакцию, отображаются в БД;
2) либо воздействие всех операторов полностью отсутствует.
При этом для поддержания ограничений целостности на уровне БД допускается их нарушение внутри транзакции так, чтобы к моменту завершения транзакции условия целостности были соблюдены.
Для обеспечения контроля целостности каждая транзакция должна начинаться при целостном состоянии БД и должна сохранить это состояние целостным после своего завершения. Если операторы, объединенные в транзакцию, выполняются, то происходит нормальное завершение транзакции, и БД переходит в обновленное (целостное) состояние. Если же происходит сбой при выполнении транзакции, то происходит так называемый откат к исходному состоянию БД.
Модели транзакций.: модель автоматического выполнения транзакций и модель управляемого выполнения транзакций, обе основаны на инструкциях языка SQL – COMMIT и ROLLBACK.
Автоматическое выполнение транзакций.
В стандарте ANSI/ISO зафиксировано, что транзакция автоматически начинается с выполнения пользователем или программой первой инструкции SQL. Далее происходит последовательное выполнение инструкций до тех пор, пока транзакция не завершается одним из двух способов:
• инструкцией COMMIT, которая выполняет завершение транзакции: изменения, внесенные в БД, становятся постоянными, а новая транзакция начинается сразу после инструкции COMMIT;
• инструкцией ROLLBACK, которая отменяет выполнение текущей транзакции и возвращает БД к состоянию начала транзакции, новая транзакция начинается сразу после инструкции ROLLBACK.
Такая модель создана на основе модели, принятой в СУБД DB2.
Управляемое выполнение транзакций.
Отличная от модели ANSI/ISO модель транзакций используется в СУБД Sybase, где применяется диалект Transact-SQL, в котором для обработки транзакций служат четыре инструкции:
• инструкция BEGIN TRANSACTION сообщает о начале транзакции, т.е. начало транзакции задается явно;
• инструкция COMMIT TRANSACTION сообщает об успешном выполнении транзакции, но при этом новая транзакция не начинается автоматически;
• инструкция SAVE TRANSACTION позволяет создать внутри транзакции точку сохранения и присвоить сохраненному состоянию имя точки сохранения, указанное в инструкции;
• инструкция ROLLBACK отменяет выполнение текущей транзакции и возвращает БД к состоянию, где была выполнена инструкция SAVE TRANSACTION (если в инструкции указана точка сохранения – ROLLBACK TO имя_точки_сохранения), или к состоянию начала транзакции.
49. Характеристики проводных линий связи (Ира)
50. Инструментальные средства проектирования АСОИУ
Инструментальные средства проектирования АСОИУ включают в себя различные программные системы автоматизации проектирования, поддерживающие создание и сопровождение АСОИУ на разных этапах проектирования и при разработке разного вида обеспечения (информационного, программного и других).
При разработке АСОИУ организационными объектами преимущественно используются так называемые CASE-средства (Computer Aided Software Engineering). Это программные средства, поддерживающие анализ и формулировку требований к системе, проектирование программного обеспечения и баз данных, тестирование, документирование и управление проектами. Большинство существующих CASE-средств применяют методологию структурного или объектно-ориентированного анализа и проектирования и представляют собой интегрированные системы из отдельных CASE- компонентов.
В качестве CASE-компонентов выступают:
– репозитарий (специальным образом организованное хранилище различных версий проектов);
– графические средства анализа и проектирования, обеспечивающие создание и редактирование иерархически взаимосвязанных диаграмм;
– средства разработки программ
– средства тестирования;
– средства документирования;
– средства управления проектом;
– средства интеграции с наиболее известными базами данных.
Примерами развитых CASE-систем могут служить система ERWIN, предназначенная для автоматизации проектирования баз данных и семейство объектно-ориентированных CASE-средств Rational Rose (RR), которые основаны на использовании языка моделирования UML. Система RR может генерировать коды разрабатываемых программ на языках С++, Small Talk, Java и ряде других. Кроме того, RR имеет средства для разработки проектной документации в виде диаграмм и спецификаций, а также имеет средства для реверсного инжиниринга программ. В состав RR входят следующие компоненты:
– репозитарий;
– графический интерфейс пользователя;
– средства просмотра проекта;
– средства контроля проекта;
– средства сбора статистики;
– средства генерации документации;
– средства генерации кода программ;
– анализатор, обеспечивающий реверсный инжиниринг (возможность повторного использования разработанных проектов и их компонентов).
Разработка баз данных в ERWIN состоит из двух этапов: этапа составления логической модели базы данных и этапа разработки на ее основе физической модели базы данных. Логическая модель означает прямое описание фактов проблемной области задач АСОИУ, то есть реальных объектов этой области и их связей. Объекты именуются на естественном языке, при этом не указываются типы данных (например, целое, вещественное и так далее) и не рассматривается использование конкретной СУБД. Конкретная СУБД, ее таблицы и типы данных составляют физическую модель. ERWIN поддерживает ряд СУБД, таких как Microsoft SQL, Oracle, Sybase, Microsoft Access, FoxPro, INFORMIX и многие другие.
При разработке АСОИУ технологическими процессами большую популярность приобрели системы сбора данных и диспетчерского управления (SCADA-системы), обеспечивающие сбор информации с удаленных объектов в реальном времени, анализ и обработку собранной информации и управление этими объектами. В SCADA-системах реализуются следующие принципы:
– работа в режиме реального времени;
– избыточность информации;
– сетевая архитектура открытых систем;
– модульность исполнения.

Современные SCADA-системы, и выполняют следующие функции:
· прием информации о контролируемых параметрах управляемых объектов;
· сохранение информации;
· обработка принятой информации;
· графическое представление хода технологического процесса;
· прием и передача команд оператора;
· регистрация событий;
· оповещение персонала об аварийных ситуациях;
· формирование сводок и других отчетов;
· обмен информацией с автоматизированной системой управления предприятием.
51. Язык SQL (Нурсиня)
52. Многокритериальные задачи
- математическая модель принятия оптимального решения одновременно по нескольким критериям. Эти критерии могут отражать оценки различных качеств объекта(или процесса), по поводу к-рых принимается решение, или оценки одной и той же его характеристики, но с различных точек зрения. Теория М. з. относится к числу математич. методов исследования операций.
Формально М. з. задается множеством X «допустимых решений» и набором целевых функций  на {X}, принимающих действительные значения. Сущность М. з. состоит в нахождении оптимального ее решения, т.е. такого
на {X}, принимающих действительные значения. Сущность М. з. состоит в нахождении оптимального ее решения, т.е. такого  , к-рое в том или ином смысле максимизирует значения всех функций
, к-рое в том или ином смысле максимизирует значения всех функций 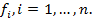 Существование решения, буквально максимизирующего все целевые функции, является редким исключением. Поэтому в теории М. з. понятие оптимальности получает различные и притом нетривиальные истолкования. Содержание теории М. з. состоит в выработке таких концепций оптимальности, доказательстве их реализуемости (т. е. существования оптимальных в соответствующем смысле решений) и нахождении этих реализаций (т. е. в фактич. решении задачи).
Существование решения, буквально максимизирующего все целевые функции, является редким исключением. Поэтому в теории М. з. понятие оптимальности получает различные и притом нетривиальные истолкования. Содержание теории М. з. состоит в выработке таких концепций оптимальности, доказательстве их реализуемости (т. е. существования оптимальных в соответствующем смысле решений) и нахождении этих реализаций (т. е. в фактич. решении задачи).
Наиболее прямолинейным подходом к решению М. з. является сведение ее к обычной("однокритериальной") задаче математнч. программирования путем замены системы целевых функций на одну "сводную" функцию 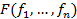 . В ее роли могут выступать "взвешенные суммы"
. В ее роли могут выступать "взвешенные суммы" 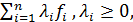 "взвешенные максимумы"
"взвешенные максимумы" 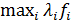 и др. "свертки" исходных целевых функций. Такой подход концептуально и технически представляется самым удобным. Основным его недостатком является трудно выполнимое требование содержательной сопоставимости значений различных целевых функций, а также неопределенность (и нередко произвольность) в выборе функции F и, в частности, "весов"
и др. "свертки" исходных целевых функций. Такой подход концептуально и технически представляется самым удобным. Основным его недостатком является трудно выполнимое требование содержательной сопоставимости значений различных целевых функций, а также неопределенность (и нередко произвольность) в выборе функции F и, в частности, "весов" 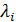 . Для их установления нередко рекомендуется прибегать к экспертным оценкам.
. Для их установления нередко рекомендуется прибегать к экспертным оценкам.
Частный случай описанного подхода состоит в выделении "решающего критерия", т. е. в том, чтобы все веса , за исключением нек-рого 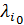 , полагать равными нулю. Тогда М. з. перейдет в обычную задачу математич. программирования, а множество ее оптимальных решений можно рассматривать как множество допустимых решений новой М. з. с целевыми функциями
, полагать равными нулю. Тогда М. з. перейдет в обычную задачу математич. программирования, а множество ее оптимальных решений можно рассматривать как множество допустимых решений новой М. з. с целевыми функциями 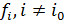 . В качестве решений М. з. можно рассматривать решения, оптимальные по Парето, т.е. решения, не поддающиеся улучшению по какому-либо критерию, иначе как за счет ухудшения по другим критериям (иначе говоря, такие
. В качестве решений М. з. можно рассматривать решения, оптимальные по Парето, т.е. решения, не поддающиеся улучшению по какому-либо критерию, иначе как за счет ухудшения по другим критериям (иначе говоря, такие  , что для любого
, что для любого  из
из 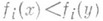 следует
следует 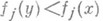 при нек-ром у). Недостатком этого подхода является множественность оптимальных по Парето решений. Этот недостаток преодолевается предложенным Дж. Нашем (J. Nash) методом "арбитражных решений", существенно ограничивающим число выбираемых решений среди оптимальных по Парето содержательных соображений нек-рых минимальных допустимых значений
при нек-ром у). Недостатком этого подхода является множественность оптимальных по Парето решений. Этот недостаток преодолевается предложенным Дж. Нашем (J. Nash) методом "арбитражных решений", существенно ограничивающим число выбираемых решений среди оптимальных по Парето содержательных соображений нек-рых минимальных допустимых значений 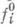 и в последующем нахождении допустимого х, максимизирующего
и в последующем нахождении допустимого х, максимизирующего
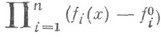 М. з. можно рассматривать как игру и подходить к ее решению на основе различных теоретико-игровых методов. Напр., если допустимое решение х выбирается с целью максимизировать одну из целевых функций
М. з. можно рассматривать как игру и подходить к ее решению на основе различных теоретико-игровых методов. Напр., если допустимое решение х выбирается с целью максимизировать одну из целевых функций 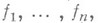 но какую именно - для принимающего решение субъекта неизвестно, то можно воспользоваться взвешенной суммой этих функций, взяв в качестве весов компоненты смешанной стратегии "природы". Возможны трактовки М. з. как бескоалиционной игры, в том числе с позиций кооперативной теории (см. Кооперативная игра), и применения связанных с этим принципов оптимальности.
но какую именно - для принимающего решение субъекта неизвестно, то можно воспользоваться взвешенной суммой этих функций, взяв в качестве весов компоненты смешанной стратегии "природы". Возможны трактовки М. з. как бескоалиционной игры, в том числе с позиций кооперативной теории (см. Кооперативная игра), и применения связанных с этим принципов оптимальности.
53. Иерархическая модель данных (Дамир)
54. Спутниковые каналы связи (свободен)
55. Типизация проектных решений АСОИУ (свободен)
56. Назначение и основные компоненты системы БД (Миша)
57. Принятие решений в условиях неопределенности (Катя, =121)
58. Сетевая модель данных (Нурсиня)
59. Сотовые системы связи
Сотовая связь – один из видов мобильной радиосвязи, в основе которого лежит сотовая сеть. Ключевая особенность заключается в том, что общая зона покрытия делится на ячейки (соты), определяющиеся зонами покрытия отдельных базовых станций. Соты частично перекрываются и вместе образуют сеть. Сеть составляют разнесённые в пространстве приёмопередатчики, работающие в одном и том же частотном диапазоне, и коммутирующее оборудование, позволяющее определять текущее местоположение подвижных абонентов и обеспечивать непрерывность связи при перемещении абонента из зоны действия одного приёмопередатчика в зону действия другого.

Основные составляющие сотовой сети – это сотовые телефоны и базовые станции, которые обычно располагают на крышах зданий и вышках. Будучи включённым, сотовый телефон прослушивает эфир, находит сигнал базовой станции. После этого телефон посылает станции свой уникальный идентификационный код. Телефон и станция поддерживают постоянный радиоконтакт, периодически обмениваясь пакетами. Связь телефона со станцией может идти по аналоговому протоколу (AMPS, NAMPS, NMT-450) или по цифровому (DAMPS, CDMA, GSM, UMTS). Если телефон выходит из поля действия базовой станции (или качество радиосигнала сервисной соты ухудшается), он налаживает связь с другой.
Основной элемент сотовой сети любого стандарта – это базовая станция, которая занимается приемом звонков абонентов и передачей данных по радиоканалу. В зависимости от стандарта связи, базовые станции работают в диапазоне частот от 450 до 2100 МГц. Поскольку радиус работы таких станций составляет порядка 10–12 км за городом и около 3–5 км в городе, их строят много и располагают относительно недалеко друг от друга. Тенденция использования широкополосных абонентских услуг (4G, потоковое видео) приводит к тому, что сотовым операторам необходимо увеличивать пропускную способность сети. Это достигается за счет модернизации оборудования (использование рабочей частоты 900/1800/2100 МГц) и увеличения числа базовых станций на ограниченной территории (при увеличении рабочей частоты снижается мощность передатчика, что ведет к уменьшению радиуса одной соты). Полностью автономные базовые станции представляют собой небольшие контейнеры. В обязательном порядке имеется беспроводной или кабельный канал связи с центром управления сетью, куда передается огромный поток данных – входящие и исходящие вызовы от абонентов. В городе базовые станции предпочитают устанавливать на уже существующие конструкции – в основном, на высотные здания. А на открытом пространстве используются антенно-мачтовые сооружения.
Приемопередающее оборудование располагается в шкафах или стойках. Здесь располагаются системные модули GSM (глобальный стандарт цифровой мобильной сотовой связи, с разделением каналов по времени и частоте.), CDMA (технология связи, при которой каналы передачи имеют общую полосу частот, но разную кодовую модуляцию) и LTE (стандарт беспроводной высокоскоростной передачи данных для мобильных телефонов и других терминалов, работающих с данными). Эти модули являются сердцем базовой станции, они принимают сигнал с антенн и осуществляют его преобразование и сжатие с дальнейшей пересылкой. Передача информации между системными модулями и приёмопередатчиками осуществляется через оптоволоконные кабели.
60. Графические средства представления проектных решений АСОИУ (свободен)
61. Обзор современных СУБД (Оля)
62. Основные понятия теории моделирования (свободен)
63. Реляционная модель данных (Оля)
64. Количество информации и энтропия, кодирование информации
Количественная мера информации необходима для сравнения различных источников сообщений и каналов связей.
При введении меры информации абстрагируемся от конкретного смысла информации.
При ожидании сообщения существует неизвестность или неопределенность относительно того, что содержится в ожидаемом сообщении. Это сообщение уничтожает эту неопределенность. Значит, чем больше ликвидируется неопределенности, тем большее количество информации несет сигнал.
 Неопределенность, которая ликвидируется приходом такого сигнала является единицей информации и называется – 1 бит.
Неопределенность, которая ликвидируется приходом такого сигнала является единицей информации и называется – 1 бит.
С помощью такой единицы находим количество информации в более сложных случаях. Сложную операцию выбора одного состояния из нескольких сводят к последовательности элементарных операций выбора между двумя равновероятностными возможностями.
Рассмотрим случай, если все состояния сигнала имеют равные вероятности появления. Укажем в таблице количество состояний и соответствующее количество элементарных операций выбора
| Кол.сост. | Кол.операций |
Легко заметить связь между значениями первого и второго столбцов. Обозначим через m – количество состояний сигнала, через I – количество элементарных операций выбора или количество информации. Тогда можно записать формулу:m = 2I. Выразим I через m, получим
формулу для вычисления количества информации, если все состояния сигнала равновероятностны:
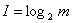
Вычислим по этой формуле количество информации для примеров 1 и 2, рассмотренных выше:
В первом примере:
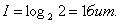
Во втором примере:
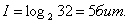
На практике неопределенность зависит не только от числа состояний сигнала, но и от вероятности реализации сигнала. Рассмотрим простой пример: в шахматы играют чемпион мира с перворазрядником. Сообщение о том, что выиграл чемпион, несет мало информации, т.к. это ожидаемое сообщение, вероятность выигрыша чемпиона велика. А вот сообщение о победе перворазрядника уничтожило больше неопределенности, вероятность такого исхода мала. Этот пример иллюстрирует необходимость учета вероятности появления каждого из состояний сигнала.
Выведем формулу вычисления количества информации для такого случая.
Пусть А и В –события или состояния сигнала. Количество информации I(A/B) заключается в сообщении события В относительно наступления А и равно значению выражения
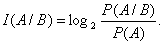
Числитель и знаменатель дроби – вероятности соответствующих событий.
Если появляется событие В=А, т.е. наступило А (значит А – достоверное событие), то I(A/B)= I(A/A)= I(A) – заключающееся в сообщении А. Учитывая, что А – достоверное событие, получим формулу для вычисления количества информации для сообщения А:

В дальнейшем основание логарифма указывать не будем.
Полученная формула
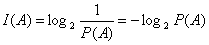
позволяет вычислить количество информации при получении сообщения (состояния), вероятность появления которого равна р.
Заметим, что для случая равновероятностных состояний можно пользоваться любой из этих двух формул.
3. Энтропия.
Энтропию (обозначение Нр), как меру неопределенности источника сообщений, осуществляющего выбор из m состояний, каждое из которых реализуется с вероятностью рi, предложил Клод Шеннон.
Энтропия вычисляется по формуле:
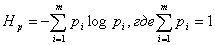
-logpi – количество информации, которое несет i- тое состояние сигнала есть величина случайная. Тогда, энтропия – это математическое ожидание информации, которое несет сигнал с m состояниями, каждое из которых имеет вероятность появления рi.
Энтропия позволяет сравнивать количества информации, приносимые различными сигналами.
4. Кодирование информации.
Для передачи и хранения информации используется код. Код имеет алфавит- набор символов и правила, по которым с помощью данного кода передается информация.
Известная со школьной скамьи десятичная позиционная система счисления – это способ кодирования натуральных чисел, декартовы координаты – способ кодирования геометрических объектов числами.
Алфавит может содержать любое количество символов. Простейший код состоит из двух символов (двоичный). Именно его используют в ЭВМ: алфавит состоит из 0 и 1. Примерами таких кодов являются азбука Морзе (точка и тире), светофор на железной дороге.
В общем случае, как уже отмечалось, символов может быть любое количество. В русском алфавите 32 буквы, т.е. 32 символа. Если учесть знаки препинания и пробелы, то символов становится больше.
Но разные символы применяются не одинаково часто. Например, в алфавите русского языка наиболее часто в текстах используются буквы а, о, и; самые редкие щ, э, ф. Следовательно, вероятности появления различных символов - различные. Возникает задача: создать наиболее экономичный код, т.е. такой код, у которого энтропия была бы наибольшей, т.е. наименьшим количеством символов передавать наибольшее количество информации.
Создавая коды, учитывают следующее: наибольшая энтропия соответствует сигналу (в нашем случае – коду), вероятности появления состояний которого одинаковы; простейшим является код из двух символов (выбор одного из двух равновероятностных состояний).
Код имеет следующие характеристики:
Экономичность- это отношение энтропии кода к максимальной энтропии в предположении, что все символы имеют одинаковую вероятность: Э =Н / Н мах;
Избыточность кода: И = 1 - Э. Данная характеристика показывает, какая часть символов лишняя и не несет информации.
Для оптимального кода экономичность близка к единице, а избыточность - к нулю.
Кроме экономичности и избыточности определяют цену кода, равную среднему числу битов на один символ (обозначение М(х)):
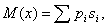
где pi – вероятность появления i- го символа в сообщении, si – длина кодовой последовательности, соответствующая i- му символу.
Рассмотрим примеры таких кодов.
Код Шеннона-Фэно.
Алгоритм построения кода:
1. Все символы записать в порядке не возрастания вероятностей.
2. Символы разбить на две группы с приближенно равными суммами вероятностей.
3. В левой группе символов коды начать с 0, в правой-с1.
4. Каждую группу снова разбить на две по такому же принципу и так же присвоить слева-0, справа-1.
5. Продолжать разбиения до тех пор,пока в каждой группе не останется по одному символу.
Алгоритм Хаффмена.
1. Все символы записать в порядке не возрастания вероятностей.
2. Объединить два редких символа в одну группу с вероятностью, равной сумме вероятностей этих символов.
3. Снова упорядочить список.
4. Повторять операции со второго шага, пока все символы не будут разбиты на две группы. В левой группе символов коды начать с 0, в правой- с1.
5. Затем работать с каждой группой следующим образом: отделять крайние символы, присваивая всегда слева 0, а справа-1, пока не будет закодирован каждый символ.
65. Тенденции построения современных графических систем: графическое ядро, приложения, инструментарий для написания приложений (свободен)
66. Уровни представления данных (Нурсиня)
67. Средства моделирования и модели, применяемые в процессе проектирования АСОИУ (свободен)
68. Основные понятия исследования операций и системного анализа (=3)
69. Самосинхронизирующиеся коды (Мирош)
70. Стандарты в области разработки графических систем (свободен)
71. Понятия схемы и подсхемы данных (свободен)
72. Аналитическое моделирование (свободен)
73. Методологические основы теории принятия решений (=8)
74. Способы контроля правильности передачи информации (Лиза)
75. Технические средства компьютерной графики: мониторы, графические адаптеры, плоттеры, принтеры, сканеры
Мониторы.
Монитор (дисплей) является универсальным устройством вывода информации.
Классификация:
• ЭЛТ – на основе электронно-лучевой трубки (англ. cathode ray tube,
CRT);
• ЖК – жидкокристаллические мониторы (англ. liquid crystal display,
LCD);
• плазменный – на основе плазменной панели;
• проекционный – видеопроектор и экран, размещённые отдельно или объединённые в одном корпусе (как вариант – через зеркало или систему зеркал);
• OLED-монитор — на технологии OLED (англ. organic light-emitting diode – органический светоизлучающий диод);
• виртуальный ретинальный монитор – технология устройств вывода, формирующая изображение непосредственно на сетчатке глаза.
Основные параметры мониторов:
• вид экрана — квадратный или широкоформатный (прямоугольный);
• размер экрана — определяется длиной диагонали;
• разрешение — число пикселей по вертикали и горизонтали;
• глубина цвета — число отображаемых цветов (от монохромного до 32-битного);
• размер зерна или пикселя;
• частота обновления экрана;
• скорость отклика пикселей (не для всех типов мониторов).
Графические адаптеры.
Графический адаптер (видео карта) – устройство, преобразующее графический образ, хранящийся как содержимое памяти компьютера (или самого адаптера), в форму, пригодную для дальнейшего вывода на экран монитора.
Обычно видеокарта выполнена в виде печатной платы (плата расширения) и вставляется в разъём расширения, универсальный либо специализированный (AGP, PCI Express). Также широко распространены и встроенные (интегрированные) в системную плату видеокарты — как в виде отдельного чипа, так и в качестве составляющей части северного моста чипсета или ЦПУ; в этом случае устройство, строго говоря, не может быть названо видеокартой.
Видеокарта состоит из следующих частей: графический процессор, видеоконтроллер, видео-ПЗУ, видео-ОЗУ, ЦАП, коннектор и система охлаждения.
Плоттеры.
Графопостроитель, плоттер – устройство для автоматического вычерчивания с большой точностью рисунков, схем, сложных чертежей, карт и другой графической информации на бумаге размером до A0 или кальке.
Типы графопостроителей:
• рулонные и планшетные;
• перьевые, струйные и электростатические;
• векторные и растровые.
Назначение графопостроителей: высококачественное документирование чертёжно-графической информации.
Принтеры.
Принтер – устройство печати цифровой информации на твёрдый носитель, обычно на бумагу. Относится к терминальным устройствам компьютера. Процесс печати называется вывод на печать, а получившийся документ – распечатка или твёрдая копия.
Принтеры бывают струйные, лазерные, матричные и сублимационные; по цвету печати: чёрно-белые (монохромные) и цветные. Иногда из лазерных принтеров выделяют в отдельный вид светодиодные принтеры.
Сканеры.
Сканер – устройство, которое, анализируя какой-либо объект (обычно изображение, текст), создаёт цифровую копию изображения объекта. Процесс получения этой копии называется сканированием.
Сканеры бывают различных конструкций:
• ручной,
• планшетный,
• барабанный,
• проекционный.
Изображение всегда сканируется в формат RAW – а затем конвертируется в обычный графический формат с применением текущих настроек яркости, контрастности, и т. д. Эта конвертация осуществляется либо в самом сканере, либо в компьютере – в зависимости от модели конкретного сканера. На параметры и качество RAW-данных влияют такие аппаратные настройки сканера, как время экспозиции матрицы, уровни калибровки белого и чёрного, и т. п.
76. Классификация информационно-вычислительных сетей (=5)
77. Планирование имитационных экспериментов с моделями (Ира)
78. Задачи выбора решений (=13)
79. Способы конструирования и верификации программ (свободен)
80. Способы коммутации в сетях (Лиза)
81. Оценка точности и достоверности результатов моделирования (свободен)
82. Функции полезности и критерии при принятии решений (17 – первый вариант)
Полезность – некоторое число, приписываемое лицом, принимающим решение, каждому возможному исходу. Функция полезности Неймана-Моргенштерна для лица, принимающего решение, (ЛПР) показывает полезность, которую он приписывает каждому возможному исходу. У каждого ЛПР своя функция полезности, которая показывает его предпочтение тем или иным исходам в зависимости от его отношения к риску.
В Задачах Принятия Решений (ЗПР) значение функции полезности выражает предпочтения, полезность альтернатив. Она может быть оценена на множестве альтернатив и на множестве критериев, при этом критерии могут быть взаимно независимыми и зависимыми.
Решение задачи выбора оптимального действия полностью определяется двумя факторами: 1) типом и объемом информации о состояниях и 2) критерием оптимальности альтернативы. Собственно говоря, критерий оптимальности также зависит от имеющейся информации о состояниях. Поясним более детально, что подразумевается под понятием информации о состояниях Информация о состояниях отражает степень уверенности в том, какое состояние будет в действительности иметь место, или степень уверенности, что одно состояние более вероятно по сравнению с другим. В то же время, множество самих состояний является известным. Информация о состояниях существенно влияет на решение задачи. Так, например, если с уверенностью 100% известно, что будет иметь место быстрый подъем экономики, то очевидно, что покупка акций предприятия даст наибольший доход. Рассмотренная ситуация является наиболее простой и приводит к принятию решений в условиях полной определенности. Другим крайним случаем является отсутствие какой-либо информации о состояниях. В этой ситуации имеет место задача принятия решений в условиях неопределенности. Это редкий случай, так как обычно, исходя из предыдущего опыта или наблюдений, а также текущих тенденций, можно с некоторой вероятностью говорить о будущих состояниях.
Каждая задача принятия решений имеет свой критерий оптимальности, т.е. некоторое правило, по которому численно определяется условие предпочтения одного действия по отношению к другому. Критерий оптимальности определяет упорядочивание всех альтернатов (множества А) по предпочтению.
При этом, как уже было сказано, критерий оптимальности полностью зависит от информации о состояниях.
Принятие решений в условиях определенности характеризуется однозначной или детерминированной связью между принятым решением и его результатом. Это наиболее простой класс задач принятия решений, когда состояние, которое будет определённо иметь место, известно заранее, т.е. до выполнения действия. ЛПР в данном случае может всегда точно предсказать последствия от выбора каждого действия. Это фактически означает, что число состояний сводится к одному, т.е. m = 1.
Поэтому логично потребовать от рационального лица, принимающего решение, выбрать то действие, которое дает наибольшее значение функции полезности.
В условиях неопределенности лицо, принимающее решение, не может сказать что-либо о возможных состояниях, т.е. абсолютно неизвестно, какое из состояний будет иметь место. Для решения данной задачи наиболее распространенными критериями принятия решений являются:
1) критерий равновозможных состояний (критерий Лапласа):
2) критерий максимина Вачьда:
3) критерий пессимизма-оптимизма Гурвица;
4) критерий минимакса сожалений Сэвиджа.
Следует отметить, что приведенные критерии являются далеко не единственными для принятия решений в условиях неопределенности. Однако остальные критерии являются в основном комбинацией этих критериев.
83. Универсальные ОС и ОС специального назначения (=26, Оля)
84. Модульные программы, пример.
Модульное программирование основано на понятии модуля - логически взаимосвязанной совокупности функциональных элементов, оформленных в виде отдельных программных модулей/
Модуль характеризуют:
один вход и один выход - на входе программный модуль получает определенный набор исходных данных, выполняет содержательную обработку и возвращает один набор результатных данных, т.е. реализуется стандартный принцип IPO (Input - Process - Output) - вход-процесс-выход;
функциональная завершенность – модуль выполняет перечень регламентированных операций для реализации каждой отдельной функции в полном составе, достаточных для завершения начатой обработки;
логическая независимость - результат работы программного модуля зависит только от исходных данных, но не зависит от работы других модулей;
слабые информационные связи с другими программными модулями - обмен информацией между модулями должен быть по возможности минимизирован;
обозримый по размеру и сложности программный элемент.
Программная система обычно является большой, поэтому принимаются меры для ее упрощения. Для этого такую программу разрабатывают по частям, которые называются программными модулями. Программный модуль - это любой фрагмент описания процесса, оформляемый как самостоятельный программный продукт, пригодный для использования в описаниях процесса. Это означает, что каждый программный модуль программируется, компилируется и отлаживается отдельно от других модулей программы, и тем самым, физически разделен с другими модулями программы. Каждый разработанный программный модуль может включаться в состав разных программ, если выполнены условия его использования, декларированные в документации по этому модулю. Таким образом, программный модуль может рассматриваться и как средство борьбы со сложностью программ, и как средство борьбы с дублированием в программировании.
Модульная структура программных продуктов
Принципы модульного программирования программных продуктов во многом сходны с принципами нисходящего проектирования. Сначала определяются состав и подчиненность функций, а затем - набор программных модулей, реализующих эти функции.
Однотипные функции реализуются одними и теми же модулями. Функция верхнего уровня обеспечивается главным модулем; он управляет выполнением нижестоящих функций, которым соответствуют подчиненные модули.
При определении набора модулей, реализующих функции конкретного алгоритма, необходимо учитывать следующее:
каждый модуль вызывается на выполнение вышестоящим модулем и, закончив работу, возвращает управление вызвавшему его модулю;
принятие основных решений в алгоритме выносится на максимально "высокий" по иерархии уровень;
для использования одной и той же функции в разных местах алгоритма создается один модуль, который вызывается на выполнение по мере необходимости. В результате дальнейшей детализации алгоритма создается функционально-модульная схема (ФМС) алгоритма приложения, которая является основой для программирования.
Пример
Во входном файле приведены координаты точек на плоскости. Необходимо составить из этих точек три треугольника максимальной площади и вывести их в выходной файл.
Какие модули можно выделить в данной задаче?
Есть следующие группы задач:
ввод-вывод (модуль file)
геометрия (модуль geometry) (для рассчета расстояния между двумя точками и нахождения площади по трем координатам)
поиск треугольников наибольшей площади (модуль search)
85. Одноранговые сети
Однора́нговая, децентрализо́ванная или пи́ринговая (англ. peer-to-peer, P2P — равный к равному) сеть — это компьютерная сеть, основанная на равноправии участников. Часто в такой сети отсутствуют выделенные серверы, а каждый узел (peer) является как клиентом, так сервером. В отличие от архитектуры клиент-сервера, такая организация позволяет сохранять работоспособность сети при любом количестве и любом сочетании доступных узлов. В этом случае, операционная система, называемая одноранговой, не только позволяет обращаться к ресурсам других компьютеров, но и предоставляет собственные ресурсы в распоряжение пользователей других компьютеров. Например, если на всех компьютерах сети установлены и клиенты, и серверы файловой службы, то все пользователи сети могут совместно применять файлы друг друга. Компьютеры, совмещающие функции клиента и сервера, называют одноранговыми узлами.
Одноранговые сети называют также рабочими группами. Рабочая группа - это небольшой коллектив, поэтому в одноранговых сетях чаще всего не более 10 компьютеров. Одноранговые сети относительно просты. Поскольку каждый компьютер является одновременно и клиентом, и сервером, нет необходимости в мощном центральном сервере или в других компонентах, обязательных для более сложных сетей. Одноранговые сети обычно дешевле сетей на основе сервера, но требуют более мощных (и более дорогих) компьютеров.
Одноранговая сеть характеризуется рядом стандартных решений:
компьютеры расположены на рабочих столах пользователей;
пользователи сами выступают в роли администраторов и собственными силами обеспечивают защиту информации;
для объединения компьютеров в сеть применяется простая кабельная система.
Одноранговая сеть вполне подходит там, где:
количество пользователей не превышает нескольких человек;
пользователи расположены компактно;
вопросы защиты данных не критичны;
потоки данных невелики;
в обозримом будущем не ожидается значительного расширения конторы и, следовательно, сети
Элементарная защита подразумевает установку пароля на разделяемый ресурс, например на каталог. Централизованно управлять защитой в одноранговой сети очень сложно, так как каждый пользователь устанавливает ее самостоятельно, да и ``общие'' ресурсы могут находиться на всех компьютерах, а не только на центральном сервере. Такая ситуация представляет серьезную угрозу для всей сети, кроме того, некоторые пользователи могут вообще не установить защиту. Одноранговая сеть является крайне неуправляемой с точки зрения системного администратора, и чем больше участников сети, тем более этот факт заметен. Например, чтобы ограничить работу пользователя с теми или иными устройствами, потребуется выполнить определенные настройки операционной системы. Сделать это централизованно невозможно, поэтому требуется личное присутствие администратора возле каждого компьютера либо применение программ удаленного управления компьютером.
| Преимущества сети | Недостатки сети |
| Простая и дешевая в создании | Отсутствует возможность административного управления пользователями и ресурсами |
| Не требует управляющих компьютеров | Каждый пользователь должен самостоятельно следить за состоянием программного обеспечения |
| Работа сети не зависит от работоспособности узлов сети | За обновление баз данных и другого программного обеспечения отвечает пользователь |
| легкость в установке и настройке | Отсутствует централизованное хранилище ресурсов |
| Низкий уровень защиты информации Возможность общего доступа не более 10 пользователям. |
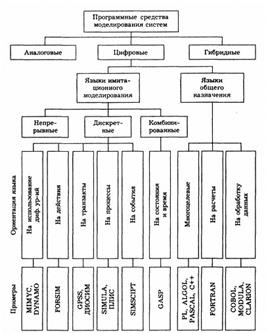
86. Инструментальные средства и языки моделирования
ХУЙНЯ – комментарий Макса
Чтобы реализовать на ЭВМ модель сложной системы, нужен аппарат моделирования, который в принципе должен быть специализированным. Он должен предоставлять исследователю:
- удобные способы организации данных, обеспечивающие простое и эффективное моделирование;
- удобные средства формализации и воспроизведения динамических свойств моделируемой системы;
- возможность имитации стохастических систем, т.е. процедур генерации ПСЧ и вероятностного (статистического) анализа результатов моделирования;
- простые и удобные процедуры отладки и контроля программы;
- доступные процедуры восприятия и использования языка и др.
Классические языки моделирования являются процедурно-ориентированными и обладают рядом специфических черт. Можно сказать, что основные языки моделирования разработаны как средство программного обеспечения имитационного подхода к изучению сложных систем.
Языки моделирования позволяют описывать моделируемые системы в терминах, разработанных на базе основных понятий имитации. Различают языки моделирования непрерывных и дискретных процессов.
Непрерывное представление системы S сводится к составлению уравнений, с помощью которых устанавливается связь между эндогенными и экзогенными переменными модели. Примером такого непрерывного подхода является использование дифференциальных уравнений. Причем в дальнейшем дифференциальные уравнения могут быть применены для непосредственного получения характеристик системы, это, например, реализовано в языке MIMIC. А в том случае, когда экзогенные переменные модели принимают дискретные значения, уравнения являются разностными. Такой подход реализован, например, в языке DYNAMO.
Представление системы S в виде типовой схемы, в которой участвуют как непрерывные, так и дискретные величины, называется комбинированным. Примером языка, реализующего комбинированный подход, является GASP, построенный на базе языка FORTRAN. Язык GASP включает в себя набор программ, с помощью которых моделируемая система S представляется в следующем виде. Состояние модели системы M(S) описывается набором переменных, некоторые из которых меняются во времени непрерывно. Законы изменения непрерывных компонент заложены в структуру, объединяющую дифференциальные уравнения и условия относительно переменных.
В рамках дискретного подхода можно выделить несколько принципиально различных групп языков имитационного моделирования. Первая группа языков имитационного моделирования подразумевает наличие списка событий, отличающих моменты начала выполнения операций, Продвижение времени осуществляется по событиям, в моменты наступления которых производятся необходимые операции, включая операции пополнения списка событий. Примером языка событий является язык SIMSCRIPT. Разработчики языка SIMSCR1FJ исходили из того, что каждая модель Мм состоит из элементов, с которыми происходят события, представляющие собой последовательность предложений, изменяющих состояния моделируемой системы в различные моменты времени.
Date: 2015-08-15; view: 838; Нарушение авторских прав