Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Обработка данных методики
|
|
Введенные в компьютер ответы испытуемого образуют матрицу данных, в которой строки и столбцы представляют собой оценки понятий по 18-ти шкалам. Затем матрица шкальных оценок понятий преобразуется в матрицу оценок понятий по трем факторам - ценности, потенции и активности.
Люди существенно различаются по стилю оценивания. Одни предпочитают давать более высокие оценки всем понятиям, другие – более низкие, одни стараются давать крайние, полярные оценки, другие – более умеренные, центральные. Субъективная точка отсчета (ноль) и единица измерения (деление шкалы) могут отличаться не только у разных испытуемых, но даже по разным шкалам и факторам у одного и того же испытуемого. Иными словами, каждый испытуемый в действительности пользуется своей субъективной шкалой, не совпадающей с предъявляемой, задавая тем самым подлинные границы используемого семантического пространства. Поэтому для того чтобы уравнять начало координат и цену деления осей, данные нормируются. Нормирование — это перевод балльных значений факторных оценок понятий в доли среднеквадратичного отклонения относительно среднего арифметического. Оно осуществляется по формуле:
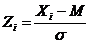
где Xi – значение i понятия по данному фактору в баллах, M – среднее арифметическое значение всех понятий по этому фактору, s – среднеквадратичное отклонение значений по этому фактору. Среднеквадратичное или стандартное отклонение, представляющее собой меру изменчивости значений фактора, рассчитывается по формуле:
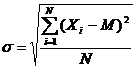
где Xi – значение i понятия по данному фактору в баллах, M – среднее арифметическое значение всех понятий по этому фактору, N — количество понятий.
В результате нормирования начало координат каждого фактора помещается в точку, соответствующую среднему арифметическому всех понятий (центрирование), а цена деления факторной оси соответствует единице стандартного отклонения значений (масштабирование). Такая индивидуальная стандартизация семантического пространства позволяет затем более эффективно сравнивать результаты разных испытуемых. Центрирование и масштабирование значений позволяет нивелировать междиндивидуальные и межфакторные различия в оценках понятий и дает возможность получить индивидуальную норму или эталон для измерения субъективных значений.
Далее матрица факторных оценок понятий преобразуется в матрицу расстояний между понятиями, характеризующих степень субъективного сходства каждого понятия со всеми другими понятиями. Таким образом, матрица расстояний представляет собой математическое выражение структуры ассоциаций в сознании человека. Семантическое расстояние между понятиями вычисляется по формуле:
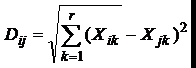
где Dij – евклидово расстояние между точками i и j в r-мерном пространстве признаков (факторов), k – порядковый номер признака (фактора), Xik и Xjk – координаты точек i и j по k-измерению или значения k-признака (фактора) i и j понятий. Чем больше сходство между понятиями, тем меньше расстояние между соответствующими точками. Матрица сходства между понятиями представляет собой квадратную таблицу N*N, симметричную относительно главной диагонали, поскольку Dij=Dji. Элементы главной диагонали представлены нулевыми значениями, поскольку Dii=0. Расстояния между понятиями также вычисляются не в виде условных балльных оценок шкалы семантического дифференциала, а в долях индивидуального размаха оценок, что позволяет более эффективно сравнивать расстояния между понятиями у разных испытуемых.
Матрица расстояний содержит полную информацию о структуре ассоциаций в сознании человека. Однако непосредственный анализ этой матрицы вызывает затруднения, связанные с ее большим объемом. Поэтому матрица расстояний между понятиями преобразуется в более простую и наглядную форму представления, позволяющую сократить избыточную информацию с помощью математического аппарата кластерного анализа. Кластерный анализ предназначен для объединения объектов, сходных по множеству признаков, в группы или так называемые кластеры. В основе кластерного анализа лежат методы автоматической классификации, или «распознавания образов без учителя». Свое название кластерный анализ получил от английского слова «cluster», означающего «гроздь». Существует большое количество алгоритмов кластерного анализа, не всегда, к сожалению, дающих одинаковые результаты. Простая кластеризация позволяет получить множество непересекающихся классов, исключающих друг друга, иерархическая кластеризация дает множество кластеров, включенных друг в друга в виде дерева, объединяя объекты в классы при различных уровнях сходства.
Достаточно простой, эффективный и наглядный алгоритм иерархического кластерного анализа заключается в последовательном попарном объединении наиболее сходных объектов. Среди матрицы расстояний N*N ищется пара наиболее близко расположенных точек. Соответствующие этим точкам объекты объединяются в кластер, причем, оба объекта, вошедшие в кластер, исключаются из дальнейшего анализа и заменяются одним. Вычисляются координаты точки, соответствующей этому кластеру и располагающейся точно посередине между двумя исходными точками. Перерасчитываются расстояния между вновь полученным кластером и остальными объектами. Таким образом, матрица расстояний сокращается на 1. Затем алгоритм повторяется сначала. При этом могут объединяться как точки, соответствующие отдельным объектам, так и точки, представляющие кластеры уже объединившихся ранее объектов. Данная процедура повторяется до тех пор, пока не останется всего один кластер.
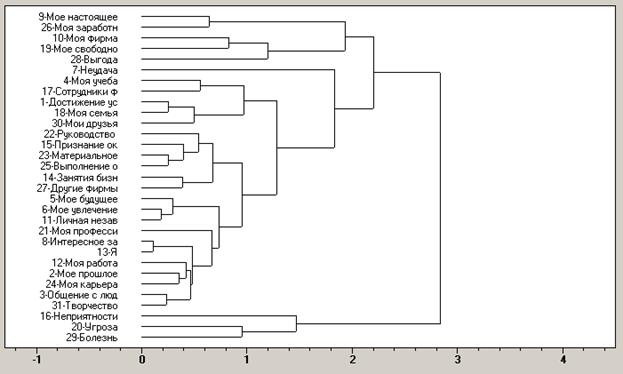
Рис. 1. Пример дендрограммы понятий
Результаты кластерного анализа могут быть наглядно представлены в виде дендрограммы, или дерева, где различные ветви соответствуют различным объектам и кластерам. Последовательное соединение ветвей выражает объединение соответствующих объектов или кластеров. При этом, чем ближе к вершине соединяются между собой ветви, тем более сходны между собой соответствующие этим ветвям кластеры. При этом не исключено, что кластер может состоять из одного-единственного объекта, если он слишком отличается от всех остальных. Таким образом, результаты иерархического кластерного анализа понятий в форме дендрограммы являются графическим представлением структуры их субъективной группировки в сознании испытуемого. Перемещаясь от основания дерева к вершине, можно последовательно выделять группы все более сходных понятий. При этом эмпирически установлено, что понятия, объединяющиеся на расстоянии менее одного стандартного отклонения, являются достаточно похожими, и их следует считать объектами одного кластера.
Date: 2015-07-27; view: 538; Нарушение авторских прав