Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Спецификация проблемы self-selection. Предпосылки и описание базовой модели Heckman
|
|
Проблема self-selection возникает, когда исследуемая модель прямо или косвенно включает в себя некий бинарный выбор, не учитываемый при построении регрессий. Пусть для некоторой случайной выборки компаний оценивается модель:
Yi = Xiβ + εi
где Yi – объясняемая переменная, которой чаще всего является выигрыш, выраженные прибыльностью или доходностью, Xi - вектор объясняющих переменных и εi – случайная ошибка. Если εi удовлетворяет классическим предпосылкам регрессионного анализа (теоремы Гаусса-Маркова?), то стандартная процедура OLS/GLS обеспечивает получение состоятельных оценок коэффициентов β регрессии.
Однако в случае анализа некоторой подвыборки компаний, сформированной на основе реализации данными компаниями выбора E, предпосылка о случайности выборки больше не выполняется и уравнение регрессии приобретает следующий вид:
Yi | E = Xiβ + εi | E
где больше не удовлетворяют классическим предпосылкам, что приводит к несостоятельности коэффициентов β в данной регрессии.
Решение проблемы self-selection включает два шага: сначала на основе экономической теории должна быть специфицирована модель, объясняющая от чего зависит принятие компаниями решения о выборе или не выборе E. Затем, на втором шаге строится регрессия зависимости объясняемой переменной Yi от случайной переменной выбора. От спецификации модели выбора на первой шаге и ее предпосылок строго зависит тип эконометрической модели используемой для эмпирического анализа на втором шаге.
Одной из наиболее популярных моделей выбора, применяемых в корпоративных финансах, особенно в более ранних работах является базовая модель Heckman – большая часть иных спецификаций может быть интерпретирована как ее расширение в различных направлениях.
Выбор (С) задается пробит моделью, в которой i-ая фирма выбирает E, если чистый выигрыш (W) от данного решения положителен и выбирает противоположное решение – NE, если чистый результат отрицательный. При этом часть выигрыша определяется публично доступной информацией:
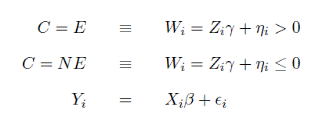
где Zi – вектор публично доступной информации об i-ой фирме, γ – вектор пробит коэффициентов, а ηi – вектор ортогональных остатков к переменной публичной информации Zi. Данная переменная может быть интерпретирован как частная, неофициальная информация, ненаблюдаемая исследователем, однако воздействующая на принятие или непринятие решения компанией.
Основной предпосылкой данной модели являются бивариантные нормальные ошибки εi и остатки ηi. Случаи невыполнения этого условия требуют альтернативных спецификаций модели, не основанных на нормальности распределения (Lee, 1982; Maddala, 1983, Newey, Powel & Walker, 1990) и встречаются в корпоративных финансах редко.
Применение моделей self-selection в исследовании «Disentangling the Dividend Information in Splits: A Decomposition Using Conditional Event-Study Methods» S. Nayak & R. Prabhala.
Данная работа посвящена анализу эффектов от объявлений о сплите акций и выплате дивидендов на стоимость акций. В основе исследования лежит метод событий, к которому относительно недавно стали применятся модели self-selection как инструмент включения в модель неофициальной (private) информации относительно событий.
Сплит акций долгое время являлся загадкой для исследователей, так как несмотря на то, что это простое дробление находящихся в обращении акций, не влияющее на экономические характеристики компании, существуют эмпирические доказательства того, что объявления о сплите акций положительно влияют на их стоимость.
Одним из предполагаемых объяснений такого поведения рынка является связанное со сплитом ожидание более высоких дивидендов. Целью данной работы являлось выявление взаимосвязи между сплитом акций и дивидендами, для достижения которой было проведено два типа тестирования.
В первой части исследования авторами сравнивались сплиты компаний, выплачивающих дивиденды, и компаний их не выплачивающих. Это было мотивировано результатами статьи Grinblatt, Masulis & Titman (1984), в которой предполагалось, что сплит повышает интерес к акциям данной компании, улучшая таким образом ее репутацию. Grinblatt, Masulis & Titman в своей работе нашли, что на фирмы, не выплачивающие дивиденды, сплит оказывает большее воздействие.
Авторы выдвигают две гипотезы: во-первых, это может происходить в силу того, что сплит является в некотором роде заменителем дивидендов как положительного сигнала рынка о состоянии компании. Во-вторых, причина может лежать в различных ожиданиях: выплачивающие дивиденды фирмы обыкновенно старше, устойчивее и менее волатильны, чем невыплачивающие, вероятность сплита которых меньше и соответственно производит больший эффект в силу своей неожиданности.
Далее была специфицирована статистическая модель выбора:
SPLi = θsXsi +ψsi
где i-ая фирма объявляет сплит, если SPLi > 0, что может быть интерпретировано как положительный выигрыш от объявления сплита. Часть этого выигрыша публично известна и зависит от некоторого вектора Xsi факторов, таких, например, как высокая номинальная цена акций. Другая часть выигрыша составляет ψsi и является внутренней, недоступной рынку частной информацией, при чем ее математическое ожидание до объявления о сплите равно нулю: E(ψsi) = 0. Как мы видим, данная спецификация модели выбора соответствует базовой модели Heckman.
В качестве вектора Xsi факторов решения о сплите, являющихся публичной информацией были выбраны: цена акций до события, размер компании, объем акций в обращении и изменение цены акции за последний год:
SPLi = θso +θs1* PR_PRICEi + θs2* SIZEi + θs3* VOLUMEi + θs4* RUNUPi + ψsi
где PR_PRICE - цена акции за пять торгуемых дней до сплита;
SIZE - натуральный логарифм рыночной стоимости собственного капитала компании за пять торгуемых дней до сплита;
VOLUME - объем акций как отношение среднего количества акций в обращении за месяц до сплита к общему количеству акций в обращении за пять дней до сплита;
RUNUP - отношение цены акции за пять дней до сплита к цене акции за один год до сплита.
Далее была построена и протестирована регрессия изменения доходности акций компании при условии сплита на ожидания относительно ненаблюдаемой информации о размере выигрыша компании от сплита:
E(ARi | S) = γs + βs*E(ψsi | θsXsi +ψsi > 0)
Date: 2015-07-27; view: 300; Нарушение авторских прав