Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Наследственные молекулы синтезируются матричным путем. В качестве матрицы, на которой строится ген будущего поколения, используется ген предыдущего поколения»
|
|
Это и есть аксиома биологии № 2. Кольцов продолжил цепь рассуждений биологов предыдущих веков. Если Франческо Реди в XVI веке сформулировал принцип Omne vivum ex vivo (все живое из живого), опровергающий возможность самозарождения жизни, то ХIХ век добавил принципы Omnis cellula ex cellula (каждая клетка из клетки) и Omnis nucleus ex nucleus (каждое ядро из ядра). И Кольцов завершает: Omnis molecula ex molecula – каждая молекула (имеется в виду «наследственная молекула») из молекулы.
Принцип матричного копирования был известен людям тысячи лет. Еще обитатели Шумера имели цилиндрические печати из твердого камня с вырезанными на них именами владельцев и различными рисунками. Прокатив такой цилиндрик по мягкой глине, древний шумер получал отчетливый оттиск рисунка и печати. На этом же приеме основана любая система точного и массового копирования сложных структур с закодированной в них информацией – будь то книгопечатание, чеканка монет или же изготовление фотооттисков с негатива. Представляется странным, что идею Кольцова о матричном синтезе генов поддержали в 20–30‑е годы лишь немногие.


Рис. 13. Принцип матричного копирования был известен уже тысячи лет назад древним шумерам. Прокатив валик‑печать по мягкой глине, состоятельный шумер ставил свою печать на документе. Уже тогда четыре с половиной тысячи лет назад люди додумались, что печать должна быть комплементарна отпечатку – выпуклостям соответствуют впадины, вместо нормальных клинописных знаков даны их зеркальные отображения. Но природа «изобрела» матричное копирование более чем за три миллиарда лет раньше, оно было первым завоеванием жизни и ее необходимым условием.
Но она была уже пущена в научный обиход. Ученик Н. К. Кольцова Н. В. Тимофеев‑Ресовский познакомил с ней физика М. Дельбрюка. Э. Шредингер в своей книге «Что такое жизнь с точки зрения физика?» идею матричного синтеза по ошибке приписал Дельбрюку (ошибка через год была исправлена генетиком Дж. Б. С. Холдейном в рецензии на книгу Шредингера в журнале «Нейчер»).
Возможно, Шредингер считал эту идею уже широко распространенной, чуть ли не общепринятой в среде биологов и сослался на последние работы в этом направлении, как это часто водится. Ошибка простительная, тем более что Н. В. Тимофеев‑Ресовский и М. Дельбрюк иногда работали вместе.
А в 1953 году, через тринадцать лет после смерти Н. К. Кольцова в том же журнале появилась краткая статья физика Ф. Крика и ученика Дельбрюка – генетика Дж. Уотсона.
Крик и Уотсон расшифровали структуру «наследственной молекулы» и показали, что в ней самой заложена способность к матричному копированию. Но «веществом наследственности» оказался не белок, а дезоксирибонуклеиновая кислота – всем известная ныне двойная спираль ДНК.
Почему же ДНК? Почему же Кольцов, гениально предугадав необходимость матричного синтеза гена, ошибся в выборе материала для него? Все дело заключалось в несовершенстве тогдашних микроскопических методик. Уже была известна отличная реакция на нуклеиновые кислоты – реакция Фёльгена, окрашивавшая ядра клеток и хромосомы в ядрах в малиново‑красный цвет. Однако когда ДНК между делениями клеток равномерно распространялась по ядру, окраска была слабой, почти незаметной. Так мы можем видеть катушку ниток и не заметить нитку той же длины размотанную по поверхности большого ковра. Поэтому большинство исследователей полагало, что ДНК из ядра в промежутке между делениями вообще исчезает. А ведь согласно идее матричного синтеза ген не может возникать заново.
Кстати, может ли последовательность аминокислот размножаться матричным путем? Как удалось установить в природе – нет. И все же… Кольцов оказался не так уж и не прав.
Вот как он представлял процесс «размножения» молекулы: «…всякая (конечно, сложная органическая) молекула возникает из окружающего раствора только при наличии уже готовой молекулы; причем соответствующие радикалы помещаются… на те пункты имеющейся налицо и служащей затравкой молекулы, где лежат такие же радикалы». Такой процесс удалось воспроизвести в опыте.
Есть такая аминокислота – глутаминовая. Именно она придает специфический привкус сухим пакетным супам (туда добавляют ее натриевую соль). Она может существовать, как всякое органическое соединение с асимметричным атомом углерода, в двух формах, условно названных «правой» и «левой». Природные белки содержат только левые аминокислоты.
Как и любую аминокислоту, глутаминовую можно полимеризовать. При этом возникает длинная монотонная цепочка Глу–Глу–Глу–Глу – полиглутаминовая кислота, так же напоминающая природный белок, как звон будильника – музыку.
Растворим полиглутаминовую кислоту (из левых форм) в водной щелочи при 100° и добавим в реакционный сосуд смесь правой и левой формы глутаминовой кислоты. При охлаждении раствора происходит процесс, удивительно напоминающий тот, который описал Кольцов. Молекулы глутаминовой кислоты присоединяются к звеньям полимера, полиглутаминовая кислота служит матрицей. Под действием облучения между этими молекулами возникают пептидные связи – сшивки. Так образуется новая молекула полиглутаминовой кислоты, построенная на матрице старой. Чем это не размножение молекул по Кольцову?
К тому же матрица выбирает материал для постройки копии – только левую форму. В принципе возможен выбор нужной молекулы и из смеси разных аминокислот. Казалось бы, таким способом может размножаться и настоящий белок.
Однако дело обстоит не так просто. Если мы повысим концентрацию аминокислоты или же быстрее будем охлаждать раствор, избирательность синтеза сразу исчезает. Точной копии полимерной молекулы таким способом получит нельзя.
Причина этого – природа связей, которыми одиночные молекулы глутаминовой кислоты присоединяются к матричному полимеру. Такие связи называют водородными. Ион водорода наиболее электроположителен, поэтому он охотно образует связи с электроотрицательными партнерами (вспомните хотя бы ион аммония NH4+). Не будь водородных связей между молекулами воды, она кипе бы при гораздо более низкой температуре, лед бы тонул в воде, и уже поэтому жизнь на Земле была бы невозможной.
Но этого мало. Эффект водородных связей имеет для жизни гораздо большее значение. Именно они определяют так называемую вторичную структуру молекул белков и нуклеиновых кислот.
В белках водородные связи образуются между кислородом в группировке CO–NH и водородом в амидной группе NH. Остатки любых аминокислот могут реагировать с любыми же, водородные связи в белках неспецифичны. Именно поэтому матричный синтез полиглутаминовой кислоты теряет специфичность, как только мы пытаемся его ускорить. А непреложное условие точного матричного копирования – точное спаривание молекул.
Белки – плохие матрицы, и поэтому они не могут размножаться сами.
А нуклеиновые кислоты? Вспомним их строение. Это, как и белки, длинные молекулы полимеров. Но в отличие от белков звенья полимера – не аминокислоты, а нуклеотиды –сахара‑пентозы, к которым присоединены азотистые основания – гуанин, аденин, цитозин и тимин (в РНК тимин заменяется урацилом). Связываются звенья нуклеотидов фосфодиэфирными связями остатка фосфорной кислоты H3PO4.
Полипептидные цепи белков могут соединяться попарно водородными связями – это так называемая бета‑структура белка. Но, как уже упоминалось, эти связи неспецифичны. Иное дело нуклеиновые кислоты. Здесь термодинамически выгоднее образование пар аденин – тимин (или аденин – урацил) и гуанин – цитозин. Эти пары называют каноническими. Все другие в обычных условиях неустойчивы. Поэтому в двойной спирали ДНК против гуанина в одной цепи всегда стоит цитозин в другой, а против аденина – тимин. И когда на одиночной цепи, как на матрице, строится новая, точность синтеза оказывается удовлетворительной для передачи генетической информации из поколения в поколение.

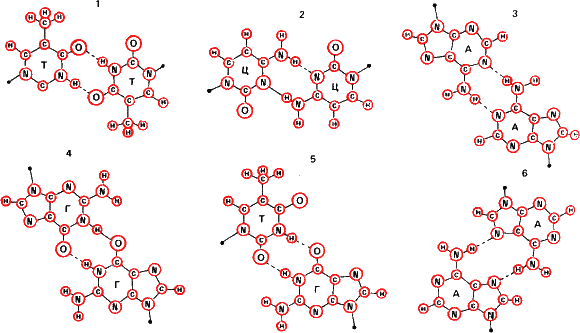
Рис 14. Почему матрицами жизни стали нуклеиновые кислоты? Потому что пары оснований А – Т (и А – У для комплексов ДНК – РНК и РНК – РНК) и Г – Ц наиболее термодинамически стабильны. Они показаны наверху, расстояние между основаниями дано в нанометрах, водородные связи показаны пунктиром. Все другие пары оснований (Т – Т. Ц – Ц, А – А, Г – Г, Т – Г), показанные на нижней часта рисунка, как минимум в десять раз менее прочны, чем пара А – Т и А – У. А пара Г – Ц самая стабильная из всех. Поэтому в точности спаривания оснований в ДНК и отсюда в точности матричного синтеза нет ничего удивительного или сверхъестественного. Это чистая термодинамика.
Мы видим существенное отличие от схемы Кольцова: согласно ей подобное притягивается к подобному, глутаминовая кислота – к остатку глутаминовой же кислоты в нашем опыте. При матрицировании ДНК (и РНК вирусов) притягиваются противоположные основания, комплементарные, образующие наиболее устойчивые пары с минимумом свободной энергии. Цепи в двойной спирали можно уподобить негативу и позитиву. Напомним, кстати, что и типографский шрифт, и печати, и чеканы для монет тоже не идентичные копии отпечатков, а их зеркальные отражения.
Как и при формулировке первой аксиомы, подчеркнем: главное не материальный субстрат, а матричный принцип его синтеза. Да, в земных условиях белки оказались плохими матрицами, а нуклеиновые кислоты хорошими. Но из этого не следует, что на других планетах во Вселенной дело обстоит так же. Гены там могут состоять из других соединений (каких, нам пока неведомо), но размножаться они должны, как и на Земле, матричным путем. Иначе мы опять попадем между преформизмом и эпигенезом, так что такая категоричность вполне обоснована.
Но мы живем на Земле. Поэтому сейчас мы должны вспомнить, как генетическая информация кодируется в нуклеиновых кислотах и как она трансформируется в молекулы белков. Это нам пригодится в дальнейшем. Рассмотрим принципы генетического кода – языка жизни. Ибо, как сказал Козьма Прутков: «…не зная законов языка ирокезского, можешь ли ты делать такое суждение по сему предмету, которое не было бы необоснованно и глупо?»
Алфавит белков. Уже говорилось, что аминокислотой может называться любое соединение, содержащее аминный(–NH2) и карбоксильный (–COOH) радикалы. Отсюда следует, что число возможных аминокислот должно быть очень велико, практически бесконечно. Тем более удивительно, что природа для построения белковых молекул использует из всего этого, не поддающегося учету разнообразия всего лишь двадцать аминокислот.
Это так называемые «магические». Может быть, по каким‑то неясным причинам только они годятся для использования в жизненных процессах? Нет, аминокислоты, не входящие в число «магических», можно обнаружить в составе организмов, но только не в белках. Таковы, например, тироксин (известный гормон щитовидной железы) или же норвалин (α‑аминомасляная кислота). Некоторые аминокислотные остатки, уже входя в состав белковой молекулы, модифицируются. Присоединив остаток фосфорной кислоты, серин превращается в фосфосерин (в казеине молока и пепсине желудочного сока).
Или же набор белковых аминокислот отражает их большую вероятность возникновения в период происхождения жизни? Трудно однозначно ответить на этот вопрос: ведь мы не можем точно восстановить условия, существовавшие на Земле четыре миллиарда лет назад. Однако в многочисленных опытах, моделировавших самые различные пути становления органических веществ из неорганических (таких, как вода, аммиак, углекислый газ, метан, водород и др.), удалось синтезировать большой набор аминокислот, гораздо более разнообразный, чем тот, который составляют двадцать «магических».
Да и сам анализ алфавита белков наводит на размышления. Все «магические» аминокислоты можно разделить на такие группы:
1. Производные углеводородов. В этом случае аминогруппа и кислотный радикал присоединяются к углеводороду из одного, двух, трех или четырех звеньев. Таковы глицин (Гли), аланин (Ала), валин (Вал), лейцин (Лей) и изолейцин (Илей). В дальнейшем мы будем пользоваться этими сокращениями.
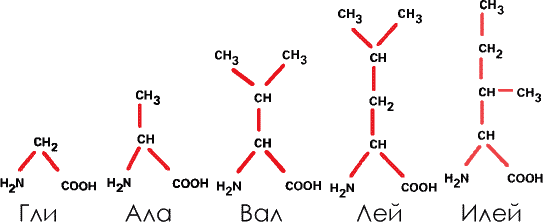
В эту группу входит единственная аминокислота, не содержащая асимметричного атома углерода (глицин). В прочих атомы углерода содержат разные радикалы, асимметричны, и потому эти аминокислоты могут быть представлены в правых и левых формах (а в белках – только в левых).
2. Кислые аминокислоты. Этот термин, напоминающий «масло масляное», означает, что они содержат еще один радикал –COOH, кроме того, который образует пептидную связь. Они и в белке сохраняют кислотные свойства. Это уже упоминавшаяся глутаминовая кислота (Глу) и аспарагиновая (Асп):
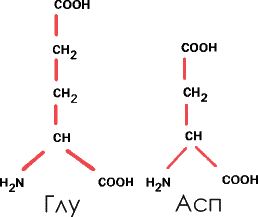
В некоторых белках вместо этих аминокислот имеются их амиды – глутамин и аспарагин. В таких случаях к боковой карбоксильной группе –COOH присоединяется молекула аммиака, и остаток вместо кислотных приобретает основные свойства:

Сокращенно их называют Глу N и Асп N, или же проще Глн и Асн. Так что, строго говоря, выражение «двадцать магических аминокислот» не совсем точно. В счет их входят и две простые аминокислоты и два их амида.
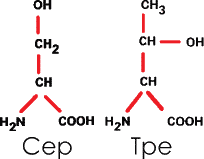
З. Содержащие оксигруппу –OH. Таковы серин (Сер) и треонин (Тре):
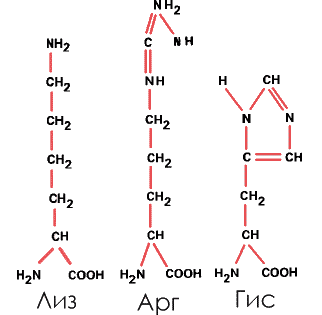
4. Основные – с аминогруппой в боковом радикале. Таковы лизин (Лиз), аргинин (Арг) и более сложная, содержащая имидазольную группу аминокислота гистидин (Гис):
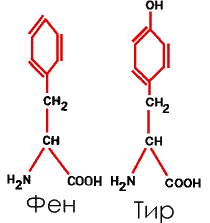
5. Ароматические, с бензольными кольцами в боковых радикалах – фенилаланин (Фен или Фал) и тирозин (Тир)
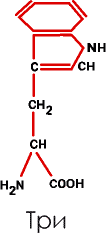
6. Группа гетероциклических (индолсодержащих) аминокислот включает лишь триптофан (Три):
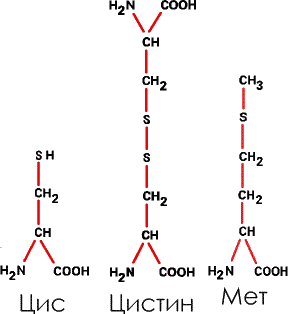
7. Зато целых три аминокислоты содержат в боковых радикалах атомы серы – это цистеин (Цис) цистин (димер цистеина, две молекулы цистеина «сросшиеся» вместе) и метионин (Мет):
8. И наконец, две аминокислоты, которым, строго говоря, не хватает одного атома водорода, чтобы так называться. У них аминная группа превращается в иминную, образуя пиррольное кольцо. Таковы иминокислоты пролин (Про) и его производное – оксипролин, то есть пролин, содержащий оксигруппу –OH:

Добавим, что оксипролин и цистин возникают уже в белке из пролина и цистеина.
Вот из этих‑то двадцати букв аминокислотного алфавита возникло чудовищное, не поддающееся учету разнообразие белковых молекул. Все могут белки: ускорять химические реакции и быть материалом для шерсти, волос и рога, переносить кислород железо и медь убивать бактерии, обезвреживать вирусы и яды, слагать оболочки клеток и распознавать другие клетки, сокращать мускулы и вызывать холодное свечение клеток. Одного не могут – размножаться сами. Информация об аминокислотных последовательностях в белках закодирована в нуклеотидных последовательностях ДНК и РНК.
И глядя на набор «магических» аминокислот, трудно отделаться от впечатления, что этот выбор природы случаен. Так уж получилось, что первые нуклеиновые кислоты приобрели способность к матричному синтезу полипептидных цепочек из двадцати магических». И этого оказалось достаточно, дальнейшее обогащение алфавита было просто не нужно.
А вот почему все аминокислоты в белках левые? Так, по‑видимому, удобнее для матричного синтеза. Некоторые организмы синтезируют довольно сложные пептидные цепочки специального назначения нематричным путем. Таковы, например, некоторые антибиотики типа грамицидина или же пептиды, слагающие оболочки бактерий. В них жесткие запреты матричного синтеза снимаются, используются иные аминокислоты, кроме «магических», как в левой, так и в правой форме.
Вот как выглядит молекула грамицидина С:

Достаточно одного взгляда на схему этой кольцевой молекулы, чтобы убедиться в невозможности ее синтеза на нуклеиновой матрице. Ведь в нее входят два остатка орнитина (Орн) – аминокислоты, не числящейся в магических и правый фенилаланин (d – фен). Действительно, синтезируют грамицидин С два фермента: один соединяет в цепочки две пятичленные последовательности, а другой сшивает их в кольцо. Вот эти ферменты синтезируются уже «настоящим» матричным путем.
Или же когда мы обнаруживаем в стенках капсул сибиреязвенной бациллы полипептид, состоящий из глутаминовой кислоты, мы вправе предположить, что он синтезируется нематричным путем. Ведь, во‑первых, глутаминовая кислота в нем правая, во‑вторых, пептидная связь образована в нем боковой (так называемой γ – карбоксильной) группой.
Но эти, как и другие подобные примеры, лишь подтверждают важность матричного синтеза. Без ферментов и здесь дело не обходится. И мы переходим к важному вопросу: молекулы белков состоят из двадцати аминокислот (точнее, аминокислотных остатков) в разных комбинациях. Молекулы нуклеиновых кислот собраны из четырех сортов нуклеиновых оснований. Каким сочетанием нуклеотидов в ДНК кодируется каждая из аминокислот? Каковы принципы генетического кода?
Генетический код. При слове «код» у любителей приключенческой литературы возникают определенные ассоциации. Но принцип кодирования известен не только разведчикам.
Каждый грамотный человек всю жизнь занимается перекодировкой информации.
Наше письмо – тоже код, в котором определенные символы‑буквы соответствуют определенным звукам. В этом смысле можно уподобить буквы сочетаниям нуклеотидов в ДНК, а звуки – аминокислотам в белке. Между буквой и звуком нет какого‑либо соответствия, кроме исторического. В этом и есть принцип кодирования. На пример, почему звук «А» мы обозначаем соответствующей буквой? Только потому, что древние греки позаимствовали из алфавита финикийцев знак α (видоизмененный знак – от семитского «алеф» – бык.[5]
Это схематический рисунок головы быка). Если бы наши предки‑славяне придумали алфавит сами, этот символ означал бы, наверное, не «А», а «Б» (бык) или «Г» (говядо – древнеславянское «бык»). Обозначают же японцы в своей слоговой азбуке – катакане звук «А» символом
– и ничего, понимают, потому что знают этот код. Так же как знаем свой код мы и как нуклеиновый код «знают» белоксинтезирующие системы клетки. Я подчеркиваю: именно клетки, потому что бесклеточные формы жизни – вирусы при стройке своих белков используют белоксинтезирующие системы хозяев.
Так как «магических» аминокислот двадцать, а оснований нуклеиновых кислотах всего четыре ясно, что каждое звено белковой цепи кодируется несколькими нуклеотидными звеньями, а именно тремя. Число сочетаний из четырех по три равняется 64. Стало быть, в коде ДНК 64 «буквы». Три из них соответствуют пробелам в типографском наборе. В средние века текст писали сплошняком, без пробелов, что, наверное, затрудняло чтение и сейчас создает трудности при расшифровке. Так, написанную слитно фразу из «Слова о полке Игореве» «исхотиюнакроватьирек» толковали «и схоти ю на кровать и рек…» или же «и схоти юнак ров (то есть могила. – Б. М.) а тьи рек». Если же сплошняком будет набран аминокислотный текст, смысла в подобном синтезе не будет. На бессмысленных, не соответствующим никаким аминокислотам сочетаниях нуклеотидов синтез обрывается – полипептидная цепочка готова.
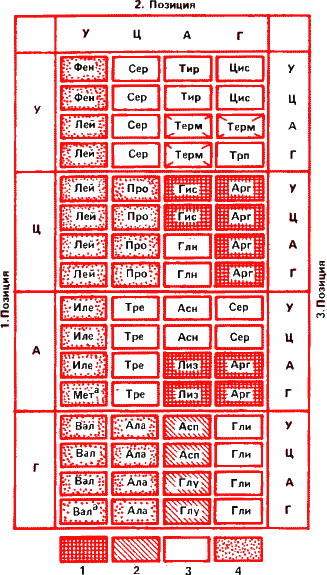
Рис. 16. Быть может, величайшее достижение биологии ХХ века – расшифровка генетического кода. На таблице показано, каким аминокислотам в белке соответствуют триплеты нуклеотидов в матричной РНК. Например, если в первой позиции стоит урацил, во второй цитозин и в третьей гуанин, то это сочетание кодирует аминокислоту серин. 1 – аминокислоты с положительно заряженной боковой цепью; 2 – отрицательно заряженные; З – полярные (имеющие сродство к молекулам воды); 4 – неполярные, гидрофобные, отталкивающие воду. Терм – терминирующие бессмысленные кодоны. На них синтез белка прерывается.
Остальные 61 триплет (кодон) соответствуют 20 аминокислотам. Такой код, когда несколько букв читаются одинаково, называется вырожденным. Например, лейцин, серин и аргинин кодируются шестью триплетами; пролин, валин и глицин – четырьмя; изолейцин – тремя; аспарагиновая и глутаминовая кислоты – двумя, а для метионина имеется лишь один кодон. Он же, если стоит в начале гена, исполняет роль заглавной буквы.
Это похоже на ситуацию в дореволюционном русском алфавите: тогда существовало два символа для звука «ф» (ферт и фита) и целых три для «и» («и» просто, «и» с точкой и ижица).
Первые исследователи полагали, что аминокислотные цепочки прямо собираются на нуклеотидных цепочках. Дело оказалось гораздо сложнее.
Во‑первых, нет никакого стерического (морфологического) соответствия между кодоном и той аминокислотой, которую он кодирует. Соответствие между ним и достигается молекулой особой нуклеиновой кислоты, которую называли по‑разному: РНК – посредник, адаптор, растворимая и, наконец, транспортная. На одном ее конце присоединена аминокислота, а на другом расположена последовательность комплементарная кодону (антикодон).
Во‑вторых, матрицей для белкового синтеза служит не непосредственно ДНК, а копируемый с нее «рабочий чертеж» – РНК, получившая название информационной или матричной (мРНК).
Итак, мы должны различать процессы: матрицирование самого гена, то есть синтез ДНК на ДНК, синтез мРНК на ДНК и синтез белка на матрице мРНК. Первый процесс называется репликацией, второй – транскрипцией и третий – трансляцией.
Еще короче это выражается в так называемой «центральной догме» молекулярной биологии:
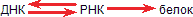
В предисловии я обещал строго придерживаться того набора фактов, которого требует школьная программа. Однако некоторые положения в ней излагаются слишком сжато, иные неверно, а многие любопытные достижения последних лет просто еще не дошли до учебников. Теперь самое время на них остановиться.
Полярность гена. Длинные цепочечные молекулы биополимеров – полипептидов и нуклеиновых кислот – полярны. Иными словами начало и конец цепи аминокислотных остатков и нуклеотидов различаются друг от друга.

Рис. 15. Схема строения двухцепочечной ДНК и комплементарной ей РНК. Для простоты ДНК показана не закрученной в спираль, какой она обычно бывает в клетке. Такой участок может кодировать две аминокислоты – серин и цистеин. Ф – остаток фосфорной кислоты, А, Г, Ц, Т, У соответственно аденин, гуанин, цитозин, тимин, и урацил. Нетрудно видеть что смысловая цепь и комплементарная ей антипараллельны. 3’– конец одной стыкуется с 5’‑концом другой. Синтез матричной РНК начинается 3’– конца смысловой цепи. Следовательно мРНК Нужно «читать» с 5’‑конца. С него и начинается белковый синтез. Нагляднее принцип антипараллельности цепей дан на шуточной схеме внизу. Теперь представим себе, что обе нарисованные внизу змеи свернутся в кольцо и каждая возьмет в зубы собственный хвост, и мы получим точную копию кольцевой хромосомы некоторых фагов и бактерий.
Нетрудно сообразить, почему полярны полипептиды, слагающие белки. Уже упоминалось, что аминокислоты имеют две функциональные группировки, сшивающие их в полипептид, – аминную и карбоксильную. Значит, у первого звена аминокислотной последовательности остается свободной аминная группа (–NH2), а у последнего – карбоксильная (–COOH). Так и говорят: N – конец и C – конец полипептида.
Полярны и нуклеиновые кислоты, но по другой причине. Остов как РНК, так и ДНК –пятичленные сахара – пентозы, сшитые остатками фосфорной кислоты (фосфодиэфирные связи). Чтобы различать атомы углерода в пятиугольнике пентозы, химики пронумеровали их, считая от того, к которому присоединено азотистое основание. Оказалось, что в природных нуклеиновых кислотах фосфодиэфирные связи образуются только между третьими и пятыми атомами углерода в пентозах (сокращенно: 3’ и 5’; читается: «три‑штрих» и «пять‑штрих»). Поэтому на одном конце любой нуклеиновой кислоты сахар присоединен к цепи 3’‑атомом, на другом – 5’.
А теперь зададимся вопросом: в какую сторону «читается» ген – к 3’ или 5’? Теперь, когда генные инженеры уверенно расшифровывают нуклеотидные последовательности и синтезируют их, это вопрос отнюдь не праздный.
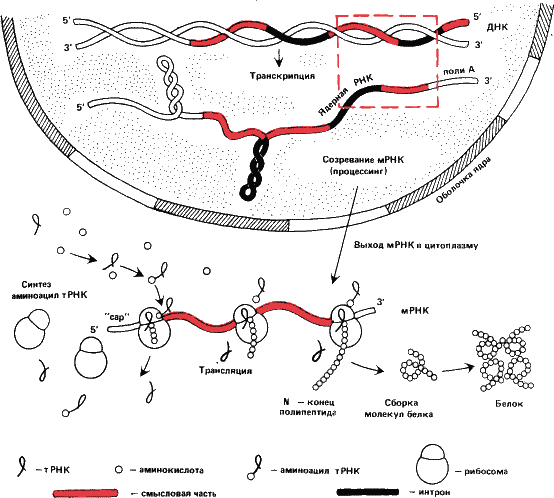
Рис. 17. Упрощенная схема передачи генетической информации с ДНК на белок. С находящейся в ядре ДНК снимается «рабочая копия» гена – гетерогенная ядерная РНК (этот процесс называется транскрипцией). Значительная, как правило, большая ее часть не кодирует аминокислотных последовательностей и отрезается ферментами – эндонуклеазами и отбрасывается. Тогда же вырезаются и «нечитаемые» вставки – интроны. Созревшая мРНК, получившая «шапочку» (cap – англ.) на 5’‑конце и полиадениловую последовательность на З’‑конце, через пору в ядерной оболочке выходит в цитоплазму (часто в виде комплексов с белком – информофер или информосом, на рисунке не показанных). В цитоплазме информация считывается с мРНК белоксинтезирующими аппаратами клетки – рибосомами (трансляция). Рибосомы гуськом идут по мРНК: каждый раз, когда рибосома смещается на три нуклеотида к З’‑концу, к растущей полипептидной цепи прибавляется один аминокислотный остаток. Аминокислоты доставляются к рибосомам молекулами транспортной РНК (мРНК). Отдав аминокислоту, мРНК образует снова комплекс (аминоацил – мРНК) с другой и снова вовлекается в процесс. Полипептидная цепочка, оборвавшись на бессмысленном, терминирующем кодоне, свертывается специфичным образом. Это вторичная структура белка, поддерживаемая водородными связями; обычно это однонитчатая спираль (спираль Полинга – Кори). Спираль, в свою очередь, складывается, образуя третичную структуру. Наконец, многие белки состоят из более чем одной полипептидной цепи. Таков, например, гемоглобин, молекула которого состоит из четырех субъединиц. Это четвертичная структура.
Установлено, что полипептидные цепи в клетках синтезируются от N – конца к C – концу. Значит, у матричной РНК начало там, где кодируется N ‑ конец. Оно соответствует 5’‑концу РНК. В двойной спирали ДНК разобраться труднее. Дело в том, что слагающие ее нуклеотидные цепочки направлены в разные стороны, как говорят, антипараллельны. Иными словами, одна цепь направлена в сторону З’–5’, а другая 5’–З’.
Смысловая цепь, в которой закодирована аминокислотная последовательность «считывается» ферментом РНК‑полимеразой с З’‑конца. Образующаяся при этом мРНК, естественно, оказывается точным аналогом комплементарной цепи и будет начинаться с 5’‑конца, с того, с которого начинается трансляция, то есть белковый синтез.
Но ведь с гена снимается не только «рабочий чертеж» мРНК. Ген и реплицируется, передаваясь из поколения в поколение, от матричной клетки к дочерним. Осуществляет этот процесс – репликацию – фермент ДНК полимераза.
Считается, что молекула ДНК‑полимеразы садится на ДНК и движется по ней. При этом удваивается и смысловая цепь, и комплементарная к ней. Значит репликация смысловой цепи начинается с 3’‑конца, как и транскрипция. Это аналогично тому как если бы мы перепечатывали текст с конца, а читали его, как и водится, с начала. В учебниках и популярных изданиях на это, как правило, не обращают внимания.
Последние годы ознаменовались сенсационными открытиями в изучении процессов репликации и трансляции. Природа подносила нам сюрприз каждый раз, когда начинало казаться, что уж теперь мы знаем об этих явлениях все.
Вот некоторые из сенсаций, за молодостью не попавшие в учебники.
Справедлива ли центральная догма? Мы уже упоминали, что генетическая информация передается от ДНК через РНК на белок, но не в обратную сторону. Это положение назвали центральной догмой молекулярной биологии. РНК‑содержащие вирусы ее не нарушают. Просто у них выпадает начальное звено этой цели – ДНК. Генетическая информация передается из поколения в поколение закодированной в последовательностях РНК, с них же и считывается белок.
В принципе разница между ДНК и РНК не так уж и велика. Пентознофосфатный остов у РНК образует другой сахар – рибоза, который отличается от дезоксирибозы лишь наличием гидроксильной группы (OH). Набор оснований тот же, за тем исключением, что вместо тимина (5‑метилурацила) в РНК содержится урацил (тот же тимин, только неметилированный). Недаром в природе встречаются ДНК, в состав которых входят и дезоксирибозы и рибозы. Такова, например, ДНК вируса герпеса, от которого на губах «высыпает лихорадка». Энергетические фабрики клеток – митохондрии – в значительной степени генетически автономны от ядра, они имеют свой геном, похожий на бактериальный. ДНК этого генома также содержит рибозу – от десяти до тридцати остатков на молекулу.
Все это не нарушало стройную догму. Тем большее смятение вызвало открытие синтеза ДНК на РНК. С. М. Гершензон писал еще в 1960 году о возможности подобного процесса, однако лишь сравнительно недавно был получен в значительных количествах фермент ревертаза (обратная транскриптаза), осуществляющий эту реакцию. Теперь этот фермент – обычный инструмент генных инженеров. Теперь мы можем дополнить центральную догму:
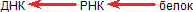
Например, РНК‑содержащий вирус птичьего миэлобластоза может в результате обратной транскрипции стать ДНК‑содержащим, встроиться в геном цыпленка и вызвать злокачественное перерождение клеток. Какую роль играет синтез ДНК на нити РНК в мире высших организмов, нам пока еще неизвестно.
Смысловая цепь: одна или две? Каких‑нибудь пять лет назад все мы были твердо уверены, что матричная РНК синтезируется только на одной из двух цепей ДНК, получившей название смысловой. Вторая, комплементарная ей цепь нужна лишь для репликации ДНК и репарации – «починки» поврежденных участков. Если, например, жесткая радиация вырвет кусок из одной из цепей двойной спирали, специальные ферменты – репаразы заполняют брешь, пристроив на ее месте последовательность нуклеотидов, комплементарную оставшейся.
И тем не менее в последнее время появились данные, свидетельствующие о том, что в геноме дрозофилы, например, синтез РНК может идти на обеих цепях ДНК. Это так называемый симметричный синтез. Любопытно, что он идет от одной точки в разные стороны: в каждой цепи от З’ к 5’‑концу, так что обе образующиеся РНК начинаются с 5’‑конца. Биологический смысл этого явления мы еще не знаем.

Рис. 18. Вверху – первичная структура белка лизоцима, разрушающего оболочки бактерий. Обратите внимание на четыре сшивки цис – цис (дисульфидные связи, которые мы уже видели на рис. 3). Внизу же не абстрактная скульптура, а модель третичной скульптуры лизоцима, полученная методом рассеивания рентгеновских лучей.
Перекрывается ли код? Первые гипотетические модели кода были перекрывающимися Это значило, что последовательность нуклеотидов могла кодировать разные аминокислотные последовательности, в зависимости от начала считывания. Так, последовательность АТТГЦАТЦГ, если считывалась бы с А, кодировала бы Тир–Вал–Ала, если со второго нуклеотида (Т)–Вал–Ала–Мет, и т. д. Подобный код накладывал бы жесткие ограничения на последовательность аминокислот в белках. И все облегченно вздохнули, когда С. Бреннер доказал, что каждый триплет нуклеотидов в ДНК и РНК считывается только один раз (неперекрывающийся код).
И опять как гром с ясного неба. Оказалось, что у некоторых фагов гены перекрываются. У фага φX174 имеется двойное перекрытие, у фага G4 даже тройное, то есть с одной нуклеотидной последовательности считываются три аминокислотных! Это предел экономичности сигнала. Фагам хорошо, а вот каково молекулярным генетикам? Как широко распространен этот феномен в мире вирусов? Встречается ли он у высших организмов? Не знаем.
Но самое интересное из новых открытий я приберег под конец.
Конец коллинеарности гена. До последних лет все согласно считали, что ген коллинеарен тому белку, точнее, той полипептидной цепи, которую он кодирует. Иными словами, каждой тройке нуклеотидов в ДНК, с которой считывается мРНК, соответствует один аминокислотиый остаток в полипептиде.
И опять оказалось не так! В смысловой цепи ДНК, кодирующей белок, обнаружены довольно длинные вставки (интроны), никаких аминокислот не кодирующие. Они считываются при синтезе первичного транскрипта, а далее начинается непонятный процесс. Ненужные вставки вырезаются специальными ферментами и отбрасываются, остатки сшиваются. Этот процесс называется сплэйсингом (калька с английского) Я не знал этого слова, но понял значение сразу, вспомнив свою давнюю морскую практику: сплеснивать трос – значит сращивать его из кусков.
После того как все ненужное из первичного транскрипта удалено, к 5’‑концу присоединяется «шапочка» – три фосфатных остатка подряд и метилированный нуклеотид. А у 3’‑конца вырастает длинный полиадениловый «хвост» – последовательность из многих остатков аденина. Для чего эти добавки – недавно выяснили. Белоксинтезирующие системы клетки – рибосомы – «узнают Сеньку по шапке». 5’‑конец, с которого начинается трансляция, по начальным трем фосфатам. Последовательность поли‑А придает матричной РНК стабильность, она не так быстро разрушается нуклеазами. Это было показано серией изящных опытов. Так как генетический код един для всего органического мира, можно ввести в клетку чужеродную мРНК и синтезировать совсем другой белок. Этим путем удалось синтезировать в незрелых яйцеклетках шпорцевой лягушки гемоглобин кролика, белки вируса табачной мозаики и пчелиного яда. И каждый раз мРНК, лишенная поли‑А последовательности, была нестабильной, распадалась быстро.
А вот для чего гену интроны? На этот счет было высказано немало соображений, вплоть до самых фантастичных: они нужны будто бы для обеспечения процесса эволюции (!). Но ни в одном организме нет ни одной структуры, специально предназначенной для эволюции. Все структуры предназначены только для выживания. Если мы признаем за интронами роль своеобразных органов эволюции, мы наделим природу способностью к прогнозированию и вернемся фактически к учению Аристотеля о будущей причине. Впору подивиться живучести телеологических заблуждений, уже третью тысячу лет воскресающих под разными именами.
А то, что интроны для чего‑то нужны не в будущем, а сейчас, ясно из следующего примера. Всем хорошо известный белок инсулин – один из самых маленьких, в нем всего 50 аминокислот. Значит, его ген состоит из 150 нуклеотидов. У крысы два гена инсулина, обозначаемых, как А и В. Оказалось, что в гене А есть один интрон – нечитаемая вставка в 119 нуклеотидов, а в гене В к нему прибавляется другой – в 444 нуклеотида! Из 713 нуклеотидов в процесс трансляции вовлекается только 150 –комментарии излишни.
Не найдем ли мы какой‑либо аналогии в человеческих языках? Действительно, во многих языках орфография сильно отличается от произношения. Вот примеры, заимствованные мною у Л. В. Успенского: 1) английское «дочь» пишется daughter читается – «дотэ», 2) ирландское «дочь» – пишется kathudhadh читается «кахю», 3) французское «вода» пишется читается «л’о».
«Лишние», непроизносимые буквы в словах – аналоги интронов в генах. Это объясняется обычно тем, что орфография отстает от произношения и люди пишут так, как говорили несколько веков назад. А то и десятилетий: Анатоль Франс вспоминает бабушку, которая упорно выговаривала «кошемар», «булевар». Да, но почему орфография в одних языках отстает от произношения сильно, а в других за ним поспевает? Почему французское правописание консервативней русского (хотя и мы, особенно в быстрой речи, выговариваем, например, «ПалВаныч» вместо «Павел Иванович»)? Консервативность орфографии не случайна. Она достигает предела в тех языках, где много омонимов – слов с разным значением, но произносимых одинаково.
Во французском языке таких слов очень много, он как бы создан для каламбуров. Но то, что оживляет устную речь, может создать помехи при чтении письменного текста. Так что не будь французская орфография консервативной, французам пришлось бы эту консервативность выдумать.
И не случайно иероглифическая письменность упорно держится Китае. Китайский язык весь состоит из омонимов. В устной речи они распознаются по тону, а как с чтением?
А теперь вернемся к нашим интронам. Регуляторные механизма белкового синтеза, к разгадке которых мы только сейчас приступаем должны как‑то «угадывать», «узнавать»[6]нужные гены, чтобы транскрибировать нужную мРНК и затем транслировать нужный белок. Немного пользы организму, если ген гемоглобина будет задействован в нервной клетке, а ген пепсина (пищеварительного фермента) в – мышцах. Генетическая программа не признает омонимов, каламбуры здесь строжайше противопоказаны. Язык генома жестко однозначен, как машинные языки ФОРТРАН или АЛГОЛ, в нем нет места недосказанности размытости значения метафоричности – короче тех особенностей человеческих языков, без которых была бы невозможной изящная словесность. Хромосома ведет себя, как та электронная вычислительная машина которая библейское изречение «Плоть немощна но дух бодр» перевела с английского (The spirit is saund, but the flesh is weak) на русский как «Водка крепкая, но мясо размякло».
Поэтому в гене должна содержаться не только информация об аминокислотных последовательностях. Там должны быть участки, по которым регуляторные элементы клетки его узнают Ясно также, что из окончательной нуклеотидной последовательности мРНК они, как сделавшие свое дело, должны быть удалены. Такими участками и могут оказаться интроны. Это только гипотеза, но на сегодняшний день она наиболее вероятна.
И в заключение рассмотрим важный вопрос: достаточно ли в клетке ДНК для кодирования всех структур сложного фенотипа?
По этому поводу еще недавно велись дискуссии. Казалось, что ДНК явно не хватает. Однако попробуем определить объем генетической информации, как это делал Джон фон Нейман, в битах. Вспомним слова великого физика лорда Кельвина: «Если Вы можете измерить то, о чем говорите, и выразить это в числах, то Вы что‑то знаете об этом предмете; если же Вы не в состоянии ни измерить, ни выразить это в числах, то Ваши знания предмета скудны и неудовлетворительны».
Вот схема простенького расчета, когда‑то мною проделанного. Если бы все основания в ДНК встречались в одинаковом количестве, вероятность встречи каждого из них была бы 0,25.
Отсюда информационная ценность каждого из оснований
H = – (4 • 0,25 log 2 0.25) = 2 бита.
Однако ДНК в геноме неоднородна по составу. Для высших организмов, например позвоночных животных, доля пары гуанин – цитозин составляет всего около 40 процентов. Кроме того, в ней имеются фракции, обогащенные парами АТ и ГЦ. У некоторых крабов в хромосомах выявлены последовательности состоящие только из двух оснований А и Т. Информационная ценность нуклеотидного звена в них снижается вдвое:
H = – (2 • 0,25 log 2 0.25) = 1 бит.
то есть основание может быть только или аденином или же тимином.
Оценить неоднородность ДНК в геноме можно простым опытом. Если мы будем повышать температуру раствора ДНК, то на каком‑то уровне средняя кинетическая энергия молекул окажется выше энергии водородных связей, которыми скреплены половинки двойной спирали. Температура, при которой распадается (денатурирует) половина молекул ДНК, называется температурой плавления. Она сильно зависит от концентрации катионов в растворе (примерно прямо пропорциональна логарифму их концентрации). В паре ГЦ три водородные связи, в паре АТ только две. Поэтому чем больше ГЦ в ДНК, тем более она «тугоплавка». Отсюда следует, что по ширине интервала температур, в котором ДНК плавится, можно судить о ее неоднородности (гетерогенности) в геноме.
Расчет дал около 1,9 бита на основание даже для гетерогенной ДНК млекопитающего (теленка). А число нуклеотидов в геноме млекопитающего около двух‑трех миллиардов (у человека два миллиарда, а у буйвола на 40 процентов больше; видно, дело не в количестве). Значит, запас информации в ДНК млекопитающего 4–6 миллиардов бит, что соответствует библиотеке в полторы‑две тысячи томов.
Не забудьте, что этот запас содержится в яйцеклетке или головке спермия, имеющей микронные размеры. Какова свертка информации! Сказочный джинн, вылетая из бутылки, вырастает всего‑навсего выше финиковой пальмы. Насколько действительность фантастичнее волшебной сказки!
Достаточно ли такого массива информации для постройки фенотипа? Задавшись таким вопросом, ученые спохватились: ведь мы же не умеем оценить сложность фенотипа количественно. В принципе любую структуру, в том числе структуру организма, можно описать с весьма высокой точностью (предел здесь накладывает так называемая квантовомеханическая неопределенность, о которой у нас речь пойдет в следующей главе). Представим, что мы разрежем организм на серию последовательных идущих друг за другом срезов. Расположение структур на каждом из срезов можно описать в двумерной системе координат и выразить объем этой информации в битах. Детальность описания зависит от толщины среза.
Допустим, толщина среза у нас будет один ангстрем (10–10м) – это величина, близкая к пределу разрешающей способности лучших современных электронных микроскопов. Но тогда, скажем, для описания фенотипа человека ростом в 180 сантиметров придется сделать и описать 18 миллиардов таких срезов!
Ясно, что таких опытов никто не проделывал. Все подобные эксперименты оставались мысленными. Структуру поменьше и с меньшим уровнем разрешения, например бактериальную клетку или митохондрию, так описать можно. Увеличивая толщину срезов, скажем, в сто или тысячу раз, мы можем дать описания, но в сто или тысячу раз менее детальные.
А величинам, полученным в результате мысленных экспериментов и приближенных расчетов, как‑то не хочется верить. Все это попросту среднепотолочные цифры. Фенотипическую информацию организма человека оценивали и в 105и в 1025бит. Та же величина для бактерии, по данным разных авторов, колеблется от 104до 1012бит!
Но в теории информации существует правило (закон Шеннона): при передаче по любому каналу информация может только теряться за счет помех, но не увеличиваться. Значит, информация, потребная для описания структуры «человек», не должна превышать четырех миллиардов бит.
Вернее, она должна быть существенно меньше. Если в канале информации есть помехи (а они есть в любом канале), информация генотипа должна быть избыточной, многократно повторяться, иметь механизмы коррекции, устранения помех. Впервые я это очень наглядно понял, слушая переговоры по радиотелефону двух судовых радистов: «Аметист, Аметист, я 4347, я 4347, как меня слышите, прием, прием» – «4347, 4347, я Аметист, слышу вас хорошо, слышу вас хорошо, прием, прием».
Ответ не совсем точен: слышали мы хорошо, но из‑за треска в динамике понимали плохо.
Примерно так обстоит дело и в канале информации «от ДНК к признакам организма»: не будь генетическая информация высокоизбыточной, новое поколение из‑за случайных помех в развитии не походило бы на родителей, получался бы «не мышонок, не лягушка, а неведома зверюшка».

Рис. 19. Пятерня однояйцевых близнецов (сестры Дионн) в день пятилетия. По особенностям симметрии удалось восстановить их историю до рождения. Оплодотворенная яйцеклетка разделилась на два бластомера, которые разошлись и стали делиться самостоятельно. Из одного получились Ивонна и Анна, из другого Цецилия и еще один бластомер, который, разделившись, дал Марию и Эмилию. В результате получилось пять зародышей с абсолютно идентичными генетическими программами. Насколько полно сходство фенотипов при тождестве генетических программ, вы можете убедиться сами, глядя на лица этих девочек.
Но мы‑то знаем, как удивительно точно черты родителей проявляются в потомстве. Еще более разительный пример точности передачи генетической информации – однояйцевые близнецы, братья и сестры, развившиеся из одной разделившейся яйцеклетки. У них идентичные наборы генов, поэтому только у близнецов удаются пересадки тканей и органов, их путают даже хорошие знакомые и не могут различить по запаху собаки.

Рис. 20. В мире нет двух людей с одинаковыми отпечатками пальцев. На этом и основана большая область криминалистики – дактилоскопия. Но нет правил без исключений. Я думаю, даже Шерлок Холмс не смог бы различить отпечатки пальцев однояйцевых близнецов (I и II на рисунке). Как вы видите, даже столь, казалось бы, маловажная структура, как дактилоскопический узор, весьма жестко детерминирована генетически.
Значит, информация, заключенная в генотипе, избыточна. Один из механизмов мы знаем: это двойной набор хромосом в оплодотворенной яйцеклетке. В принципе развитие нормального фенотипа может быть обеспечено половинным, гаплоидным набором хромосом. Случаи партеногенеза, развития неоплодотворенной яйцеклетки, известны у многих животных и растений.
Отсюда следует, что объем информации, закодированный в генотипе, надо уменьшить вдвое. Эти соображения и заставили многих исследователей искать другие источники генетической информации, помимо ДНК.
Эмбриолог Х. Равен, о котором мы уже упоминали, выдвинул предположение, что, помимо ядерной ДНК, хранилищем информации может быть приповерхностный, так называемый кортикальный, слой яйцеклетки. Эта гипотеза не подтвердилась. Не следует забывать, что хранители наследственной информации – гены – должны размножаться, реплицироваться. В противном случае количество их в клетке будет уменьшаться вдвое с каждым делением. Из всех известных нам соединений только нуклеиновые кислоты обладают способностью к репликации. Те клеточные структуры, которые могут размножаться, например энергетические станции клетки, митохондрии и хлорофилловые зерна растений, хлоропласты, имеют свои, автономные геномы, очень похожие на простые бактериальные. Ядру они помочь не могут, хоть бы самим воспроизвестись с минимальной помощью от ядра.
Попробуем подойти к этому вопросу иначе: а правильно ли мы оценили сложность фенотипа?
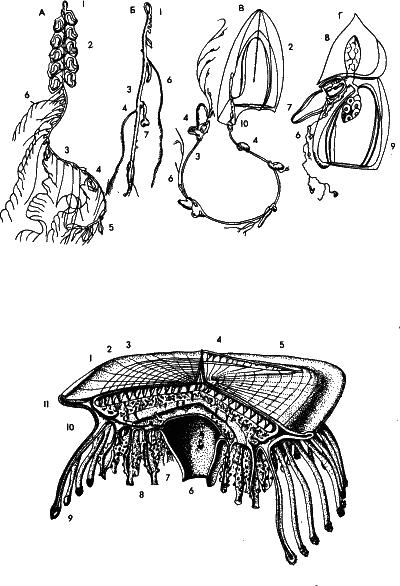
Рис. 27. Согласно наиболее распространенной гипотезе, многоклеточные животные произошли от колоний одноклеточных. Сверхорганизмы высшего порядка возникают из колоний многоклеточных, в которых каждый организм выполняет определенную функцию. Таковы колониальные кишечнополостные – сифонофоры. На рисунке наверху: сифонофоры из группы сифонант. Верхние особи них превратились в подобие плавательных пузырей, удерживающих колонию в плавучем состоянии. Другие особи выполняют функции движения, питания и защиты колонии, а часть приспособлена для размножения. Сифонофоры‑дисконанты настолько далеко зашли по этому пути, что многие ученые отказываются считать их колонией и относят к единичным гидроидным полипам. Внизу: представитель этой группы – парусник велелла (сектор тела вырезан, чтобы показать сложное строение). Здесь также действует общий принцип – совокупность одинаковых элементов, представляющая информационную систему с высокой избыточностью, превращается в более сложную за счет снижения избыточности.
Тот же Равен указывает, что, например, у лошади несколько миллионов печеночных клеток и все они построены одинаково. Можно конечно, определить объем информации, потребный для описания каждой из клеток, а потом умножить число бит на число клеток. Но не равносильно ли это утверждению, что для полного тиража скажем, журнала «Наука и жизнь» требуется авторов, редакторов, корректоров, художников, фотографов и т. д. в три миллиона раз больше, чем для сигнального экземпляра?
Значит, структура фенотипа также информационно избыточна, причем в весьма высокой степени. Генотип может дать подробное описание лишь одной клетки, а затем указать, что она должна повториться сотни тысяч и миллионы раз.
Вот еще хороший пример фенотипической избыточности, который нам еще пригодится в будущем.
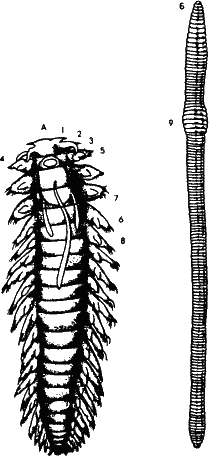
Рис. 21. Для нас чрезвычайно важен вопрос, каким путем в процессе прогрессивной эволюции происходит усложнение структуры, увеличение количества информации, потребной для описания организма. Следует помнить, что новая информация не возникает из ничего. Она возникает из избыточной информации при взаимодействии с шумом. На рисунке два кольчатых черня: многощетинковый червь полихета и малощетинковый – обычный дождевой червь. Как видим, тела их состоят из практически идентичных повторяющихся члеников, то есть информация фенотипа в высокой степени избыточна. Мутация (шум в канале передачи) изменяют форму отдельных члеников, строение конечностей на них и внутренних органов. Если эти изменения окажутся приспособительными, отбор сохранит их. Избыточность при этом снизится, но усложнится структура, и количество информации возрастет. Так идет прогрессивная эволюция.
Есть довольно просто устроенные морские кольчатые многощетинковые черви – полихеты. Туловище наиболее примитивных из них разделяется на десятки, а то и сотни члеников. И все эти членики устроены по одному образцу, кроме первого, на котором сконцентрированы органы чувств, второго – с ротовым отверстием и последнего – с анальным отверстием. Значит, для описания фенотипа достаточно только четырех члеников, но при этом необходимо добавить: третий по счету повторяется столько‑то раз.

Рис. 22. Вот еще примеры высокоизбыточной фенетической информации. Вымершие членистоногие – трилобиты – имели конечности, практически одинаковые и по форме, и своим функциям: движения, захвата пищи и дыхания. Все это они делали одинаково хорошо (вернее, одинаково плохо). У многоножек (справа) ротовые части – производные конечностей – уже специализированы, однако ноги одинаковы и тело еще не делится, как у насекомых, на грудной и брюшной отделы.
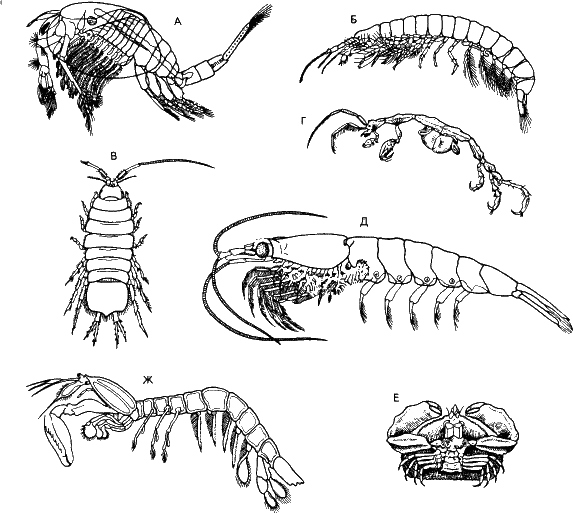
Рис. 23. Различные представители отряда высших ракообразных. Здесь уже тело поделено на головной, грудной и брюшной отделы, которые несут конечности разного строения. Да и членики устроены по‑разному. Структура фенотипа в процессе прогрессивной эволюции усложнилась, и требуется больше информации для ее описания.
Ракообразные произошли от предков, похожих на кольчатых червей. У высших ракообразных, например у речного рака, все членики устроены по‑разному, особенно различаются конечности, и каждый членик поэтому придется описывать отдельно. Объем информации повышается: ведь это более сложный фенотип. И эта новая информация возникает не из ничего – из избыточной информации фенотипа (ценой снижения избыточности).
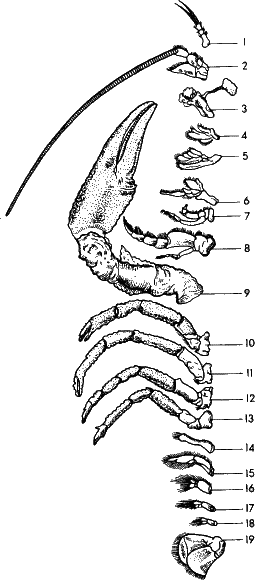
Рис. 24. На предыдущих рисунках вы видели примеры избыточности информации а строении тела членистых животных – кольчатых червей, трилобитов, многоножек. У высших членистых монотонность сменяется разнообразием, новая информация возникает за счет избыточной. У речного рака практически каждую конечность надо описывать отдельно, ибо они выполняют разные функции и имеют разную форму: первая и вторая пара – органы чувств, с третьей по пятую – челюсти, с шестой по восьмую – ногочелюсти (передают пищу челюстям), с девятой по тринадцатую – ходильные, с четырнадцатой по восемнадцатую – брюшные. Последняя пара образует «хвостовой» веер: хлопая им, рак плывет задом наперед (ползает он, как и все прочие животные, головой вперед, а не пятится).
Определяя объем информации потребной для описания фенетической структуры, не следует забывать о связях между признакам и организма. Допустим, нам известно о некоем животном только то, что у него одна левая дуга аорты. Кажется, это очень мало. Ошибаетесь: отсюда однозначно следует, что сердце у него четырехкамерное, эритроциты без ядер, хорошо развитый мозг, постоянная температура тела. Это значит, что оно относится к классу млекопитающих. Такие сцепления признаков называются корреляциями. Впервые их широко применил основатель палеонтологии Жорж Кювье. Известно, что он по отдельной кости уверенно описывал облик животного. Существует анекдот про Кювье: один из его учеников решил над ним подшутить, надел на себя шкуру с рогами и копытами, подошел к учителю ночью и прорычал страшным голосом: «Я съем тебя». Кювье спросонья твердо сказал: «Рога и копыта – значит, ты травоядное и не можешь съесть меня». Случай, конечно, вымышленный, но логику Кювье демонстрирует хорошо.
Впрочем, бывали случаи, когда логика Кювье подводила. Большой изогнутый коготь, найденный отдельно от прочих костей, он приписал муравьеду. На деле коготь принадлежал халикотерию: жили на земле и дожили почти до появления на ней человека странные звери, по всем признакам копытные, но имевшие вместо копыт мощные ногти. Так что корреляция отнюдь не всегда бывает полной.
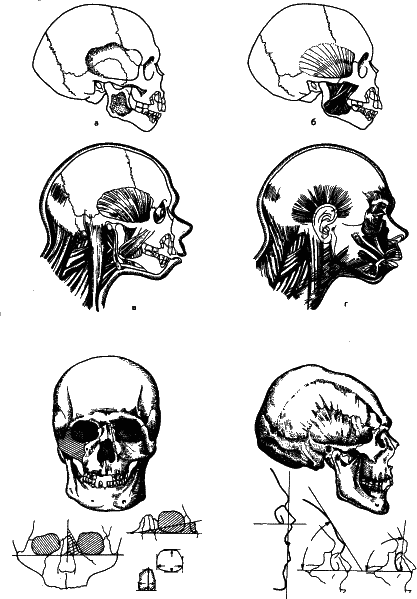

Рис. 28. В организме одна структура может с большей или меньшей жесткостью определять детали строения другой. Именно это позволило нашему замечательному анатому, антропологу, археологу и скульптору М. М. Герасаимову разработать метод восстановления лица по черепу. Здесь приведены две схемы: реконструкция лица неандертальского мальчика из грота Тешик‑Таш и головы скифского воина из богатого погребения. Любопытно, что, когда был изготовлен его скульптурный портрет, историки опознали его по барельефам и монетам. Это оказался скифский царь Скилур.
Наш замечательный антрополог, анатом и скульптор М. М. Герасимов, Руководствуясь теми же принципами что и Кювье разработал методику восстановления лица по черепу, причем с точностью, удовлетворяющей не только археологов, но и работников уголовного розыска. А это возможно осуществить только в одном случае: когда структура одной части организма определяет структуру другой.
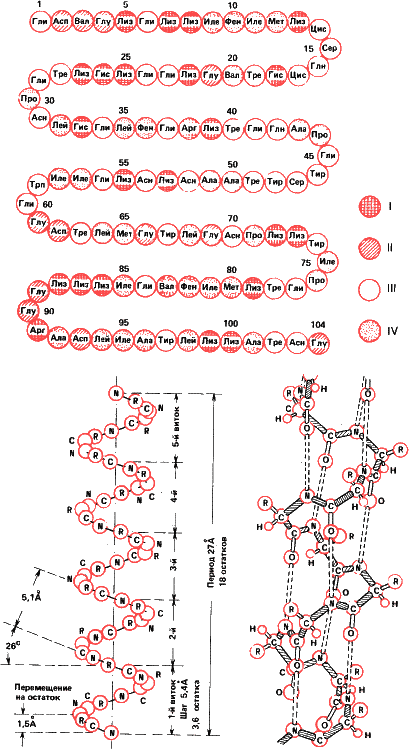
Рис.29. На молекулярном уровне структура высшего уровня также определяется структурой низшего. На рисунке сверху первичная структура белка – цитохрома С, переносчика электронов в дыхательных цепях (обозначения те же, что и на рис. 16). Внизу: схема вторичной структуры – спирали Полинга – Кори. Ее поддерживают водородные связи между группами –CO – и –NH –. Что образуется из полипептида со вторичной структурой, показано на следующем рисунке.
Этот принцип соблюдается в природе начиная с молекулярного уровня. Первичная структура белковой молекулы – это последовательность аминокислотных остатков в полипептиде. Соседние звенья в пептидной цепочке соединяются водородными связями, образуя спиралеобразную фигуру (так называемая спираль Полинга‑Кори). Это вторичная структура. Но спираль Полинга также образует трехмерную третичную структуру, специфичную для каждого белка. Наконец, отдельные белковые глобулы могут объединяться попарно и по четыре, а то и больше, образуя четвертичную структуру. Таков, например, гемоглобин.
И все эти структуры определяются одной – первичной. Значит, в генотипе нужно кодировать только последовательность аминокислот, все остальное возникает при соответствующих условиях само.
Мы уже рассматривали пример с вирусом табачной мозаики, который при подкислении среды распадается на отдельные молекулы белка и РНК. При подщелачивании происходит обратный процесс, именуемый самосборкой. Все вирусы в клетках хозяина возникают в результате самосборки молекул нуклеиновых кислот и белков, и их структуры однозначно определяются последовательностью аминокислот в белках (и, значит, нуклеотидов в ДНК).
И не только вирусы. В результате самосборки возникают все клеточные структуры – рибосомы и клеточные мембраны. А сами клетки? Возьмем для примера простейшее животное; всем известного пресноводного полипа – гидру. Фенотип ее состоит из немногих типов клеток (около десяти). Давно уже ставят эффектные опыты, когда гидр растирают на отдельные клетки и из них в результате процесса, похожего на самосборку, возникает целая гидра. Значит, структура фенотипа гидры однозначно определяется свойствами клеток, его слагающих.
С высшими организмами такой опыт не поставишь: слишком много типов клеток и слишком сложные структуры они образуют.
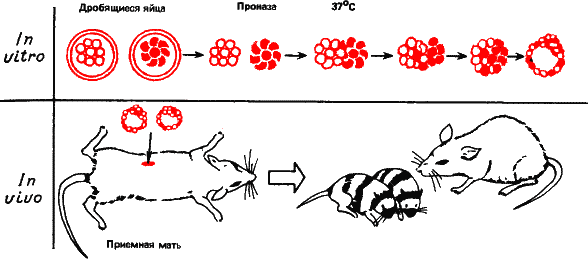
Рис. 31. Схема получения аллофенных мышей. Из яйцеводов беременных мышей извлекают яйцеклетки начавшие дробиться. Лучше всего опыт удается после трех делений (стадия восьми бластомеров). Для наглядности яйцеклетки берутся у мышей разной масти. Если обработать делящееся яйцо проназой – ферментом, расщепляющим белки, оно распадается на отдельные бластомеры. Отмытые от фермента бластомеры снова слипаются, даже если они от разных пород мышей. «Реассоциированный» зародыш можно пересадить в яйцеводы другой самки мыши. Финал – приемная мать изумленно смотрит на ни на что не похожее потомство (как та Сова из «Винни‑Пуха» которая по ошибке снесла гусиное яйцо).
Если растереть высшее животное, скажем кролика, в кашицу, из клеток он заново не восстановится, Но на ранних стадиях развития подобные эксперименты удавались. Вы знаете из школьного курса, что оплодотворенная яйцеклетка млекопитающего уже в яйцеводах начинает дробиться, образуя зародыш. После трех дроблений зародыш соответственно состоит из восьми клеток (бластомеров).
Зародышей мыши на этой стадии извлекали из яйцеводов и обрабатывали раствором проназы. Это фермент, расщепляющий белки. Дробящаяся яйцеклетка распадалась на отдельные бластомеры. Можно смешать бластомеры разных пород мышей, например различающихся по окраске, отмыть от проназы и увидеть, как они будут слипаться друг с другом, вновь образуя зародыш. Такой зародыш можно пересадить другой мыши и дорастить до рождения и взрослого состояния. Мышей, явившихся на свет в подобных опытах, называют аллофенными.
Они – потомки трех, четырех и более родителей (в зависимости от того, сколько зародышей мы смешали). На рис. 31 показано изумление приемной матери при виде своего мозаичного, полосатого потомства.
Постепенно в умах исследователей сформулировалась идея, что в геноме яйцеклетки закодирована лишь информация о первичной структуре белков и очередности и интенсивности их синтеза. Закодирован, короче говоря, не сам фенотип, а серия инструкций по его созданию – самосборке на уровне частей клетки, самосборке на уровне клеток, тканей и органов.
И тут оказалось, что ДНК в ядре… чересчур много. Всего мы ожидали, но только не этого! Проверим полученный ошеломляющий вывод простым расчетом. Молекулы разных белков различаются по величине и молекулярной массе, среди них есть и крошки, состоящие из немногих десятков аминокислот, и настоящие гиганты. Например, молекулярная масса молекулы синего дыхательного пигмента виноградной улитки гемоцианина около девяти миллионов дальтон. Но в расчетах удобнее оперировать средними величинами. «Средний» белок, характерный для всей живой природы, содержит примерно 300–350 аминокислотных остатков. Значит, размер «среднего» гена, кодирующего белок, без учета размера интронов, вставленных в него, около тысячи нуклеотидов.
Отсюда следует, что геном млекопитающих может содержать информацию о структуре миллиона и более белков, а геном плодовой мушки‑дрозофилы – не менее ста тысяч белков. У некоторых земноводных с особо большим геномом – десятки миллионов! Эти фантастические величины совершенно не согласуются с данными, полученными другими методами. У той же дрозофилы гигантские хромосомы слюнных желез поперечно исчерчены, как бы поделены на доли – хромомеры. Генетические эксперименты как будто бы показывают, что в каждом хромомере содержится только один ген, кодирующий белок. А число хромомеров подсчитано – их около пяти тысяч. По‑видимому, фенотип дрозофилы определяется синтезом лишь пяти тысяч белков. И это хорошо согласуется с данными, полученными методами биохимии. А ДНК в геноме в 20 раз больше.
Сколько белков могут синтезировать клетки млекопитающих, пока еще точно неизвестно. Но предварительные расчеты показывают: примерно 50 тысяч и уж никак не больше 100 тысяч. А ДНК хватает на 3–6 миллионов, опять получается почти стократный избыток. И если раньше исследователи ломали голову над тем, где еще может храниться генетическая информация, п
Date: 2015-07-02; view: 641; Нарушение авторских прав