Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Статистична обробка експериментальних даних
|
|
С ередня арифметична величина
Середня арифметична широко застосовується у науці й техніці. Як правило, немає буквально жодної біологічної роботи, де б не зустрічалася в тій чи іншій формі середня арифметична, що є узагальнюючою величиною абстрактного і конкретного характеру. Абстрактність середньої арифметичної полягає в тому, що вона за своїм числовим значенням може не дорівнювати жодному елементу вибірки. Конкретність виявляється в тому, що вона виражається в тих же одиницях виміру, що й варіанти вибірки. Значення її знаходиться в середньому положенні між найменшим і найбільшим значеннями вибірки.
Розглянемо вибірку з n вимірів, кожен з яких позначимо символом x. (іноді зручніше розрізняти окремі виміри, тому до x дописують індекс: x1, x2, x3,..., xn). Тоді середнє арифметичне значення для n вимірів, що позначається символом М, запишеться у вигляді:
М = 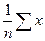 .
.
Символ математичного підсумовування означає, що потрібно додати результати усіх вимірювань.
У випадку вибірки з n вимірів додаються усі отримані значення і результат ділиться на кількість вимірів n. Строго математично формула виглядає наступним чином:
М = 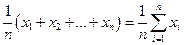 .
.
Приклад 1.
Було зроблено 5 вимірів умісту кальцію у крові (в умовних одиницях): 11,27; 11,36; 11,09; 11,16; 11,47. Обчислити середнє арифметичне:
М = 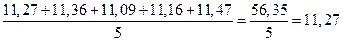
Отже, середнє арифметичне значення вмісту кальцію у крові дорівнює 11,27.
Середнє квадратичне відхилення
Знаючи середнє арифметичне значення даних експерименту, виникає наступне питання: як обчислити середню величину, на яку відрізняються дані від середнього арифметичного?
Різницю між будь-яким виміром з вибірки і середнім арифметичним цієї ж вибірки називають відхиленням варіанти xi від М: xi – М.
Якщо обчислити відхилення для усіх варіант, то серед отриманих значень будуть від’ємні і додатні, що в сумі даватимуть 0, тобто, взаємно компенсуються. Це означає, що неможливо обчислити середнє відхилення, як середнє арифметичне відхилень. Для того щоб уникнути компенсації додатних і від’ємних значень, існує декілька способів. Найпоширеніший – піднесення кожної різниці (xi – М) до квадрату (квадрати як від’ємних, так і додатних величин є величинами додатними). Додаючи квадрати усіх різниць, і ділячи на кількість цих різниць, отримаємо величину, що називається дисперсією. Фактично вона показує середнє арифметичне квадратів відхилень. Для того, щоб позбутися квадрату величини, обчислюємо корінь квадратний з дисперсії. Отримане значення називається середнім квадратичним відхиленням. Розрізняють формули середнього квадратичного відхилення для генеральної і вибіркової сукупностей.
За існуючих даних генеральної сукупності використовують наступну формулу: 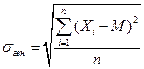 ,
,
де  Xi – значення і -тої варіанти, і=1,...,n;
Xi – значення і -тої варіанти, і=1,...,n;
М – середнє арифметичне,
n – об’єм генеральної сукупності.
Якщо ж є тільки дані вибірки, то застосовується наступна формула:
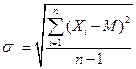 ,
,
де Xi – значення і -тої варіанти, і=1,...,n;
М – середнє арифметичне;
n – об’єм вибіркової сукупності.
Приклад 2.
За даними прикладу 1 обчислимо середнє квадратичне відхилення вмісту кальцію у крові (5 даних вимірів розглядаємо, як вибіркову сукупність):
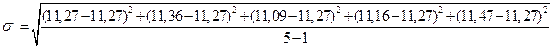
 0,152
0,152
Помилка вибіркової середньої арифметичної
Вивчаючи певну ознаку, неможливо дослідити всі об’єкти генеральної сукупності тому, що вона, як правило, дуже чисельна, можливо навіть складається із нескінченно великого числа членів. Тому робиться вибірка об’єктів, що досліджуються. При цьому постає таке питання: чи можливо за результатами, отриманими під час вивчення вибірки, робити висновки про всю генеральну сукупність?
Характеризуючи цілу сукупність лише за її частиною, неможливо уникнути помилок, що називаються помилками репрезентативності.
Навіть у разі ідеальної організації дослідницької роботи з’являються помилки такого типу.
Помилка репрезентативності середньої арифметичної залежить від двох величин: різноманітності ознаки у генеральній сукупності і чисельності вибірки. Чим меншим є ступінь різноманітності (на його величину вказує середнє квадратичне відхилення) і чим більша кількість вибраних для дослідження об’єктів, тим менша величина помилки репрезентативності вибіркового середнього арифметичного. Для розрахунку величини помилки використовується формула:
m = 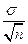 ,
,
де ,
Xi – значення і- тої варіанти, і=1,...,n;
М – середнє арифметичне вибірки;
n – об’єм вибіркової сукупності.
Приклад 3.
За даними прикладів 1 і 2 обчислимо помилку середньої арифметичної:
m = 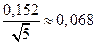
Критерій вірогідності різниці двох середніх значень (критерій Стьюдента)
Одним з важливих завдань біологічного дослідження є отримання даних щодо результатів дії зовнішніх факторів на живий об’єкт. Для проведення дослідів вибираються дві групи об’єктів (не обов’язково однієї чисельності), одна з яких є дослідною, а інша – контрольною.
Наприклад, необхідно виявити ефективність застосування деякого препарату, що має за мету підвищення опірності організму відносно конкретної інфекції.
Дослід може бути поставлений так: беруть дві групи тварин. Тваринам однієї групи препарат уводять, а іншим – ні. Перша група буде дослідною, а друга – контрольною. Потім тварин обох груп заражають збудником інфекції і спостерігають, скільки днів житимуть тварини піддослідної групи і контрольної.
У таблиці зведені результати досліду:
| Число днів | n | M | 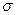
| m | |||||||
| Дослід | 6,25 | 1,25 | 0,22 | ||||||||
| Контроль | – | – | 5,22 | 0,97 | 0,2 |
З таблиці видно, що середні значення для дослідної і контрольної груп не збігаються, що недостатньо для доведення ефективності препарату.
Насправді, кожна група тварин є випадковою вибіркою з генеральної сукупності. Як відомо, для різних вибірок, отриманих з однієї й тієї ж генеральної сукупності, середні арифметичні будуть різними.
Наприклад, є генеральна сукупність, що складається з 5 варіант (N = 5):
xi: 8, 16, 20, 24, 32
(числа можуть позначати висоту рослин у сантиметрах).
Замінимо вивчення всієї генеральної сукупності вивченням вибірок з неї об’ємом n = 4. Ось ці вибірки:
1) 8, 16, 20, 24;
2) 8, 16, 20, 32;
3) 8, 16, 24, 32;
4) 8, 20, 24, 32;
5) 16, 20, 24, 32.
Обчислюючи для кожної вибірки середнє арифметичне, отримуємо такі значення: М1 = 17, М2 = 19, М3 = 20, М4 = 21, М5 = 23.
Тому виникає питання: чи вважати розбіжність між середніми значеннями в дослідній і контрольній групах просто розбіжністю між двома вибірковими середніми, чи ця розбіжність зумовлена ефективною дією препарату? Інакше кажучи, чи можливо узагальнити висновок про ефективність препарату і розглядати вибірки дослідної і контрольної груп, як вибірки з різних генеральних сукупностей? Таке питання належить до проблем вірогідності різниці середніх арифметичних.
Розглянемо загальний метод розв’язання цієї проблеми.
Починають з припущення, що обидві вибірки зроблені з однієї генеральної сукупності. Тоді різниця між вибірковими середніми пояснюється існуванням такої різниці взагалі. Таке припущення називають нульовою гіпотезою і позначають Н0.
Далі обчислюють ймовірність того, що за умови правильності нульової гіпотези розбіжність між вибірковими середніми (М1 – М2) може досягти тієї величини, що є. Якщо ця ймовірність виявиться малою, нульова гіпотеза відкидається. Граничне допустиме значення ймовірності називають рівнем значущості і позначають a. Яке ж значення ймовірності вважати малим? Як правило, вибирають одне з таких значень: a = 0,05 = 5 %, a = 0,01 = 1 %, a = 0,001 = 0,1 %. Різниця між вибірковими середніми вважається значущою (тобто реальною), якщо ймовірність правильності нульової гіпотези менша за рівень значущості. У такому разі нульова гіпотеза відкидається.
Вибір того чи іншого конкретного значення a визначається конкретним завданням дослідника. Наприклад, якщо досліджується новий лікарський засіб і потрібно довести його нешкідливість для життя, – навіть рівень значущості 0,001 буде зависоким. Навпаки, якщо мова йде про підвищення продуктивності стада за рахунок недорогої зміни раціону, достатньо і невеликої впевненості у позитивному результаті.
Критерій, що дозволяє визначити вірогідність різниці вибіркових середніх, сформульований англійським математиком Вільямом Госсетом (1876–1937), який працював під псевдонімом Стьюдента. Критерій носить назву критерію Стьюдента.
Згідно з ним обчислюється величина t = 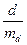 , що потім порівнюється з табличною величиною tst.
, що потім порівнюється з табличною величиною tst.
Чисельник d – різниця між середніми арифметичними двох вибіркових груп (знак різниці значення не має:
d = | М1 – М2 |), md = 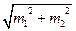 – помилка вибіркової різниці;
– помилка вибіркової різниці;
m1, m2 – помилки репрезентативності порівнюваних вибіркових середніх (m1 = 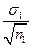 , m2 =
, m2 = 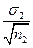 ;
;
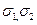 – середні квадратичні відхилення відповідних вибірок;
– середні квадратичні відхилення відповідних вибірок;
n1, n2 – об’єми вибірок).
За таблицею 1 визначається значення tst, що залежить від двох параметрів: величини n = n1 + n2 – 2 (n називається числом ступенів волі) і ймовірності Р = 1 – a (ймовірність упевненості у неправильності нульової гіпотези).
Якщо t £ tst , – нульова гіпотеза приймається (згідно з прикладом це означає, що препарат неефективний). Якщо ж t > tst – Н0 відкидається.
Приклад 4.
За даними прикладу 3 оцінимо ефективність препарату, використовуючи критерій Стьюдента. Гіпотеза Н0: препарат неефективний.
Середнє арифметичне значення кількості днів, які пережили тварини дослідної групи М1 = 6,25, а контрольної – М2 = 5,22. Кількість тварин дослідної групи (об’єм вибірки) n1 = 32, а контрольної n2 = 23. Середні квадратичні відхилення – s1 =1,25, s2 = 0,97. Помилки репрезентативності:
m1 =0,22, m2 = 0,2. Отже, згідно з критерієм Стьюдента обчислюємо величину t = , де d = | М1 –М2 | = | 6,25 – 5,22 | = 1,03; md = = = 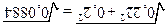 » 0,297.
» 0,297.
t = 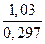 »3,47.
»3,47.
За таблицею 1 визначимо значення величини tst. Число степенів волі
n = n1 + n2 – 2 = 32 + 23 – 2 = 53» 50.
За різних рівнів значущості маємо: t 0,05 = 2,01; t 0,01 = 2,68; t 0,001 = 3,5.
Оскільки t > t 0,01, – нульова гіпотеза відкидається з ймовірністю 0,99.
Висновок: препарат можна вважати ефективним у 99%.
Метод j (фі)
Метод визначення вірогідності різниці часток (процента) появи ознаки у вибіркових сукупностях запропонований англійським статистиком Р.Е. Фішером (1890–1962). Метод може бути застосований за будь-яких значень часток, але найчастіше ним користуються, якщо р < 0,2 або р > 0,8.
Автор довів, що визначити вірогідність різниці часток точніше і простіше, якщо замість кожної частки взяти кут, синус якого дорівнює кореню квадратному з цієї частки. Тоді частки перетворюються в кути j за формулою:
j = 0,0349 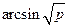 ,
,
де, p – частка,
j – кут у радіанах.
Таке перетворення значно уточнює визначення вірогідності різниці малих (менших 0,2) та великих (більше 0,8) часток.
Вірогідність різниці часток визначається за допомогою метода j формулою:
F = (j1 – j2) 2  ,
,
де, n1, n2 – об’єми вибірок;
Fst – величина, що знаходиться за таблицею 2. Fst залежить від n1 = 1 і n2 = n1 + n2 – 2.
Приклад 5.
Порівнюється частка 0,00055 отримана по групі з n1 = 5440, з часткою 0,0054 – по групі з n2 = 551. Вірогідність різниці цих часток за допомогою методу j можна визначити так:
j1 = 0,0349 × 1,354 = 0,047;
j2 = 0,0349 × 4,21 = 0,147;
F = 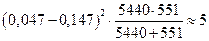 ;
;
n1 = 1; n2 = 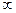 , отже за таблицею 2 для різних рівнів значущості F 0,05 = 3,8, F 0,01 = 6,6, F 0,001 = 10,8.
, отже за таблицею 2 для різних рівнів значущості F 0,05 = 3,8, F 0,01 = 6,6, F 0,001 = 10,8.
Нульова гіпотеза відкидається (з ризиком помилитися 0,05: у 5 %, бо F > F0.05)
Кореляція. Коефіцієнт кореляції
Кореляція (від пізньолатинського correlatio) – статистична залежність між величинами, яка не має строго функціонального характеру. Кореляційна залежність виникає тоді, коли одна з величин залежить не тільки від заданої другої, а й від деяких випадкових факторів; або коли серед умов, від яких залежать обидві величини, є загальні для них обох.
Кореляційний зв’язок – це неточна залежність однієї величини від іншої. Числовим значенням однієї змінної ставиться у відповідність декілька значень іншої. Наприклад, між кількістю внесених на поле добрив і врожайністю пшениці існує незаперечна залежність. Це не означає, що конкретній кількості добрив відповідає визначена величина урожаю. На урожай впливає багато інших факторів: склад і структура ґрунту, різні методи посіву і таке інше.
Кореляційний зв’язок виявляється у середньому для усієї сукупності спостережень. Відносно окремих спостережень, цей зв’язок дуже неповний і неточний. Відомо, наприклад, що існує кореляція між масою тварини та її висотою. Це означає, що більш високі тварини зазвичай важчі ніж нижчі. Та в деяких випадках нижча тварина може виявитися важчою за високу.
Кореляційний зв’язок може мати різний ступінь – від повної незалежності до повної кореляції. Крім того, характер зв’язку між різними величинами може бути різним. Тому виникає необхідність визначити форму, напрям і ступінь кореляційних зв’язків.
За формою кореляція може бути прямолінійною і криволінійною, за напрямком – прямою і оберненою.
За додатної кореляції залежність між величинами буде прямою: у разі збільшення однієї величини збільшується й інша. За від’ємної кореляції залежність обернена: збільшення однієї величини пов’язано зі зменшенням іншої. Ступінь кореляції вимірюється різними показниками зв’язку. Такими показниками є коефіцієнт кореляції, кореляційне відношення тощо.
Коефіцієнт кореляції вимірює степінь і визначає напрям кореляційного зв’язку. Найпоширеніша формула для його обчислення:
rxy = 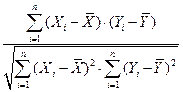 ,
,
де Xi, Yi – числові значення величин, між якими встановлюється кореляційний зв’язок; 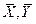 – середні арифметичні значення величин.
– середні арифметичні значення величин.
Помилка коефіцієнта кореляції
Коефіцієнт кореляції обчислюється за даними вибірки з генеральної сукупності, тобто завжди є вибірковою величиною. Тому він має свою помилку репрезентативності. Ця помилка є мірою розбіжності між коефіцієнтами кореляції, обчисленими за даними генеральної і вибіркової сукупностей. Обчислюється вона за формулою:
mr = 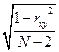 ,
,
де rxy – коефіцієнт кореляції, N – число порівнюваних пар величин.
Вірогідність вибіркового коефіцієнта кореляції
Критерій вірогідності вибіркового коефіцієнта кореляції визначається за формулою:
tr = 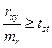 , n = N - 2,
, n = N - 2,
де rxy – вибірковий коефіцієнт кореляції,
mr – помилка репрезентативності,
N – число корельованих пар величин.
Якщо t ≥ tst – то коефіцієнт кореляції вірогідний. У такому випадку можна вважати з певною ймовірністю, що між корельованими величинами є зв’язок і в генеральній сукупності.
Якщо t < tst – то вибірковий коефіцієнт кореляції невірогідний, що не дає можливості зробити висновок про зв’язок величин у генеральній сукупності. Для вирішення питання про існування зв’язку, потрібно провести додаткові дослідження на більш чисельному матеріалі.
Додаток Б
ВІДЗИВ
на випускну магістерську роботу студента _____ курсу _______ групи
Факультет ветеринарної медицини
_____________________________________________________________
(прізвище, ім’я, по батькові)
Тема: _______________________________________________________
_________________________________________________________________
_________________________________________________________________
_________________________________________________________________
Випускна робота __________________ вимогам ОКР “Магістр”
(відповідає, не відповідає)
із спеціальності 110101 “Ветеринарна медицина”
Робота написана на ______________________________ тему.
Автором _______________________________ зібраний матеріал.
Сформовані основні концептуальні завдання, визначена мета роботи, сформована структура.
Автором _________________________ зроблено розрахункову частину
(особисто, за допомогою керівника)
роботи, обґрунтовано отримані результати і зроблені відповідні висновки.
Робота написана __________________________________________
(кваліфіковано, достатньо кваліфіковано, некваліфіковано, інше)
В роботі ____________________ біометричні розрахунки
(застосовані, не застосовані)
Автор використав ________________ джерел літератури.
Висновки і пропозиції викладені ________________________________
(логічно, послідовно, коротко, конкретно, або інше)
До виконання роботи автор ставився _____________________________
(сумлінно, добре, задовільно, незадовільно, або інше)
Робота _______________________________ до захисту на ДЕК.
(допускається, не допускається)
Керівник _________________ _______________ ____________________
Вчене звання (підпис) (прізвище та ініціали)
Дата “_____” _________________ 200_ р.
Додаток В
РЕЦЕНЗІЯ
Випускної магістерської роботи ___________________________________
____________________________________________________________________
____________________________________________________________________
Студента-випускника _______________________________________________
(прізвище, ім’я, по батькові)
Випускна робота виконана на кафедрі __________________________________
___________________________________________________________________
під керівництвом ____________________________________________________
Обсяг роботи _______ с. Робота містить ________ таблиць, ________ рисунків,
_______ фотоілюстрацій. Список літератури включає _______ першоджерел
Тема роботи є _______________________________________________________
(актуальною, неактуальною, чітко визначеною, нечітко визначеною)
___________________________________________________________________
Зміст роботи тему розкриває __________________________________________
(повністю, неповністю, не відповідає темі)
Текст роботи написаний ______________________________________________
(грамотно, є окремі помилки, стилістичні, граматичні)
Робота оформлена ___________________________________________________
(акуратно, не досить акуратно, не акуратно)
Висновки і пропозиції ________________________________________________
(випливають зі змісту, не випливають, логічні, не логічні, конкретні, не конкретні)
___________________________________________________________________
Найбільш цінним у роботі є ___________________________________________
(вказати ключові аспекти роботи)
___________________________________________________________________
___________________________________________________________________
Суттєві недоліки ____________________________________________________
(перерахувати)
___________________________________________________________________
Заключення ________________________________________________________
(відповідає, не відповідає вимогам, заслуговує оцінки відмінно, добре, задовільно)
___________________________________________________________________
___________________________________________________________________
Рецензент ___________ _______________________ _________________
(підпис) (прізвище, ім’я, по батькові) (вчене звання)
Дата _____________________________________
Додаток Г
ОДЕСЬКИЙ ДЕРЖАВНИЙ АГРАРНИЙ УНІВЕРСИТЕТ
______________________________________________________________________
(повне найменування вищого навчального закладу)
Date: 2015-06-11; view: 912; Нарушение авторских прав