Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Критерии согласия для сложной гипотезы
На практике задача о согласии данных наблюдений с некоторым совершенно конкретным распределением, встречается реже, чем задача проверки сложной гипотезы, которую мы рассматриваем ниже.
Более трудной, но более важной для приложений задачей является проверка гипотезы о том, что данная выборка подчиняется определенному параметрическому закону распределения, например нормальному закону. Параметры этого закона остаются неопределенными, так что эта гипотеза сложная.
Пусть x1, …, xn – выборка из распределения с функцией распределения
F(x, 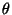 ). Здесь - неизвестный параметр, не обязательно скалярный.[11] Обозначим его истинное значение через º. Сейчас мы не можем сравнить выборочную функцию распределения Fn(x) и теоретическую, поскольку эта последняя нам не вполне известна: в ее выражение F(x, º) входит неопределенный параметр º. Мы, однако, можем найти для º приближенное значение, основываясь на выборке x1, …, xn. Для этого можно использовать разные методы оценивания, но наиболее ясные и в определенном смысле наилучшие результаты получаются, если использовать метод наибольшего правдоподобия.
). Здесь - неизвестный параметр, не обязательно скалярный.[11] Обозначим его истинное значение через º. Сейчас мы не можем сравнить выборочную функцию распределения Fn(x) и теоретическую, поскольку эта последняя нам не вполне известна: в ее выражение F(x, º) входит неопределенный параметр º. Мы, однако, можем найти для º приближенное значение, основываясь на выборке x1, …, xn. Для этого можно использовать разные методы оценивания, но наиболее ясные и в определенном смысле наилучшие результаты получаются, если использовать метод наибольшего правдоподобия.
Итак, пусть n – оценка наибольшего правдоподобия по выборке x1, …, xn для неизвестного параметра распределения F(x, ). Теперь для вычисления статистики Колмогорова вместо F(x, º) мы можем использовать F(x, n) и ввести модифицированную статистику Колмогорова:
 (3.1)
(3.1)
Аналогично, модифицированная статистика омега-квадрат есть:
 (3.2)
(3.2)
Свойства статистик Dn и  во многом повторяют отмеченные ранее свойства статистик Dn и . В частности,
во многом повторяют отмеченные ранее свойства статистик Dn и . В частности,  и n неограниченно возрастают, если проверяемая гипотеза неверна. Поэтому эту гипотезу следует отвергнуть, если наблюденное значение (или n , если применяется модифицированный критерий омега-квадрат) неправдоподобно велико, например, превосходит критическое значение, о котором будет сказано ниже.
и n неограниченно возрастают, если проверяемая гипотеза неверна. Поэтому эту гипотезу следует отвергнуть, если наблюденное значение (или n , если применяется модифицированный критерий омега-квадрат) неправдоподобно велико, например, превосходит критическое значение, о котором будет сказано ниже.
Важно отметить, что статистика Dn распределена иначе, чем Dn (1.1), а статистика – иначе, чем (1.5). Причина в том, что из-за подбора n по выборке функций F(x) и F(x, n) (в случае, если гипотеза о типе распределения верна) оказываются ближе к друг другу, чем F(x) и F(x, º). Поэтому при справедливости гипотезы статистика Dn, как правило, будет принимать существенно меньше значения, чем Dn. Аналогично соотносятся и .
Поскольку статистики (3.1), (3.2) при справедливости гипотезы имеют иные распределения, чем статистики Dn и , для их применения необходимы таблицы распределений или хотя бы таблицы критических значений. К сожалению, модифицированные статистики (3.1), (3.2) не обладают столь привлекательным свойством «свободы от распределения выборки», как их прототипы, поэтому для каждого параметрического семейства распределений нужны свои таблицы. Более того, распределения (3.1), (3.2) могут зависеть и от истинного значения неизвестного параметра (параметров).[4] К счастью, для так называемых «масштабно-сдвиговых» семейств, к которым относятся нормальные, показательное и многие другие практически важные распределения, этого последнего осложнения не возникает.
Таблицы распределений статистик (3.1), (3.2) к настоящему моменту составлены для многих семейств. Большинство из них рассчитаны методом случайных испытаний (методом Монте-Карло). Автор большинства этих расчетов М. Стефенс заметил, что зависимость результатов от объема выборки резко уменьшается, если вместо Dn , использовать их несколько преобразованные варианты. Стефенс утверждает, что для этих форм зависимость от n практически перестает сказываться, начиная с n = 5. ниже приводятся некоторые таблицы Стефенса.
Табл. 3.1 Модифицированные критерии для проверки нормальности, оба параметра неизвестны
| Статистика | Модифицированная форма | Верхние процентные точки 0.15 0.10 0.05 0.025 0.01 |
| Dn | 
| 0.775 0.819 0.895 0.955 1.035 |
|
| 
| 0.091 0.104 0.126 0.148 0.178 |
Табл. 3.2 Модифицированные критерии для проверки экспоненциальности, параметр неизвестен
| Статистика | Модифицированная форма | Верхние процентные точки 0.15 0.10 0.05 0.025 0.01 |
| Dn | 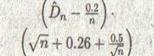
| 0.926 0.990 1.094 1.190 1.308 |
|
| 
| 0.149 0.177 0.224 0.273 0.337 |
Предельное (при n → ∞) распределение n известно, но вычисляется довольно сложно. Предельное распределение для найти не удалось, есть лишь приближенные формулы для критических значений, основанные на асимптотических разложениях. Сравнение расчетов по этим формулам с упомянутыми ранее таблицами показало их хорошее согласие. Как уже говорилось, для каждого параметрического семейства критические значения надо рассчитывать особо. Например, для нормального закона, оба параметра которого оцениваются по выборке, для больших z > 0 (т.е. для z → ∞).
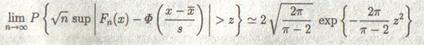 (3.3)
(3.3)
Если же математическое ожидание известно и равно, скажем, а, то по выборке приходится оценивать только дисперсию. В этом случае для больших z > 0
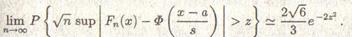 (3.4)
(3.4)
Эти приближенные формулы дают хорошие результаты для малых вероятностей и больших объемов выборок, то есть для вероятностей, начиная примерно с 0.20 (и меньше) и для объемов n, начиная примерно с 100 (и больше).
Date: 2015-11-14; view: 384; Нарушение авторских прав; Помощь в написании работы --> СЮДА... |