Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Анализ статистических данных с помощью
функции «Регрессия»
При необходимости выполнить более полный и точный расчет, включая вычисление остатков, стандартных ошибок, дисперсионный анализ и др. можно использовать функцию «Регрессия». Эта функция анализирует отношения переменных, связанных линейной зависимостью: Y=а+bX. Функция «Регрессия» входит в пакет «Анализ данных». Если же на Вашем компьютере пункт «Анализ данных» в меню «Сервис» отсутствует, то в меню «Сервис» - «Надстройки» выделите пункт «Пакет анализа» и щелкните ОК. После этого будет выполнена загрузка пакета из дистрибутива и подключение его к MS Excel.
Следуйте следующим инструкциям по использованию инструмента анализа «Регрессия»:
Расположите данные на листе MS Excel, как и ранее, по столбцам: переменная X слева, переменная Y справа. Освободите место для результатов регрессионного анализа справа от данных, по крайней мере, 16 столбцов.
Выберите функцию «Регрессия» и нажмите ОК. Появится диалоговое окно (рис. 1.3), в которое введите ссылки на интервалы значений Y и X. Если в диапазон включаются заголовки столбцов, то отметить пункт «Метки».
Опция «Константа – ноль» включается для прохождения линии регрессии через начало координат.

Рис. 1.3
3. «Выходной интервал» - область, где будут располагаться итоговые результаты и диаграммы. В этом поле достаточно ввести ссылку на левый верхний угол области шириной в 16 столбцов.
Флажок «Остатки» устанавливается, если требуется включить столбцы с предсказанными значениями Y и остатками. Остатки – это разница между статистическими данными и предсказанными.
Флажки: «График остатков» - выводятся точечные графики зависимости остатков от значений Xi; «График подбора» для вывода точечных графиков теоретических и статистических значений Yi; «График нормальной вероятности» (график вероятности нормального распределения) – зависимость Yi от автоматически формируемых интервалов персентелей1.
Ниже приведены примеры использования функции «Регрессия» для линейной и нелинейной зависимости исходных данных.
Результаты анализа для линейной зависимости представлены на рис. 1.4, где:
· Множественный R — коэффициент корреляции R;
· R-квадрат — коэффициент детерминации R2;
· Нормированный R - квадрат — нормированное значение коэффициента детерминации 2;
· Стандартная ошибка - стандартная ошибка оценки 3 ;
· Наблюдения — это число исходных наблюдений (n).
Результаты дисперсионного4 анализа используются для проверки значимости коэффициента детерминации.
-------------------------------------
1 Это характеристика набора данных, которые выражают ранги (значения) пунктов шкалы данных в виде процентов (от 0 до 100%), а не в виде чисел от 1 до n. В нашем случае в виде персентелей представляются значения Xi.
2 Нормированный R-квадрат – скорректированный (адаптированный, поправленный) коэффициент детерминации.
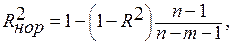
где n – число наблюдений, m - количество факторных признаков.
3 Стандартная ошибка = 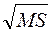 , определение MS – приведено ниже.
, определение MS – приведено ниже.
Для регрессионного уравнения в целом она выступает как степень точности прогнозов, которые базируются на уравнении. Стандартная ошибка — это мера ошибки предсказанного значения Y для отдельного значения X.
4 Дисперсия - мера рассеивания (отклонения от среднего) - средний квадрат отклонений индивидуальных значений признака от его средней величины. Дисперсия фактических значений результативного признака от вычисленных по уравнению определяется как
s 2 = å (Yi—Y(Xі))2/n, где: Yi -действительно наблюдаемые значения,
Y(Xі) - значения из уравнения регрессии, n-количество наблюдений.
Здесь:
· df - число степеней свободы. Для строки «Регрессия» – число переменных (количество факторных признаков – m).
· SS - сумма квадратов отклонений. Для строки «Регрессия» - сумма квадратов отклонений теоретических данных от среднего (å (Yi—Y(Xі))2 ), для строки «Остаток» - сумма квадратов отклонений эмпирических данных от теоретических, для строки «Итого» это сумма квадратов отклонений эмпирических данных от среднего.
· MS содержит значения дисперсии, которые рассчитываются по формуле MS=SS/df. Для строки Регрессия дисперсия называется факторной, для строки Остаток – остаточной.
· F – расчетное значение критерия Фишера. Вычисляется по формуле: F = MS(регрессия)/MS(остатки)
· Коэффициенты – это значения коэффициентов уравнения регрессии.
· Стандартная ошибка - стандартная ошибка коэффициентов уравнения регрессии.
· t – статистика - критерии вычисляемые как =коэффициет/стандартная ошибка.
· Нижние 95% и верхние 95% - границы доверительных интервалов для коэффициентов регрессии.
· В полученной таблице «Вывод остатка» «предсказанная цена» – данные в соответствии с уравнением регрессии, «остатки» – разница между статистическими и теоретическими данными.
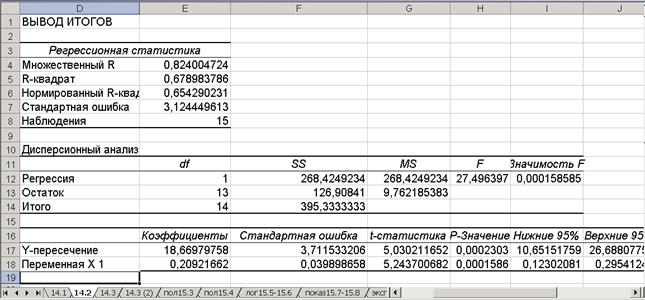
Рис. 1.4
Date: 2015-08-15; view: 456; Нарушение авторских прав; Помощь в написании работы --> СЮДА... |