Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Алгоритм обратного распространения
Среди различных структур нейронных сетей одной из наиболее известных и широко распространенных является многослойная структура, в которой каждый нейрон произвольного слоя связан со всеми аксонами нейронов предыдущего слоя или, в случае первого слоя, со всеми входами НС. Такие НС называются полносвязными. Когда в сети только один слой, алгоритм ее обучения с учителем довольно очевиден, так как правильные выходные состояния нейронов единственного слоя заведомо известны, и подстройка синаптических связей идет в направлении, минимизирующем ошибку на выходе сети. По этому принципу строится, например, алгоритм обучения однослойного персептрона. В многослойных же сетях оптимальные выходные значения нейронов всех слоев, кроме последнего, как правило, не известны, и двух или более слойный персептрон уже невозможно обучить, руководствуясь только величинами ошибок на выходах НС. Один из вариантов решения этой проблемы – разработка наборов выходных сигналов, соответствующих входным, для каждого слоя НС, что, конечно, является очень трудоемкой операцией и не всегда осуществимо. Второй вариант – динамическая подстройка весовых коэффициентов синапсов, в ходе которой выбираются, как правило, наиболее слабые связи и изменяются на малую величину в ту или иную сторону, а сохраняются только те изменения, которые повлекли уменьшение ошибки на выходе всей сети. Очевидно, что данный метод "тыка", несмотря на свою кажущуюся простоту, требует громоздких рутинных вычислений. И, наконец, третий, более приемлемый вариант – распространение сигналов ошибки от выходов НС к ее входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы. Этот алгоритм обучения НС получил название процедуры обратного распространения. Именно он будет рассмотрен в дальнейшем [6]. В многослойной сети различают два типа сигналов [4]:
- Функциональный сигнал. Это входной сигнал, поступающий в сеть и передаваемый вперед от нейрона к нейрону по всей сети. Такой сигнал достигает конца сети в виде выходного сигнала. Будем называть этот сигнал функциональным по двум причинам. Во-первых, он предназначен для выполнения некоторой функции на выходе сети. Во-вторых, в каждом нейроне, через который передается этот сигнал, вычисляется некоторая функция с учетом весовых коэффициентов.
- Сигнал ошибки. Сигнал ошибки берет свое начало на выходе сети и распространяется в обратном направлении. Он получил свое название благодаря тому, что вычисляется каждым нейроном сети на основе функции ошибки, представленной в той или иной форме.
Выходные нейроны составляют выходной слой сети. Остальные нейроны относятся к скрытым слоям. Таким образом, скрытые узлы не являются частью входа или выхода сети — отсюда они и получили свое название. Первый скрытый слой получает данные из входного слоя, составленного из сенсорных элементов. Результирующий сигнал первого скрытого слоя, в свою очередь, поступает на следующий скрытый слой, и т.д., до самого конца сети.
Любой скрытый или выходной нейрон многослойного персептрона может выполнять два типа вычислений.
- Вычисление функционального сигнала на выходе нейрона, реализуемое в виде непрерывной нелинейной функции от входного сигнала и синаптических весов, связанных с данным нейроном.
- Вычисление оценки вектора градиента (т.е. градиента поверхности ошибки по синаптическим весам, связанным со входами данного нейрона), необходимого для обратного прохода через сеть [4].
Согласно методу наименьших квадратов, минимизируемой целевой функцией ошибки НС является величина [6]:
 (3.1)
(3.1)
где  – реальное выходное состояние нейрона j выходного слоя N нейронной сети при подаче на ее входы p-го образа; djp – идеальное (желаемое) выходное состояние этого нейрона.
– реальное выходное состояние нейрона j выходного слоя N нейронной сети при подаче на ее входы p-го образа; djp – идеальное (желаемое) выходное состояние этого нейрона.
Суммирование ведется по всем нейронам выходного слоя и по всем обрабатываемым сетью образам. Минимизация ведется методом градиентного спуска, что означает подстройку весовых коэффициентов следующим образом [6]:
 (3.2)
(3.2)
Здесь wij – весовой коэффициент синаптической связи, соединяющей i-ый нейрон слоя n-1 с j-ым нейроном слоя n, h – коэффициент скорости обучения, 0<h<1.
 (3.3)
(3.3)
Здесь под yj, подразумевается выход нейрона j, а под sj – взвешенная сумма его входных сигналов, то есть аргумент активационной функции. Так как множитель dyj/dsj является производной этой функции по ее аргументу, из этого следует, что производная активационной функция должна быть определена на всей оси абсцисс. В связи с этим функция единичного скачка и прочие активационные функции с неоднородностями не подходят для рассматриваемых НС. В них применяются такие гладкие функции, как гиперболический тангенс или классический сигмоид с экспонентой [6]. В случае гиперболического тангенса
 (3.4)
(3.4)
Третий множитель ¶sj/¶wij, очевидно, равен выходу нейрона предыдущего слоя yi(n-1).
Что касается первого множителя в (3.3), он легко раскладывается следующим образом:
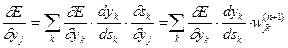 (3.5)
(3.5)
Здесь суммирование по k выполняется среди нейронов слоя n+1.
Введя новую переменную
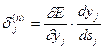 (3.6)
(3.6)
мы получим рекурсивную формулу для расчетов величин dj(n) слоя n из величин dk(n+1) более старшего слоя n+1 [6].
 (3.7)
(3.7)
Для выходного же слоя
 (3.8)
(3.8)
Теперь мы можем записать (3.2) в раскрытом виде:
 (3.9)
(3.9)
Иногда для придания процессу коррекции весов некоторой инерционности, сглаживающей резкие скачки при перемещении по поверхности целевой функции, (3.9) дополняется значением изменения веса на предыдущей итерации [6]
 (3.10)
(3.10)
где m – коэффициент инерционности, t – номер текущей итерации.
Таким образом, полный алгоритм обучения НС с помощью процедуры обратного распространения строится так [6]:
Шаг 1. Подать на входы сети один из возможных образов и рассчитать результат.
Шаг 2. Рассчитать d(N) для выходного слоя по формуле (3.8). Рассчитать по формуле (3.9) или (3.10) изменения весов Dw(N) слоя N.
Шаг 3. Рассчитать по формулам (3.7) и (3.9) (или (3.7) и (3.10)) соответственно d(n) и Dw(n) для всех остальных слоев, n=N-1,...1.
Шаг 4. Скорректировать все веса в НС
 (3.11)
(3.11)
где t – номер текущей итерации.
Шаг 5. Если ошибка сети существенна, перейти на Шаг 1. В противном случае – конец.
Date: 2015-11-15; view: 401; Нарушение авторских прав; Помощь в написании работы --> СЮДА... |