Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Интерпретация. Многоуровневая компьютерная организация
Многоуровневая компьютерная организация
Языки, уровни и виртуальные машины
Для эффективной работы человека с компьютером необходимо разработать какой-либо язык, на котором человеку было удобно задавать команды для выполнения компьютеру.
Данную проблему можно решить двумя способами. Оба способа подразумевают разработку новых команд, более удобных для человека, чем встроенные машинные команды.
Новые команды в совокупности формируют язык, который обозначим как Я1. Встроенные машинные команды тоже формируют язык, котороый обозначим как Я0.
Компьютер может выполнять только программы, написанные на его машинном языке Я0. Два способа решения проблемы различаются тем, каким образом компьютер будет выполнять программы, написанные на языке Я1, так как компьютеру доступен только машинный язык Я0.
Трансляция
Первый способ выполнения программы, написанной на языке Я 1, подразумевает замену каждой команды эквивалентным набором команд на языке Я 0. В этом случае компьютер выполняет новую программу, написанную на языке Я 0, вместо старой программы, написанной на Я 1.
Интерпретация
Второй способ означает создание программы на языке Я0, получающей в качестве входных данных программы, написанные на языке Я1. При этом каждая команда языка Я1 обрабатывается поочередно, после чего сразу выполняется эквивалентный ей набор команд языка Я0. Эта технология не требует составления новой программы на Я0. Программа, которая осуществляет интерпретацию, называется интерпретатором.
Общее:
- В обоих подходах компьютер в конечном итоге выполняет набор команд на языке Я0, эквивалентных командам Я1.
Различие:
- При трансляции вся программа Я1 переделывается в программу Я0, программа Я1 отбрасывается, а новая программа на Я0 загружается в память компьютера и затем выполняется.
- При интерпретации каждая команда программы на Я 1 перекодируется в Я 0 и сразу же выполняется. В отличие от трансляции, здесь не создается новая программа на Я 0, а происходит последовательная перекодировка и выполнение команд. С точки зрения интерпретатора, программа на Я 1 есть не что иное, как «сырые» входные данные.
Оба подхода широко используются как вместе, так и по отдельности.
Построим гипотетический компьютера или виртуальную машину, для которой машинным языком является язык Я1. Назовем такую виртуальную машину М1, а виртуальную машину для работы с языком Я0 — М0. Если бы такую машину М1 можно было бы сконструировать без больших денежных затрат, язык Я0, да и машина, которая выполняет программы на языке Я0, были бы не нужны. Можно было бы просто писать программы на языке Я1, а компьютер сразу бы их выполнял.
Даже с учетом того, что создать виртуальную машину, возможно, не удастся, люди вполне могут писать ориентированные на нее программы. Эти программы будут транслироваться или интерпретироваться программой, написанной на языке Я0, а сама она могла бы выполняться существующим компьютером. Другими словами, можно писать программы для виртуальных машин так, как будто эти машины реально существуют.
Трансляция и интерпретация целесообразны лишь в том случае, если языки Я0 и Я1 не слишком отличаются друг от друга. Это значит, что язык Я1 хотя и лучше, чем Я 0, но все же далек от идеала.
Решение проблемы — создание еще одного набора команд, которые в большей степени, чем Я 1 ориентированы на человека и в меньшей степени на компьютер. Этот третий набор команд также формирует язык, который обозначим как Я 2, а соответствующую виртуальную машину - М2.
Человек может писать программы на языке Я 2, как будто виртуальная машина для работы с машинным языком Я 2 действительно существует. Такие программы могут либо транслироваться на язык Я 1, либо выполняться интерпретатором, написанным на языке Я 1.
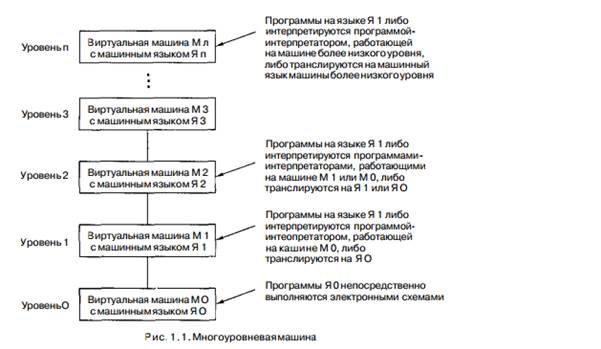
Изобретение целого ряда языков, каждый из которых более удобен для человека, чем предыдущий, может продолжаться до тех пор, пока не будет получен подходящий язык. Каждый такой язык использует своего предшественника как основу, поэтому можно рассматривать компьютер в виде ряда уровней.
Язык, находящийся в самом низу иерархической структуры, — самый примитивный, а тот, что расположен на ее вершине — самый сложный.
15. Аппаратная архитектура компьютера. Архитектуры SISD,MISD,MIMD,SIMD.
Архитектуры ЭВМ
Введение
Под архитектурой ЭВМ понимается функциональная и структурная организация машины, определяющая методы кодирования данных, состав, назначение, принципы взаимодействия технических средств и программного обеспечения.
Можно выделить следующие важные для пользователя группы характеристик ЭВМ, определяющих её архитектуру:
характеристики и состав модулей базовой конфигурации ЭВМ;
характеристики машинного языка и системы команд (количество и номенклатура команд, их форматы, системы адресации, наличие программно-доступных регистров в процессоре и т.п.), которые определяют алгоритмические возможности процессора ЭВМ;
технические и эксплуатационные характеристики ЭВМ;
состав программного обеспечения ЭВМ и принципы его взаимодействия с техническими средствами ЭВМ.
К наиболее общему принципу классификации ЭВМ и систем по типам архитектуры следует отнести разбиение их на однопроцессорные и многопроцессорные архитектуры.
Исторически первыми появились однопроцессорные архитектуры. Классическим примером однопроцессорной архитектуры является архитектура фон Неймана со строго последовательным выполнением команд: процессор по очереди выбирает команды программы и также по очереди обрабатывает данные (программа и данные хранятся в единственной последовательно адресуемой памяти).
По мере развития вычислительной техники архитектура фон Неймана обогатилась сначала конвейером команд, а затем многофункциональной обработкой, и по таксономии М. Флина получила обобщенное название компьютера с одним потоком команд и одним потоком данных.
Поток команд - это последовательность команд, выполняемых ЭВМ (системой), а поток данных - последовательность данных (исходная информация и промежуточные результаты решения задачи), обрабатываемых под управлением потока команд.
1. SISD-компьютеры
Рис. 1. SISD- архитектура
SISD (Single Instruction Single Data) или ОКОД - один поток команд, один поток данных. SISD компьютеры это обычные, "традиционные" последовательные компьютеры, в которых в каждый момент времени выполняется лишь одна операция над одним элементом данных (числовым или каким-либо другим значением).
При работе такой системы в мультипрограммном режиме, когда совместно решаются несколько задач (программы и исходные данные по каждой из них хранятся в оперативной памяти), обеспечивается параллельная работа устройств системы, происходит разделение времени и оборудования между совместно выполняемыми программами.
Но в каждый данный момент операционное устройство (АЛУ), поскольку оно является единственным, занимается обработкой информации по какой-то одной команде, т. е. одновременное преобразование информации в АЛУ по нескольким командам, принадлежащим разным участкам одной и той же программы или разным программам, невозможно. Основная масса современных ЭВМ функционирует в соответствии с принципом фон Неймана и имеет архитектуру класса SISD. Данная архитектура породила CISC, RISC и архитектуру с суперскалярной обработкой.
Компьютеры с CISC архитектурой
Компьютеры с CISC (Complex Instruction Set Computer) архитектурой имеют комплексную (полную) систему команд, под управлением которой выполняются всевозможные операции типа «память-память», «память-регистр», «регистр-память», «регистр-регистр». Данная архитектура характеризуется:
большим числом команд (более 200);
переменной длиной команд (от 1 до 11 байт);
значительным числом способов адресации и форматов команд;
сложностью команд и многотактностью их выполнения;
наличием микропрограммного управления, что снижает быстродействие и усложняет процессор.
Обмен с памятью в процессе выполнения команды делает практически невозможной глубокую конвейеризацию арифметики, т.е. ограничивается тактовая частота процессора, а значит, и его производительность.
Большинство современных компьютеров типа IBM PC относятся к CISC архитектуре, например, компьютеры с микропроцессорами 8080, 80486, 80586 (товарная марка Pentium).
Компьютеры с RISC архитектурой
Компьютеры с RISC (Reduced Instruction Set Computer) архитектурой содержат набор простых, часто употребляемых в программах команд. Основными являются операции типа «регистр-регистр».
Данная архитектура характеризуется:
сокращенным числом команд;
тем, что большинство команд выполняется за один машинный такт;
постоянной длиной команд;
небольшим количеством способов адресации и форматов команд;
тем, что для простых команд нет необходимости в использовании микропрограммного управления;
большим числом регистров внутренней памяти процессора.
Компьютеры с RISC-архитектурой «обязаны» иметь преимущество в производительности по сравнению с CISC компьютерами, за которое приходится расплачиваться наличием в программах дополнительных команд обмена регистров процессора с оперативной памятью.
Компьютеры с суперскалярной обработкой
Еще одной разновидностью однопотоковой архитектуры является суперскалярная обработка. Смысл этого термина заключается в том, что в аппаратуру процессора закладываются средства, позволяющие одновременно выполнять две или более скалярные операции, т.е. команды обработки пары чисел. Суперскалярная архитектура базируется на многофункциональном параллелизме и позволяет увеличить производительность компьютера пропорционально числу одновременно выполняемых операций. Способы реализации суперскалярной обработки могут быть разными.
Аппаратная реализация суперскалярной обработки применяется как в CISC, так и в RISC - процессорах и заключается в чисто аппаратном механизме выборки из буфера инструкций (или кэша инструкций) несвязанных команд и параллельном запуске их на исполнение. Этот метод хорош тем, что он «прозрачен» для программиста, составление программ для подобных процессоров не требует никаких специальных усилий, ответственность за параллельное выполнение операций возлагается в основном на аппаратные средства.
VLIW-архитектуры суперскалярной обработки. Второй способ реализации суперскалярной обработки заключается в кардинальной перестройке всего процесса трансляции и исполнения программ. Уже на этапе подготовки программы компилятор группирует несвязанные операции в пакеты, содержимое которых строго соответствует структуре процессора. Например, если процессор содержит функционально независимые устройства (сложения, умножения, сдвига и деления), то максимум, что компилятор может «уложить» в один пакет - это четыре разнотипные операции; (сложение, умножение, сдвиг и деление). Сформированные пакеты операций преобразуются компилятором в командные слова, которые по сравнению с обычными инструкциями выглядят очень большими. Отсюда и название этих суперкоманд и соответствующей им архитектуры - VLIW (Very Large Instruction Word - очень широкое командное слово). По идее, затраты на формирование суперкоманд должны окупаться скоростью их выполнения и простотой аппаратуры процессора, с которого снята вся «интеллектуальная» работа по поиску параллелизма несвязанных операций. Однако практическое внедрение VLIW-архитектуры затрудняется значительными проблемами эффективной компиляции.
Архитектуры класса SISD охватывают те уровни программного параллелизма, которые связаны с одиночным потоком данных. Они реализуются многофункциональной обработкой и конвейером команд.
Параллелизм циклов и итераций тесно связан с понятием множественности потоков данных и реализуется векторной обработкой. В таксономии компьютерных архитектур М. Флина выделена специальная группа однопроцессорных систем с параллельной обработкой потоков данных - SIMD.
2. SIMD-компьютеры
SIMD (Single Instruction Stream - Multiple Data Stream) или ОКМД - один поток команд и множество потоков данных. SIMD компьютеры состоят из одного командного процессора (управляющего модуля), называемого контроллером, и нескольких модулей обработки данных, называемых процессорными элементами.
Рис. 2. SIMD- архитектура
Управляющий модуль принимает, анализирует и выполняет команды. Если в команде встречаются данные, контроллер рассылает на все процессорные элементы команду, и эта команда выполняется на нескольких или на всех процессорных элементах.
Все процессорные элементы идентичны и каждый из них представляет собой совокупность управляюще-обрабатывающего органа (быстродействующего процессора) и процессорной памяти небольшой емкости. Процессорные элементы выполняют операции параллельно над разными потоками данных (ПД) под управлением общего потока команд (ПК), вследствие чего такие ЭВМ называются системами с общим потоком команд. В любой момент в каждом процессоре выполняется одна и та же команда, но обрабатываются различные данные. Реализуется синхронный параллельный вычислительный процесс.
Одним из преимуществ данной архитектуры считается то, что в этом случае более эффективно реализована логика вычислений. До половины логических инструкций обычного процессора связано с управлением выполнением машинных команд, а остальная их часть относится к работе с внутренней памятью процессора и выполнению арифметических операций. В SIMD компьютере управление выполняется контроллером, а "арифметика" отдана процессорным элементам. Возможны два способа построения компьютеров этого класса. Это матричная структура ЭВМ и векторно-конвейерная обработка.
Матричная архитектура
Суть матричной структуры заключается в том, что имеется множество процессорных элементов, исполняющих одну и ту же команду над различными элементами вектора (потоков данных), объединенных коммутатором. Каждый процессорный элемент включает схемы местного управления, операционную часть, схемы связи и собственную оперативную память. Изменение производительности матричной системы достигается за счет изменения числа процессорных элементов.
Основные их преимущества - высокая производительность и экономичность. Недостатки матричных систем, ограничивающие области их применения, заключаются в жесткости синхронного управления матрицей процессорных элементов и сложности программирования обмена данными между процессорными элементами через коммутатор.
Они применяются главным образом для реализации алгоритмов, допускающих параллельную обработку многих потоков данных по одной и той же программе (одномерное и двумерное прямое и обратное преобразования Фурье, решение систем дифференциальных уравнений в частных производных, операций над векторами и матрицами и др.). Матричные системы довольно часто используются совместно с универсальными однопроцессорными ЭВМ. Примером векторных супер-ЭВМ с матричной структурой является знаменитая в свое время система ILLIAC-IV.
Векторно-конвейерная архитектура
В отличие от матричной, векторно-конвейерная структура компьютера содержит конвейер операций, на котором обрабатываются параллельно элементы векторов и полученные результаты последовательно записываются в единую память. При этом отпадает необходимость в коммутаторе процессорных элементов, служащем камнем преткновения в матричных компьютерах.
Векторно-конвейерную структуру имеют однопроцессорные супер-ЭВМ серии VP фирмы Fujitsu; серии S компании Hitachi; C90, М90, Т90 фирмы Cray Research; Сгау-3, Сгау-4 фирмы Cray Computer и т.д. Общим для всех векторных суперкомпьютеров является наличие в системе команд векторных операций, допускающих работу с векторами определенной длины, допустим, 64 элемента по 8 байт. В таких компьютерах операции с векторами обычно выполняются над векторными регистрами.
ММХ технология
Еще одним примером SIMD-архитектуры является технология ММХ, которая существенно улучшила архитектуру микропроцессоров фирмы Intel. Технология MMX представляет собой компромиссное решение, объединяющее пути, используемые в классическом процессоре CISC-архитектуры (Pentium), в компьютерах с параллельной SIMD-архитектурой, с добавлением ряда простых (RISC) команд параллельной обработки данных. Она разработана для ускорения выполнения мультимедийных и коммуникационных программ с добавлением новых типов данных и новых инструкций. Технология в полной мере использует параллелизм SIMD-архитектуры и сохраняет полную совместимость с существующими операционными системами и приложениями для SISD.
Точно также, как однопроцессорные компьютеры, представлены архитектурами с одним потоком данных SISD и множеством потоков данных SIMD, так и многопроцессорные системы могут быть представлены двумя базовыми типами архитектур в зависимости от параллелизма данных:
3. MISD компьютеры
Рис.3. MISD-архитектура
MISD (Multiple Instruction Stream - Single Data Stream) или МКОД - множество потоков команд и один поток данных. MISD компьютеры представляет собой, как правило, регулярную структуру в виде цепочки последовательно соединенных процессоров П1, П2,..., ПN, образующих процессорный конвейер (рис. 3). В такой системе реализуется принцип конвейерной (магистральной) обработки, который основан на разбиении всего процесса на последовательно выполняемые этапы, причем каждый этап выполняется на отдельном процессоре. Одинарный поток исходных данных для решения задачи поступает на вход процессорного конвейера. Каждый процессор решает свою часть задачи, и результаты решения в качестве исходных данных передает на вход последующего процессора. К каждому процессору подводится свой поток команд, т. е. наблюдается множественный поток команд ПК1, ПК2,..., ПКN.
Вычислительных машин такого класса практически нет и трудно привести пример их успешной реализации. Один из немногих - систолический массив процессоров, в котором процессоры находятся в узлах регулярной решетки, роль ребер которой играют межпроцессорные соединения. Все процессорные элементы управляются общим тактовым генератором. В каждом цикле работы каждый процессорный элемент получает данные от своих соседей, выполняет одну команду и передает результат соседям.
В дальнейшем для MISD нашлась ещё одна адекватная организация вычислительной системы - распределенная мультипроцессорная система с общими данными. Наиболее простая и самая распространенная система этого класса - обычная локальная сеть персональных компьютеров, работающая с единой базой данных, когда много процессоров обрабатывают один поток данных. Впрочем, тут есть одна тонкость. Как только в такой сети все пользователи переключаются на обработку собственных данных, недоступных для других абонентов сети, MISD - система превращается в систему с множеством потоков команд и множеством потоков данных, соответствующую MIMD-архитектуре.
4. MIMD компьютеры
Рис. 4. MIMD-архитектура
MIMD (Multiple Instruction Stream - Multiple Data Stream) или МКМД - множество потоков команд и множество потоков данных. Эта категория архитектур вычислительных машин наиболее богата, если иметь в виду примеры ее успешных реализаций. В неё попадают симметричные параллельные вычислительные системы, рабочие станции с несколькими процессорами, кластеры рабочих станций и т.д. Уже довольно давно появились компьютеры с несколькими независимыми процессорами, но вначале на таких компьютерах был реализован только параллелизм заданий, то есть на разных процессорах одновременно выполнялись разные и независимые программы.
Так как только MIMD-архитектура включает все уровни параллелизма от конвейера операций до независимых заданий и программ, то любая вычислительная система этого класса в частных приложениях может выступать как SISD и SIMD-система. Например, если многопроцессорный комплекс выполняет одну-единственную программу без каких-либо признаков векторного параллелизма данных, то в этом конкретном случае он функционирует как обычный SISD-компьютер, и весь его потенциал остается невостребованным. Таким образом, употребляя термин «MIMD», надо иметь в виду не только много процессоров, но и множество вычислительных процессов, одновременно выполняемых в системе. MIMD-системы по способу взаимодействия процессоров (рис. 4.) делятся на системы с сильной и слабой связью.
16. Основные компоненты памяти: защелки, триггеры, регистры.
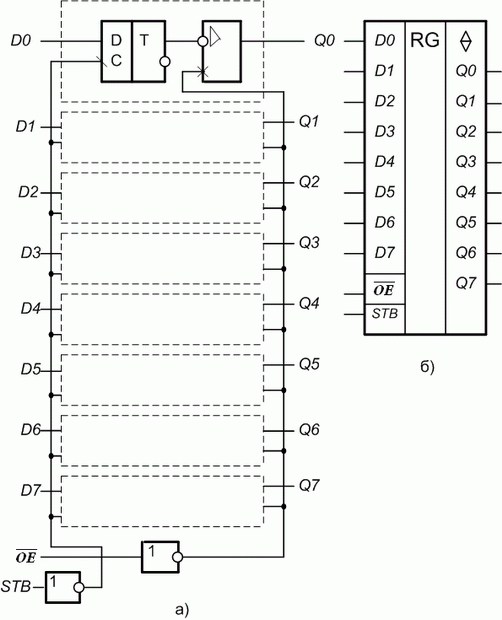
Простейший регистр представляет собой параллельное соединение нескольких триггеров (рис. 8.1,а). УГО регистра-защелки приведена на рис. 8.1,б. Если регистр построен на триггерах-защелках, то его называют регистр- "защелка". Как правило, в состав ИС регистра входят буферные усилители и элементы управления, например как показано на рис. 8.2,а. Здесь изображена функциональная схема 8-разрядного D -регистра-защелки КР580ИР82 с тремя состояниями на выходе. Его УГО представлено на рис. 8.2,б.
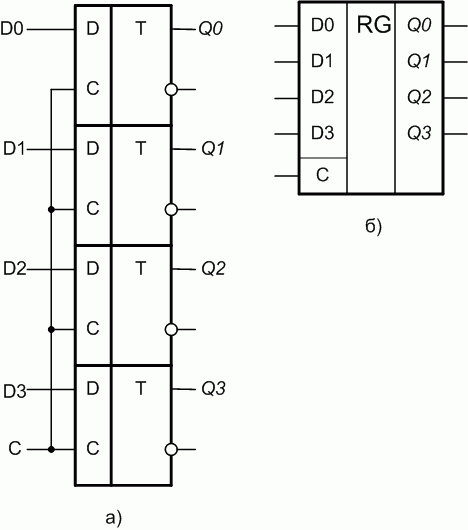
Рис. 8.1. Четырёх-разрядный регистр-"защелка" с прямыми выходами: а - функциональная схема; б - УГО
увеличить изображение
Рис. 8.2. Восьми-разрядный регистр-"защелка" КР580ВМ80А: а - функциональная схема; б - УГО
Третьим состоянием (первые два - это логический 0 и логическая 1) называется состояние выходов ИС, при котором они отключены и от источника питания, и от общей точки. Другие названия этого состояния - состояние высокого сопротивления, высокоимпедансное состояние, Z-состояние [1, с. 61 - 63; 2, с. 68 - 70].
Достигается это третье состояние специальным схемным решением [3, с. 117 - 118] в выходной части логических элементов, когда выходные транзисторы логических элементов заперты и не подают на выход ни напряжения питания, ни потенциала земли (не 0 и не 1).
Регистр КР580ИР82 состоит из 8 функциональных блоков (рис. 8.2,а). В каждый из них входит D -триггер-защелка с записью по заднему фронту и мощный выходной вентиль на 3 состояния. STB - стробирующий вход, 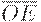 - разрешение передачи - сигнал, управляющий третьим состоянием: если
- разрешение передачи - сигнал, управляющий третьим состоянием: если 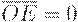 , то происходит передача информации со входов
, то происходит передача информации со входов  на соответствующие выходы
на соответствующие выходы 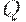 , если же
, если же 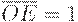 , все выходы переводятся в третье состояние. При
, все выходы переводятся в третье состояние. При 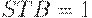 и ИС работает в режиме шинного формирователя - информация со входов передается на выходы в неизменном виде.
и ИС работает в режиме шинного формирователя - информация со входов передается на выходы в неизменном виде.
При подаче на 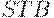 заднего фронта сигнала происходит "защелкивание" передаваемой информации в триггерах, то есть там запоминается то, что было на момент подачи
заднего фронта сигнала происходит "защелкивание" передаваемой информации в триггерах, то есть там запоминается то, что было на момент подачи 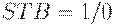 . Пока
. Пока 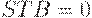 , буферный регистр будет хранить эту информацию, независимо от информации на D -входах. При подаче переднего фронта
, буферный регистр будет хранить эту информацию, независимо от информации на D -входах. При подаче переднего фронта 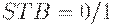 при сохранении состояние выходов будет изменяться в соответствии с изменением на соответствующих входах . Если же , то все выходные усилители переводятся в третье состояние. При этом, независимо от состояния входов, все выходы регистра
при сохранении состояние выходов будет изменяться в соответствии с изменением на соответствующих входах . Если же , то все выходные усилители переводятся в третье состояние. При этом, независимо от состояния входов, все выходы регистра  переводятся в третье состояние.
переводятся в третье состояние.
Все выводы регистра могут иметь активный нулевой уровень, что отображается на УГО в виде инверсных сигналов и обозначений выводов.
Существует множество разновидностей регистров, например, сдвиговые регистры [4, глава 8], в которых триггеры соединены между собой таким образом, что передают информацию последовательно от одного триггера к другому [5, стр. 109 - 122], но мы здесь остановимся на регистре-защелке и его применении.
Date: 2015-09-05; view: 1392; Нарушение авторских прав; Помощь в написании работы --> СЮДА... |