Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Метод k ближайших соседей
Метод ближайших соседей (англ. k-nearest neighbors algorithm, k-NN) [20] – это метрический алгоритм для автоматической классификации объектов. Основным принципом метода ближайших соседей является то, что объект присваивается тому классу, который является наиболее распространённым среди соседей данного элемента.
Соседи берутся исходя из множества объектов, классы которых уже известны, и, исходя из ключевого для данного метода значения k высчитывается, какой класс наиболее многочислен среди них. Каждый объект имеет конечное количество атрибутов (размерностей). Предполагается, что существует определенный набор объектов с уже имеющейся классификацией.
Определение дистанции
Алгоритм может быть применим к выборкам с большим количеством атрибутов (многомерным). Для этого перед применением нужно определить функцию дистанции. Классический вариант определения дистанции — дистанция в евклидовом пространстве.
Нормализация
Однако разные атрибуты могут иметь разный диапазон представленных значений в выборке (например атрибут А представлен в диапазоне от 0.1 до 0.5, а атрибут Б представлен в диапазоне от 1000 до 5000), то значения дистанции могут сильно зависеть от атрибутов с большими диапазонами. Поэтому данные обычно подлежат нормализации. При кластерном анализе есть два основных способа нормализации данных:
Мини-макс нормализация.
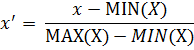
В этом случае все значения будут лежать в диапазоне от 0 до 1. Дискретные бинарные значения определяются как 0 и 1.
Z-нормализация.

где σ — стандартное отклонение. В этом случае большинство значений попадет в диапазон (-3;3)
Выделение значимых атрибутов
Некоторые значимые атрибуты могут быть важнее остальных, поэтому для каждого атрибута может быть задан в соответствие определенный вес (например вычисленный с помощью тестовой выборки и оптимизации ошибки отклонения). Таким образом, каждому атрибуту k будет задан в соответствие вес z_k, так что значение атрибута будет попадать в диапазон [0; z_kmax(k)] (для нормализованных значений по методу мини-макс). Например, если атрибуту присвоен вес 2.7, то его нормализованно-взвешенное значение будет лежать в диапазоне [0;2.7]
Взвешенный способ
Пример классификации k ближайших соседей. Тестовый образец (зеленый круг) должен быть классифицирован как синий квадрат (класс 1) или как красный треугольник (класс 2). Если k = 3, то она классифицируется как 2-й класс, потому что внутри меньшего круга 2 треугольника и только 1 квадрат. Если k = 5, то он будет классифицирован как 1ый класс (3 квадрата против 2ух треугольников внутри большего круга).
Определение класса
При таком способе во внимание принимается не только количество попавших в область определенных классов, но и их удаленность от нового значения.
Для каждого класса j определяется оценка близости:

где d(x, a) — дистанция от нового значения x до объекта а. У какого класса выше значение близости, тот класс и присваивается новому объекту.
Определение непрерывной величины
С помощью этого метода можно вычислять значение одного из атрибутов классифицируемого объекта на основании дистанций от попавших в область объектов и соответствующих значений этого же атрибута у объектов.

 — i-ый объект, попавший в область
— i-ый объект, попавший в область
 — это значение атрибута
— это значение атрибута  у заданного объекта
у заданного объекта 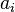
 — новый объект
— новый объект
 — k-ый атрибут нового объекта
— k-ый атрибут нового объекта
Используя выше изложенных методов классификации, для исследования эффективности задач банковского скоринга, я воспользовался очень удобной и комфортной программой, которой называется RapidMiner.
RapidMiner
RapidMiner (прежнее название YALE) — среда для проведения экспериментов и решения задач машинного обучения и интеллектуального анализа данных [21]. Эксперименты описываются в виде суперпозиций произвольного числа произвольным образом вложенных операторов, и легко строятся средствами визуального графического интерфейса RapidMiner.
RapidMiner — открытый программный продукт, свободно распространяемый под лицензией GNU AGPLv3, может работать как отдельное приложение, и как «интеллектуальный движок», встраиваемый в другие приложения, включая коммерческие.
Приложениями RapidMiner могут быть как исследовательские (модельные), так и прикладные (реальные) задачи интеллектуального анализа данных, включая анализ текста (text mining), анализ мультимедиа (multimedia mining), анализ потоков данных (data stream mining).
На данный момент существует много компаний нуждающихся в системах аналитики, но дороговизна и чрезмерная сложность данного ПО в большинстве случаев вынуждает отказаться от идеи построения собственной аналитической системы в пользу простого всем известного экселя. Также дополнительные расходы на обучение сотрудников, поддерживание дорогих систем хранения данных и т.д. И тут на помощь может прийти RapidMiner.
RapidMiner — инструмент созданный для дата майнинга, с основной идеей, что майнер (аналитик) не должен программировать при выполнении своей работы. При этом, как известно, для майнинга нужны данные, поэтому его снабдили достаточно хорошим набором операторов решающих большой спектр задач получения и обработки информации из разнообразных источников (базы данных, файлы и т.п.) [22].
Функциональные возможности: RapidMiner предоставляет более 400 операторов для всех наиболее известных методов машинного обучения, включая ввод и вывод, предварительную обработку данных и визуализацию.
Имеется встроенный язык сценариев, позволяющий выполнять массивные серии экспериментов. Концепция многоуровневого представления данных (multi-layered data view) обеспечивает эффективную и прозрачную работу с данными. Графическая подсистема обеспечивает многомерную визуализацию данных и моделей. Имеется пошаговый учебник, включающий популярное введение в машинное обучение и интеллектуальный анализ данных.
Реализация и технологии: Программное обеспечение написано целиком на Java, поэтому работает во всех основных операционных системах. Для представления экспериментов как суперпозиций операторов применяется язык XML. Встраивание в другие приложения осуществляется посредством Java API. Поддерживаются механизмы плагинов (plugin) и расширений (extension). Начальная версия была разработана в 2001 году группой Искусственного Интеллекта технологического университета в Дортмунде (Artificial Intelligence Unit of Dortmund University of Technology). Начиная с 2004 года исходные коды RapidMiner доступны на SourceForge.
В общем, RapidMiner обладает очень серьезным набором алгоритмов для обработки и анализа, включая обработку больших массивов данных. Очень красивая визуализация. Пакет обладает достаточно оригинальной концепцией. Работа с любым набором данных представляет собой процесс древовидного типа, в который можно, как в конструкторе, добавлять различные операторы ввода/вывода, обработки, визуализации, анализа и т.п. Дерево процесса представляет собой xml-файл.
2. ПРАКТИЧЕСКАЯ ЧАСТЬ: Программная реализация и тестирование методов классификации для решение задач банковского скоринга.
Разработанные алгоритмы проектирования информационных технологий интеллектуального анализа данных, а именно нейронных сетей, деревья решений и метод k ближайших соседей были протестированы на двух задачах банковского скоринга. Далее приведены решенные задачи:
1. Задача банковского скоринга в Германии (Scoring in Germany или Germany) [23];
2. Задача банковского скоринга в Австралии (Scoring in Australia или Australia) [24];
Выбор этих классификационных задач был обусловлен тем фактом, что они уже решались многими исследователями различными методами, поэтому с их помощью возможно не только протестировать классификаторы, но также и сравнить полученные ими результаты с уже известными результатами альтернативных алгоритмов [25].????
Описание немецкого кредитного базы данных: источником информации является профессор д-р Ханс Хофманн (институт статистики и эконометрики, Университет Гамбурга)[26].
Предоставляются два набора базы данных. Оригинальный (первоначальный) базы данных, предлагается, профессором Хоффманн, состоит из категорических/символических атрибутов и находится в файле "german.data".
Для алгоритмов, которые нужны численные атрибуты, университет Стратклайд выпустил файл "german.data-числовой". Этот файл был отредактирован и были добавлены несколько переменных индикаторов, чтобы сделать его пригодным для алгоритмов, которые не могут справиться с категориальными переменными. Соответственно в своей работе я выбрал "german.data-numeric".
Для начала была решена задача банковского скоринга в Германии.
Задача скоринга в Германии имеет следующие характеристики:
20 атрибутов, из которых 13 качественных и 7 численных, 2 класса («кредитоспособный клиент» и «некредитоспособный клиент»), и выборка содержала сведения о 700 кредитоспособных клиентах и 300 о некредитоспособных клиентах. Задача с описанием и набором данных была взята из [87].
Сначала, задача была решена нейронными сетями в RapidManer разумеется:
Добавляем нашу выборку в формате “CSV”, задаем класс и в параметре “Set Role” изменяем роль атрибута. “Split Data” – c помощью этого оператора разбиваем нашу выборку на подмножества в соответствии с указанным относительным размерам, внутри этого параметра разбиваем выборку на 0.7 (обучаемой) и на 0.3 (тестируемой) и выбираем функцию stratified sampling так как для нашей случае это необходимо. Далее все это соединяется с параметрами нейронных сетей и дальше отдается “Apply Model” для обучения и тестирования данных. Ну и в итоге в “Performance”, где
показывается статистические оценки эффективности задач классификации, получаем результат.

Рисунок 1. Neural Net
Результатом данного процесса с помощью алгоритмов нейронных сетей, дает точность = 70.67%.
PerformanceVector: accuracy: 70.67%
ConfusionMatrix:
| True: | ||
| 1: | ||
| 2: |
Аналогично предыдущей работе построим схему, но уже с тремя алгоритмами: нейронных сетей, деревья решений и метод k ближайших соседей. Здесь я добавил “Multiply” оператор, чтобы копировать все входные объекты для всех подключенных выходных портов.

Рисунок 2. Neural Net, Decision tree, k-NN
Итог данного тестирования показывает, что метод деревья решений, на этом этапе показывает эффективный результат по сравнение с другими методами. Кстати, еще здесь заметим, что метод нейронных сетей лучше стал работать, чем в предыдущем этапе.
accuracy: 65.00%
ConfusionMatrix:
| True: | ||
| 1: | ||
| 2: |
accuracy: 73.33%ConfusionMatrix:
| True: | 1 | 2 |
| 1: | 195 | 65 |
| 2: | 15 | 25 |
accuracy: 71.33%ConfusionMatrix:
| True: | 1 | 2 |
| 1: | 170 | 46 |
| 2: | 40 | 44 |
| k-nn | Neural net | D-tree |
| 65.00% | 71.33% | 73.33% |
Neural Net
В следующем этапе добавляем оператор “Loop” для тестирования определенного количества раз. Вес процесс исследуемой находится внутри оператора “Loop”.
 Рисунок 3. Несколько раз запускание процесса
Рисунок 3. Несколько раз запускание процесса
По сути, здесь ничего не меняем, только с помощью данных методов и оператора “Loop” проводим несколько итерации, а точнее 100.

Рисунок 4. Процесс внутри оператора “Loop”
После проведения 100 количество раз итерации, было найдено среднее значение каждого метода и среднеквадратичное отклонение.
Таким образом, результаты, полученные тремя методами, показывают, что метод деревья решений эффективнее, чем методы нейронных сетей и метод k ближайших соседей, с точки зрения текущего этапа.
| k-NN | Neural Net | D-tree | |
| Среднее значение | 0,66 | 0,71 | 0,72 |
| Среднеквадратичное отклонение | 0,021 | 0,024 | 0,023 |
Новый подход тестирование заключается в том, что создадим коллектив. Для достижения цели в этом подходе, мы используем оператор “Vote”. Он имеет подпроцессы. Подпроцесс должен иметь, по крайней мере два учащихся и оператор использует большинство голосов (для классификации).
Здесь одновременно запускается, все алгоритмы и в коллективной форме тестируют задачу исследования.

Рисунок 5. Коллективное тестирование
После объединения алгоритмов классификации, т.е метода коллектива были получены почти такие же результаты как раньше, а после изменения некоторых параметров настроек в методах классификации в RapidMiner, уже получили улучшенный результат.
Точность коллектива: 72.67%
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
2 Финансовый менеджмент: анализ финансовой деятельности предприятия: Учеб.пособие/Лукачев С.В., Ланский А.М., Ковалкин Ю.П., Ковалкин Д.Ю. https://ru.wikipedia.org/wiki/Финансовый_анализ
3 http://hcpeople.ru/credit_scoring/
4 Банк и банковские операции: О.И. Ларушина
5 http://hcpeople.ru/credit_scoring/
6 http://hcpeople.ru/credit_scoring/
7 Банки и банковское дело: В.А. Боровковой
8 Интеллектуальные информационные технологии в экономике и управлении: Настащук Наталья Александровна
9 Информационные технологии в экономике. Авторы: Моисеенко Е.В., Лаврушина Е.Г., редактор: Касаткина М.А.
10 https://sites.google.com/site/upravlenieznaniami/intellektualnye-informacionnye-sistemy-v-upravlenii-znaniami
11 Лепский В. Е. Субъективный подход - парадигма искусственного интеллекта. АИИ "Новости ИИ". 1999. №1.
12 Лепский В. Е. Субъективный подход - парадигма искусственного интеллекта. АИИ "Новости ИИ". 1999. №1.
13 Лепский В. Е. Субъективный подход - парадигма искусственного интеллекта. АИИ "Новости ИИ". 1999. №1.
14 http://www.machinelearning.ru/wiki/index.php?title=Классификация
15 http://www.machinelearning.ru/wiki/index.php?title=Классификация
16 Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: классификация и снижение размерности. — М.: Финансы и статистика, 1989.
17.
18 Левитин А. В. Глава 10. Ограничения мощи алгоритмов: Деревья принятия решения
19 http:/www.statsoft.ru/home/textbook/modules/stneunet.?html
20 Доррер М. Г. Психологическая интуиция искусственных нейронных сетей, Дисс. … 1998
21 http://www.machinelearning.ru/wiki/index.php?title=Метод_ближайшего_соседа
22 http://www.machinelearning.ru/wiki/index.php?title=RapidMiner
23 https://habrahabr.ru/post/269427/
24 Frank, A., Asuncion, A. UCI Machine Learning Repository. Irvine, University of California, School of Information and Computer Science, 2010. URL: http://archive.ics.uci.edu/ml.
25 Frank, A., Asuncion, A. UCI Machine Learning Repository. Irvine, University of California, School of Information and Computer Science, 2010. URL: http://archive.ics.uci.edu/ml.
26 Huang, J.-J., Tzeng, G.-H., Ong, Ch.-Sh. Two-stage genetic programming (2SGP) for the credit scoring model. Applied Mathematics and Computation, 174, pp. 1039-105, 2006.
27 Statlog (German Credit Data) Data Set
Date: 2016-05-23; view: 2602; Нарушение авторских прав; Помощь в написании работы --> СЮДА... |