Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Архитектура многопользовательских СУБД
Основой эффективных бизнес-решений, формируемых с использованием информационных технологий, является архитектура информационной системы. Архитектура современной информационной системы базируется на принципах клиент-серверного взаимодействия программных компонентов информационной ситемы.
Под сервером понимают как элемент аппаратуры, предоставляющий совместно используемый сервис в сетевой среде, так и программный компонент, предоставляющий общий функциональный сервис другим программным компонентам. Клиентом аналогично могут являться как аппаратные средства, предоставляемые пользователю в сетевой среде, так и программный компонент, предоставляющий личный функциональный сервис.
В своем развитии клиент-серверные технологии прошли несколько этапов, в ходе которых сформировались различные модели систем «клиент-сервер». Реализация этих моделей основывается на выделении трех уровней представления в клиент-серверной архитектуре:
– уровень представлений реализует функции ввода и отображения данных;
– уровень обработки данных приложением, включающий набор за-просов, событий, правил, процедур и других вычислительных функций, реализующих предназначение автоматизированной информационной системы в конкретной предметной области;
– уровень доступа к данным (взаимодействия с базой данных), реализу-ющий функции хранения, извлечения, физического обновления и изменения данных.
Клиент-серверная архитектура (рис. 37) в вычислительной сети может быть реализована в различных вариантах, выбор которых определяется требованиями к информационной системе в части территориальной конфигурации, надежности, быстродействия и др.
Файл-серверная архитектура представляет собой наиболее простой случай распределенной обработкии данных, согласно которой на сервере располагаются только файлы данных. На клиентской части находятся не только приложения пользователей, но и средства управления базами данных.
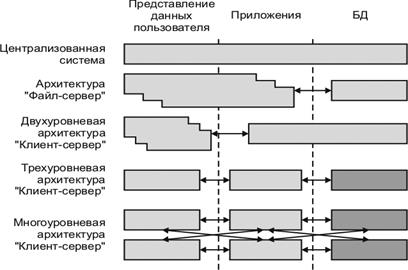
Рис. 37. Архитектура «клиент-сервер»
К основным достоинствам файл-серверных архитектур можно отнести простоту организации: привычные условия IBM PC в среде MS-DOS или Windows, удобные средства разработки графического пользовательского интерфейса, простые в использовании средства разработки систем БД и/или СУБД. Кроме того, файл-серверная организация позволяет соблюдать требования целостности и гарантированной надежности хранения информации, предъявляемые к БД.
Работающее с небольшими объемами информации и рассчитанное на применение в однопользовательском режиме, файл-серверное приложение может быть спроектировано и отлажено быстро. Часто, например, для ведения кадрового учета для небольшой компании достаточно иметь изолированную систему, работающую на отдельном компьютере. В этом случае требуется аккуратность конечных пользователей для надежного хранения и поддержания целостного состояния данных. Однако в более сложных случаях (например, при организации информационной системы поддержки проекта, выполняемого группой) файл-серверные архитектуры становятся недостаточными.
В целом в файл-серверной архитектуре мы имеем «толстого» клиента и очень «тонкий» сервер в том смысле, что почти вся работа выполняется на стороне клиента, а от сервера требуется только достаточная емкость дисковой памяти. В качестве примера системы, основанной на файл-серверной архитектуре, можно привести популярный в прошлом «сервер баз данных» Informix SE.
Двухуровневая клиент-серверная архитектура основана на использо-вании только сервера базы данных. При этом БД располагаются на сервере, клиентская часть содержит уровень представлений данных, на сервере находится база данных, а бизнес-логика может находиться либо на сервере, либо на клиенте и сервере одновременно. На стороне клиента выполняется код приложения, в который обязательно входят компоненты, поддерживающие интерфейс с конечным пользователем, производящие отчеты, выполняющие другие специфичные для приложения функции. Клиентская часть приложения взаимодействует с клиентской частью программного обеспечения управления базами данных, которая фактически является индивидуальным представителем СУБД для приложения. Интерфейс между клиентской частью приложения и клиентской частью сервера БД обычно основан на использовании языка SQL. Поэтому такие функции, как, например, предварительная обработка форм, предназначенных для запросов к базе данных, или формирование результирующих отчетов выполняются в коде приложения. Наконец, клиентская часть сервера баз данных, используя средства сетевого доступа, обращается к серверу баз данных, передавая ему текст оператора языка SQL.
Поясним процессы, происходящие на стороне сервера БД. В продуктах практически всех компаний сервер получает от клиента текст оператора (на языке SQL). Сервер производит компиляцию полученного оператора и, если компиляция завершилась успешно, происходит выполнение оператора.
Рассмотрим возможные действия операторов SQL. При выполнении операторов выборки данных на основе содержимого затрагиваемых запросом таблиц и с использованием поддерживаемых в БД индексов формируется результирующий набор данных. Серверная часть СУБД пересылает результат клиентской части, и окончательная обработка производится уже в клиентской части приложения. При выполнении операторов модификации или уничтожения объектов схемы базы данных (добавления или удаления столбцов существующих таблиц, изменения типа данных существующего столбца существующей таблицы и т. д.) выполняется серверная часть приложения. При выполнении оператора завершения транзакции сервер проверяет соблюдение всех отложенных ограничений целостности (к ним относятся ограничения, накладываемые на содержимое таблицы базы целиком или на несколько таблиц одновременно). Эта проверка относится к выполнению серверной части приложения. Таким образом, в клиент-серверной организации клиенты могут являться достаточно «тонкими», а сервер должен быть «толстым» настолько, чтобы быть в состоянии удовлетворить потребности всех клиентов. С другой стороны, разработчики и пользователи информационных систем, основанных на архитектуре «клиент-сервер», часто бывают неудовлетворены постоянно существующими сетевыми накладными расходами, которые следуют из потребности обращаться от клиента к серверу с каждым очередным запросом. На практике распространена ситуация, когда для эффективной работы отдельной клиентской составляющей информационной системы в действительности требуется только небольшая часть общей БД. Для этого поддерживается локальный кэш общей базы данных на стороне каждого клиента, что является частным случаем концепции реплицированных БД. В этом случае для поддержки локального кэша программное обеспечение «клиента» должно содержать компонент управления базами данных – упрощенный вариант сервера БД.
Отдельная проблема − обеспечение согласованности кэшей и общей базы данных (возможны различные решения – от автоматической поддержки согласованности за счет средств базового программного обеспечения управления БД до полного перекладывания этой задачи на прикладной уровень). В любом случае клиенты становятся более «толстыми», при том что сервер «тоньше» не делается.
Итак, архитектура «клиент-сервер» кажется гораздо более дорогой, чем архитектура «файл-сервер». Требуется более мощная аппаратура (по крайней мере, для сервера) и существенно более развитые средства управления БД. Однако это верно лишь частично. Существенным преимуществом клиент-серверной архитектуры является ее масштабируемость и способность к развитию. При проектировании информационных систем, основанных на этой архитектуре, большее внимание следует обращать на грамотность общих решений. Увеличение масштабов информационной системы не порождает принципиальных проблем. Обычным решением становится замена аппаратуры сервера и, может быть, аппаратуры рабочих станций (если требуется переход к ло-кальному кэшированию баз данных). В любом случае практически не затрагивается прикладная часть информационной системы.
Традиционной является двухзвенная архитектура «клиент-сервер». В этом случае вся прикладная часть информационной системы выполняется на рабочих станциях системы, а на стороне сервера осуществляется только доступ к БД. Если логика прикладной части системы достаточно сложна, то такой подход порождает проблему «толстого» клиента. Каждая рабочая станция должна обладать достаточным набором ресурсов, чтобы быть в состоянии произвести прикладную обработку данных, поступающих от пользователя и/или из БД.
Проблемы, возникающие при использовании двухуровневой клиент-сер-верной архитектуры, могут быть решены применением трехуровневой клиент-серверной архитектуры. В этом случае прикладные программы помещаются на отдельные серверы приложений, с которыми через API-интерфейс (Application Program Interface) устанавливается связь клиентских рабочих станций. Работа клиентской части приложения сводится к вызову необходимых функций сервера приложения, которые назваются сервисами. Прикладные программы в свою очередь обращаются к серверу БД с помощью SQL-запросов. Такая организация позволяет повысить производительность информационных систем за счет:
– многократного повторного использования общих функций обработки данных в множестве клиентских приложений;
– параллельной работы сервера приложений и сервера БД;
– оптимизации доступа к базе данных через сервер приложений.
Многоуровневая архитектура «клиент-сервер» создается для территориально-распределенных предприятий и характеризуется в общем случае отношениями «многие-ко-многим» между рабочими станциями, серверами приложений и серверами БД.
Часто источником информации в Интернете являются БД. В этом случае наряду с Web-сервером функционирует сервер БД, с которого информация поступает на компьютер пользователя в виде Web-страниц.
Доступ к БД осуществляется в двух вариантах: на стороне Web-сервера и на стороне Web-клиента (рис. 38).

а

б
Рис. 38. Схемы доступа к БД в Интернете:
а) на стороне Web-сервера; б) на стороне клиента
Доступ к БД на стороне сервера реализуется следующим образом. Пользователь, просматривая Web-страницу, заполняет находящуюся на ней форму. Данные формы передаются на Web-сервер, который запускает специальную программу. Эта внешняя по отношению к Web-серверу программа преобразует параметры формы в SQL-запросы к серверу БД. Сервер БД обрабатывает запрос и возвращает результаты запроса программе, которая затем формирует требуемую Web-страницу и передает ее Web-серверу для передачи на компьютер пользователя.
В случае доступа к БД на стороне клиента используется язык программирования Java. На этом языке пишутся специальные программы для доступа к серверу БД, называемые апплетами (Java-applets), которые хранятся на Web-сервере. В Web-страницу вставляются ссылки на соответствующие апплеты. При работе пользователя с Web-страницей при необходимости нужный апплет загружается на компьютер пользователя и исполняется браузером. При исполнении апплет обращается напрямую к серверу БД, и необходимая информация загружается из базы данных в Web-страницу на компьютер пользователя.
В первом варианте основная часть программ выполняется на Web-сервере, что облегчает администрирование Web-сервера. Однако это может привести к большой загрузке Web-сервера и ухудшению оперативности получения информации. Второй вариант разгружает Web-сервер, но требует загрузки на компьютер клиента Java-апплетов и их исполнения средствами браузера.
Технология «клиент-сервер» создает мощную среду, которая сулит организациям множество реальных выгод. В частности, обеспечивает относительно недорогую платформу, которая обладает значительными вычислительными возможностями и легко настраивается для выполнения конкретных задач. Кроме того, при клиент-серверной обработке резко уменьшается сетевой трафик, так как через сеть передаются только результаты запросов. Груз файловых операций ложится в основном на компьютер, который намного мощнее клиентов и способен поэтому лучше обслуживать запросы. Для нагруженных сетей это означает, что нагрузка будет распределена более равномерно, чем в традиционных сетях на основе сервера. Сеть модели «клиент-сервер» уменьшает потребность компьютеров-клиентов в оперативной памяти, поскольку вся работа с файлами выполняется на сервере. Серверы в клиент-серверных системах способны хранить большое количество данных. Благодаря этому на компьютерах-клиентах освобождается значительный объем дискового пространства для других приложений.
Наконец, управление всей системой, включая контроль за ее безопасностью, становится намного проще, так как все файлы и данные централизованно размещаются на сервере или на небольшом числе серверов. Упрощается также резервное копирование.
Date: 2015-09-23; view: 1303; Нарушение авторских прав; Помощь в написании работы --> СЮДА... |