Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Операторы реляционной алгебры
Традиционные операции над множествами
Объединением (Union) двух отношений называется отношение, содержащее множество кортежей, принадлежащих либо первому, либо второму отношению.


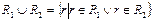
Пересечением (Intersect) отношений называется отношение, которое содержит множество кортежей, принадлежащих одновременно и первому и второму отношению.
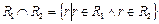
Разностью (Minus) отношений называется отношение, содержащее множество кортежей, принадлежащих 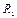 и не принадлежащих
и не принадлежащих  :
:
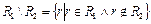
Декартовым произведением отношения  степени n со схемой
степени n со схемой 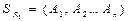 и отношения
и отношения  степени m со схемой
степени m со схемой 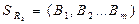 называют отношение, содержащее кортежи, полученные сцеплением каждого кортежа r отношения
называют отношение, содержащее кортежи, полученные сцеплением каждого кортежа r отношения  с каждым кортежем q отношения
с каждым кортежем q отношения  :
:
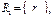
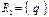
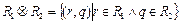
Специальные операции реляционной алгебры
Операция выбора (Select), заданная на отношении R в виде булевского выражения, определенного на атрибутах отношения R, называется отношение 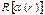 , включающее те кортежи из исходного отношения, для которых истинно условие выбора:
, включающее те кортежи из исходного отношения, для которых истинно условие выбора:
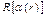 =
= 
Операция проектирования (Project) или вертикального выбора называется отношение  со схемой, соответствующей набору атрибутов B, содержащему кортежи, полученные из кортежей исходного отношения R путем удаления из них значений, не принадлежащих атрибутам из набора B.
со схемой, соответствующей набору атрибутов B, содержащему кортежи, полученные из кортежей исходного отношения R путем удаления из них значений, не принадлежащих атрибутам из набора B.
Операция соединения (Join) возвращает отношение, кортежи которого — сочетание двух кортежей, имеющих общее значение для одного или нескольких общих атрибутов этих двух отношений.
Операция деления (Divide) возвращает отношение, содержащее все значения одного атрибута отношения, которые соответствуют (в другом атрибуте) всем значениям во втором отношении.
Нормальные формы (normal forms) — набор стандартов проектирования данных. Общепринятыми считаются пять нормальных форм. Создание таблиц в соответствии с этими стандартами называется нормализацией.
В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм:
• первая нормальная форма (1NF);
• вторая нормальная форма (2NF);
• третья нормальная форма (3NF);
• нормальная форма Бойса — Кодда (BCNF);
• четвертая нормальная форма (4NF);
• пятая нормальная форма, или нормальная форма проекции-соединения (5NF или PJ/NF).
Основные свойства нормальных форм:
• каждая следующая нормальная форма улучшает свойства предыдущей;
• при переходе к следующей нормальной форме свойства предыдущих сохраняется.
Выполнение правил нормализации обычно приводит к разделению таблиц на две или больше таблиц с меньшим числом столбцов, выделению отношений первичный ключ – внешний ключ в меньшие таблицы, которые снова могут быть соединены с помощью операции объединения.
Одним из основных результатов разделения таблиц в соответствии с правилами нормализации является уменьшение избыточности данных в таблицах. Правила нормализации, подобно принципам объектного моделирования, развивались в рамках теории баз данных.
Первая нормальная форма (1NF) требует, чтобы на любом пересечении строки и столбца находилось единственное значение, которое должно быть атомарным. Кроме того, в таблице, удовлетворяющей первой нормальной форме, не должно быть повторяющихся групп.
Вторая нормальная форма (2NF): отношение R находится во второй нормальной форме в том и только в том случае, когда находится в первой нормальной форме (1NF) и каждый неключевой атрибут полностью зависит от первичного ключа.
Второе правило нормализации требует, чтобы любой неключевой атрибут зависел от всего первичного ключа. Следовательно, таблица не должна содержать неключевых атрибутов, зависящих только от части составного первичного ключа.
Третья нормальная форма (3NF): отношение R находится в третьей нормальной форме в том и только в том случае, если находится во второй нормальной форме (2NF) и каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
Третья нормальная форма повышает требования второй нормальной формы: она не ограничивается составными первичными ключами. Третья нормальная форма требует, чтобы ни один неключевой атрибут не зависел от другого неключевого атрибута. Любой неключевой атрибут должен зависеть только от первичного ключа.
5. Классификация моделей данных. Модель «Объект – свойство – отношение». Проектирование схемы базы данных.
Одними из основополагающих в концепции баз данных являются обобщенные категории «данные» и «модель данных».
Понятие «данные» в концепции баз данных – это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. Примеры данных: Иванов Сергей Викторович, $100 и т.д. Данные – не то же самое, что информация. Данные становятся информацией тогда, когда им задают определенную структуру, то есть придают им смысловое содержание. Поэтому центральным понятием в области баз данных является понятие модели данных.
Модель данных – это некоторая абстракция, которая, будучи применима к конкретным данным, позволяет трактовать их как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними.
На рис. 3 представлена классификация моделей данных.
Кроме трех рассмотренных уровней абстракции при проектировании БД существует еще один уровень, предшествующий им. Модель этого уровня должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эти модели называются инфологическими, или семантическими, и отражают в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и взаимосвязей.
Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, а даталогические модели уже поддерживаются уже конкретными СУБД.
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязычных переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
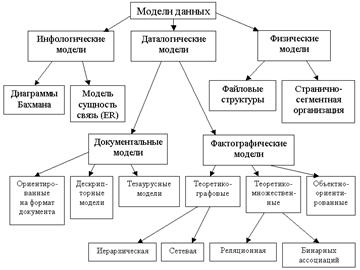
Дескрипторные модели – самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор – описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Обработка информации в таких базах данных велась исключительно по дескрипторам, то есть по тем параметрам, которые характеризовали документ, а не по самому тексту документа.
Теоретико-графовые модели данных отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объектов. В зависимости от типа графа выделяют иерархическую или сетевую модели. Исторически эти модели появились раньше, и в настоящий момент они используются реже, чем более современная реляционная модель данных. Однако до сих пор существуют системы, работающие на основе этих моделей, а одна из концепций развития объектно-ориентированных баз данных предполагает объединение принципов сетевой модели с концепцией реляционной.
Модель «Объект – свойство – отношение».
На использовании разновидностей ER-модели основано большинство современных подходов к проектированию баз данных. Модель была предложена Ченом (Chen) в 1976 г. Моделирование предметной области базируется на использовании графических диаграмм, включающих небольшое число разнородных компонентов. В связи с наглядностью представления концептуальных схем баз данных ER-модели получили широкое распространение в системах CASE, поддерживающих автоматизированное проектирование реляционных баз данных.
Основные понятия:
Сущность - это реальный или представляемый объект, информация о котором должна сохраняться и быть доступна. В диаграммах ER-модели сущность представляется в виде прямоугольника, содержащего имя сущности.
Связь - это графически изображаемая ассоциация, устанавливаемая между двумя сущностями. Эта ассоциация всегда является бинарной и может существовать между двумя разными сущностями или между сущностью и ей же самой (рекурсивная связь). В любой связи выделяются два конца (в соответствии с существующей парой связываемых сущностей), на каждом из которых указывается имя конца связи, степень конца связи (сколько экземпляров данной сущности связывается), обязательность связи (т.е. любой ли экземпляр данной сущности должен участвовать в данной связи). Связь представляется в виде линии, связывающей две сущности или ведущей от сущности к ней же самой. При этом в месте "стыковки" связи с сущностью используются трехточечный вход в прямоугольник сущности, если для этой сущности в связи могут использоваться много (many) экземпляров сущности, и одноточечный вход, если в связи может участвовать только один экземпляр сущности. Обязательный конец связи изображается сплошной линией, а необязательный - прерывистой линией. Связи делятся на три типа по множественности: Один-к-одному (1:1) экземпляр одной сущности связан с одним экземпляром другой сущности. Многие-ко-многим (М:М) экземпляр одной сущности связан с несколькими экземплярами другой сущности и наоборот, любой экземпляр второй сущности связан с несколькими экземплярами первой сущности. Как и сущность, связь – это типовое понятие, все экземпляры обеих пар связываемых сущностей подчиняются правилам связывания.
Атрибут – поименованная характеристика сущности. Его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущностей.
Проектирование схемы базы данных.
Основная цель проектирования БД – это сокращение избыточности хранимых данных, а следовательно, экономия объема используемой памяти, уменьшение затрат на многократные операции обновления избыточных копий и устранение возможности возникновения противоречий из-за хранения в разных местах сведений об одном и том же объекте.
Таким образом, при проектировании базы данных решаются две основные проблемы:
• Отображение объектов предметной области в абстрактные объекты модели данных так, чтобы это отображение не противоречило семантике предметной области и было по возможности лучшим (эффективным, удобным и т.д.). Часто эту проблему называют проблемой логического проектирования баз данных.
• Обеспечение эффективного выполнения запросов к базе данных, т.е. рациональное расположение данных во внешней памяти, создание полезных дополнительных структур (например, индексов) с учетом особенностей конкретной СУБД. Эту проблему называют проблемой физического проектирования баз данных.
Этапы проектирования
Концептуальное проектирование базы данных
Этап 1. Создание локальной концептуальной модели данных исходя из представлений о предметной области каждого из типов пользователей. Этап включает в себя следующие стадии:
1. определение типов сущностей;
2. определение типов связей;
3. определение атрибутов и связывание их с типами сущностей и связей;
4. определение доменов атрибутов;
5. определение атрибутов, являющихся первичными ключами;
6. создание диаграммы «сущность-связь»;
7. обсуждение локальных концептуальных моделей данных с конечными пользователями.
Логическое проектирование базы данных (для реляционной модели)
Этап 2. Построение и проверка локальной логической модели данных на основе представления о предметной области каждого из типов пользователей. Этап включает в себя следующие стадии:
1. определение набора отношений исходя из структуры локальной логической модели данных;
2. проверка модели с помощью правил нормализации;
3. проверка модели в отношении транзакций пользователей;
4. создание диаграмм "сущность-связь";
5. определение требований поддержки целостности данных;
6. обсуждение разработанных локальных логических моделей данных с конечными пользователями.
Этап 3. Создание и проверка глобальной логической модели данных. Этап включает в себя следующие стадии:
1. слияние локальных логических моделей данных в единую глобальную модель данных;
2. проверка глобальной логической модели данных;
3. проверка возможностей расширения модели в будущем;
4. создание окончательного варианта диаграммы «сущность-связь»;
5. обсуждение глобальной логической модели данных с пользователями.
Физическое проектирование базы данных (с использованием реляционной СУБД)
Этап 4. Перенос глобальной логической модели данных в среду СУБД. Этап включает в себя следующие стадии:
1. проектирование основных таблиц в среде СУБД;
2. реализация бизнес-правил предприятия в среде СУБД.
Этап 5. Проектирование физического представления базы данных. Этап включает в себя следующие стадии:
1. анализ транзакций;
2. выбор файловой структуры;
3. определение вторичных индексов;
4. анализ необходимости введения контролируемой избыточности данных;
5. определение требований к дисковой памяти.
Этап 6. Разработка механизмов защиты.
1. разработка пользовательских представлений (видов);
2. определение прав доступа.
Этап 7. Организация мониторинга и настройка функционирования системы.
6. Обеспечение целостности данных. Архитектура и модели «клиент-сервер» в технологии БД.
Целостность (от англ. integrity – нетронутость, неприкосновенность, сохранность, целостность) – понимается как правильность (корректность, правдоподобность, однозначность, непротиворечивость) данных в любой момент времени.
Для того чтобы гарантировать корректность и взаимную непротиворечивость данных, на базу данных накладываются некоторые ограничения, которые называют ограничениями целостности (data integrity constraints).
Поддержание целостности базы данных может рассматриваться как защита данных от неверных изменений или разрушений. Современные СУБД имеют ряд средств для обеспечения поддержания целостности (так же, как и средств обеспечения поддержания безопасности).
Выделяют четыре вида целостности:
• целостность по сущностям (декларативная целостность);
• целостность по ссылкам (ссылочная целостность – referential integrity);
• целостность, определяемая пользователем (семантическая целостность);
• физическая целостность (целостность файлов операционной системы).
Декларативная целостность – целостность по сущностям. Ограничения целостности, необходимые для обеспечения декларативной целостности обычно задаются при объявлении (декларировании, от слова declaration – «объявление») сущности в базе данных.
Для обеспечения декларативной целостности БД используются следующие механизмы:
• тип данных;
• размер типа данных;
• опция NOT NULL;
• домен;
• первичный ключ;
• уникальный ключ.
Тип данных – характеристика, задающая перечень всевозможных значений атрибута. В любых СУБД, так или иначе, реализованы такие типы данных, как целочисленный, символьный, дата/время и логический. При помощи этой характеристики задаются достаточно широкие диапазоны, которые затем можно ограничить (сузить) при помощи домена.
Размер типа данных – ограничение перечня возможных значений атрибута, заданного типом данных. Например, для типа данных СТРОКА всегда указывают максимально количество символов, которое может содержать в строке. Для типа данных ЦЕЛОЕ ЧИСЛО указывают либо максимальное количество цифр, которое может содержать в числе, либо максимальный объем памяти в байтах, которое может занимать число.
Опция NOT NULL – назначается атрибуту в том случае, если нужно, чтобы тот не мог содержать неопределенное значение.
Домен – это, также как и тип данных, характеристика, задающая перечень всевозможных значений атрибута, но, как правило, этот перечень более «узкий». Например, если атрибут ВОЗРАСТ имеет тип данных ЦЕЛОЕ ЧИСЛО, который задает диапазон от –32768 до 32767, то при попытке записать в этот атрибут отрицательное число, СУБД успешно выполнит данную команду. При помощи домена можно наложить ограничение, например, (ВОЗРАСТ > 0 И ВОЗРАСТ < 100), которое не позволит для атрибута ВОЗРАСТ использовать значения, выходящие за указанный диапазон.
Первичный Ключ – это минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся атрибутам. При выборе первичного ключа следует отдавать предпочтение несоставным ключам или ключам, составленным из минимального числа атрибутов. Нецелесообразно также использовать ключи с длинными текстовыми значениями (предпочтительнее использовать целочисленные атрибуты). Так, для идентификации студента можно использовать либо уникальный номер зачетной книжки, либо набор из фамилии. Не допускается, чтобы первичный ключ стержневой сущности (любой атрибут, участвующий в первичном ключе) принимал неопределенное значение (NULL). Иначе возникнет противоречивая ситуация: появится не обладающий индивидуальностью, и, следовательно не существующий экземпляр стержневой сущности. По тем же причинам необходимо обеспечить уникальность первичного ключа.
Уникальный ключ – ограничение целостности, накладываемое на набор атрибутов, и не допускающее повторение значений в указанных атрибутах. В отличие от первичного ключа, можно задать несколько уникальных ключей для одной сущности. Кроме того, уникальный ключ не требует отсутствия неопределенных значений в используемых атрибутах.
Ссылочная целостность – целостность по ссылкам. Данный вид целостности необходимо обеспечивать, когда данные, находящиеся в нескольких таблицах, связаны между собой и зависят друг от друга (ассоциации и обозначения). Для обеспечения ссылочной целостности базы данных используют внешние (или вторичные) ключи.
Внешний ключ – это набор атрибутов зависимой сущности, по значениям которых можно идентифицировать сущность, с которой она связана. Иными словами, значения атрибутов, входящих в состав внешнего ключа, выбираются из значений атрибутов, составляющий первичный ключ той сущности, на которую ссылается зависимая сущность. В общем случае значения атрибутов, составляющих внешний ключ, могут иметь неопределенные значения (NULL), но если это невозможно по смыслу реализуемой задачи, можно на эти атрибуты наложить дополнительные ограничения целостности, запрещающие использование неопределенных значений.
При указании внешнего ключа, связывающего две сущности, необходимо также определить необходимость выполнения так называемых каскадных действий. Каскадные действия – операции, выполняемые СУБД автоматически (неявно) при возникновении того или иного события, вызванного чаще всего действиями пользователей.
В частности, необходимо определить, что случиться при попытке удаления целевой сущности, на которую ссылается внешний ключ? Например, при удалении поставщика, который осуществил, по крайней мере, одну поставку. Существует три возможности:
• Каскадирование: операция удаления «каскадируется» с тем, чтобы удалить также поставки этого поставщика.
• Ограничение: удаляются лишь те поставщики, которые еще не осуществляли поставок. Иначе операция удаления отвергается.
• Установка: для всех поставок удаляемого поставщика внешний ключ устанавливается в неопределенное значение, а затем этот поставщик удаляется. Такая возможность, конечно, неприменима, если данный внешний ключ не должен содержать NULL-значений.
Кроме этого, определяется что должно происходить при попытке обновления первичного ключа целевой сущности, на которую ссылается некоторый внешний ключ? Например, может быть предпринята попытка обновить номер поставщика, для которого имеется, по крайней мере, одна соответствующая поставка. Имеются те же три возможности, как и при удалении:
• Каскадирование: операция обновления «каскадируется» с тем, чтобы обновить также и внешний ключ в поставках этого поставщика.
• Ограничение: обновляются первичные ключи лишь тех поставщиков, которые еще не осуществляли поставок. Иначе операция обновления отвергается.
• Установка: для всех поставок такого поставщика внешний ключ устанавливается в неопределенное значение, а затем обновляется первичный ключ поставщика. Такая возможность, конечно, неприменима, если данный внешний ключ не должен содержать NULL-значений.
Архитектура и модели "клиент-сервер" в технологии БД.
Вычислительная модель «клиент-сервер» исходно связана с парадигмой открытых систем, которая появилась в 90-х годах и быстро эволюционировала. Сам термин «клиент-сервер» исходно применялся к архитектуре программного обеспечения, которое описывало распределение процесса выполнения по принципу взаимодействия двух программных процессов, один из которых в этой модели называли «клиентом», а другой – «сервером». Клиентский процесс запрашивал некоторые услуги, а серверный процесс обеспечивал их выполнение. При этом предполагалось, что один серверный процесс может обслужить множество клиентских процессов.
Основной принцип технологии «клиент-сервер» применительно к технологии баз данных заключается в разделении функций стандартного интерактивного приложения на три части:
1) Представление (Presentation Logic).
2) Обработка (Business Logic).
3) Хранение (Data manipulation Logic) и данные (Data).
Презентационная логика (Presentation Logic) - это интерфейс приложения. Сюда относятся все интерфейсные экранные формы, которые пользователь видит или заполняет в ходе работы приложения (для веб-приложений – это HTML-страницы, загружаемые при помощи браузера на компьютер пользователя). К этой же части относится все то, что выводится пользователю на экран как результаты выполнения запрошенных действий.
Основными задачами презентационной логики являются:
• формирование экранных изображений;
• чтение и запись в экранные формы информации;
• управление экраном, движением мыши, клавиатуры.
Бизнес-логика (Business Logic) – это исполняемая часть приложения, которая определяет алгоритмы решения конкретных задач приложения.
Эта часть приложения может находиться как на клиентском компьютере, так и на сервере.
Логика обработки данных (Data manipulation Logic) и данные (Data) – это часть функций приложения, которая чаще всего возложена на сервер. Это собственно данные, составляющие базу данных, и функции по управлению хранением данных на сервере.
В зависимости от распределения описанных выше трех функций между клиентом и сервером различают четыре модели «клиент-сервер» в технологии баз данных.
В модели файлового сервера (File Server, FS) презентационная логика и бизнес-логика располагаются на клиенте. На сервере располагаются файлы с данными, и поддерживается доступ к файлам. Клиент обращается к серверу с файловыми командами, а механизм управления всеми информационными ресурсами, собственно база метаданных, находится на клиенте.
Единственным достоинством этой модели можно считать факт разделения функций между клиентом и сервером и возможность доступа к файлам, хранящимся на сервере одновременно многим пользователям.
К недостаткам модели можно отнести:
• высокий сетевой трафик (пересылаются файлы целиком, даже полезной в нем является всего одна строка);
• узкий спектр операций манипулирования с данными, который определяется файловыми командами;
• отсутствие средств безопасности доступа к данным (только на уровне файловой системы).

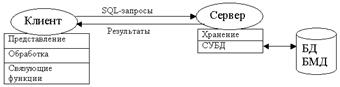
Отличием модели удаленного доступа к данным (Remote Data Access, RDA) (рис. 6) от модели файлового сервера является то, что ядро СУБД теперь расположено на сервере. Презентационная логика и бизнес-логика по-прежнему расположены на стороне клиента.
Достоинством данной модели можно считать значительное сокращение сетевого трафика, так как по сети передаются не запросы на ввод-вывод в файловой терминологии, а запросы на языке SQL. Иными словами, вместо файлов по сети передается только полезная информация, определенная пользователем при помощи языка структурированных запросов (Structured Query Language, SQL), которая выделяется из файлов на уже стороне сервера самой СУБД.
Недостатки:
• высокий сетевой трафик (несмотря на значительно сокращение сетевого трафика, по сравнению с модель файлового сервера, все-таки запросы на языке SQL при интенсивной работе клиентских приложений могут существенно загрузить сеть);
• дублирование кода приложений (запросы на получение одних и тех же данных присутствуют в виде копий в различных приложениях);
• пассивный сервер.
Модель сервера баз данных (Database Server, DBS) поддерживается большинством современных СУБД: Informix, Ingres, Sybase, Oracle, MS SQL Server. Основу данной модели составляет механизм хранимых процедур как средство программирования SQL-сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который иногда называется механизмом поддержки доменной структуры.
В этой модели бизнес-логика разделена между клиентом и сервером. На сервере бизнес-логика реализована в виде хранимых процедур – специальных программных модулей, которые хранятся в БД и управляются непосредственно СУБД. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены. Сервер возвращает клиенту данные, релевантные его запросу, которые требуются клиенту либо для вывода на экран либо для выполнения части бизнес-логики, которая расположена на клиенте. Трафик обмена информацией между клиентом и сервером резко уменьшается.
В данной модели сервер является активным, потому что не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в БД.
И хранимые процедуры, и триггеры хранятся в словаре БД, они могут быть использованы несколькими клиентами, что существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях.
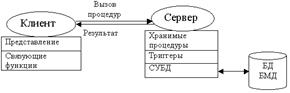
Недостатком данной модели является очень большая загрузка сервера, поскольку на него перекладывается большая часть бизнес-логики, предназначенной для обработки данных. Однако это же одновременно является и плюсом, поскольку теперь требования к клиентам резко уменьшаются. Иногда такую модель называют моделью с «тонким» клиентом. При построении приложений в модели сервера баз данных значительно упрощается организация обновления версий клиентских приложений, поскольку при обновлении приложения на стороне сервера, обновление части приложения на стороне клиента иногда даже не требуется. Кроме того, при использовании модели сервера баз данных увеличивается надежность и защищенность создаваемых приложений.
Для разгрузки модели была предложена трехуровневая модель – модель сервера приложений.
Модель сервера приложений (Application Server, AS) является расширением двухуровневой модели и в ней вводится дополнительный промежуточный уровень между клиентом и сервером. Этот промежуточный уровень содержит один или несколько серверов приложений.
Здесь в наибольшей степени выражен принцип разделения функций, поскольку каждая из трех функций расположена теперь на отдельных компьютерах: презентационная логика находится на клиенте, базнес-логика реализована на серверах приложений, а данные хранятся на сервере баз данных.
Нужно отметить, что эта модель обладает большей гибкостью, чем двухуровневые модели. Наиболее заметны преимущества модели сервера приложений в тех случаях, когда клиенты выполняются сложные аналитические расчеты над базой данных, которые относятся в области OLAP-приложений (On-line analytical processing). В этой модели большая часть бизнес-логики клиента изолирована от возможностей расширенного SQL, реализованного в конкретной СУБД, и может быть выполнена на стандартных языках программирования, таких как C, C++, Object Pascal, Java. Это повышает переносимость системы, ее масштабируемость.

7. Язык SQL. Назначение и основные операторы языка SQL. Представления.
Непроцедурный язык SQL (Structured Query Language – структурированный язык запросов) ориентирован на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц. Особенность предложений этого языка состоит в том, что они ориентированы в большей степени на конечный результат обработки данных, чем на процедуру этой обработки. SQL сам определяет, где находятся данные, какие индексы и даже наиболее эффективные последовательности операций следует использовать для их получения: не надо указывать эти детали в запросе к базе данных.
Язык SQL делится на подмножества.
1) Язык определения данных (DDL – Data Definition Language) предоставляет пользователям средства указания типа данных и их структуры, а также средства задания ограничений для информации, хранимой в базе данных.
Операторы: CREATE, ALTER, DROP.
CREATE служит для создания любого типа объектов, из которых состоит БД (таблиц).
ALTER служит для изменения структуры любых объектов, из которых состоит БД.
DROP служит для удаления объектов из базы данных.
2) Язык манипулирования данными (DML – Data Manipulation Language) позволяет вставлять, обновлять и извлекать информацию из базы данных.
Операторы: SELECT, INSERT, DELETE, UPDATE.
Все запросы на получение практически любого количества данных из одной или нескольких таблиц выполняются с помощью единственного предложения SELECT.
Любая новая информация попадает в базу данных посредством использования оператора INSERT.
Оператор UPDATE используется для изменения существующих строк таблиц.
Оператор DELETE используется для удаления существующих строк таблиц.
3) Язык управления данными (DCL – Data Control Language) состоит из управляющих операторов.
Операторы – GRANT, REVOKE.
Оператор GRANT используется для предоставления привилегии, а оператор REVOKE – для изъятия привилегии, выданной оператором GRANT. Оба оператора могут использоваться как для объектных, так и для системных привилегий.
Объектная привилегия (object privilege) разрешает выполнение определенной операции над конкретным объектом (например, над таблицей). Название каждой из объектных привилегии совпадает с названием оператора, который она разрешает выполнять тому или иному пользователю над конкретным объектом базы данных. Примеры объектных привилегий: SELECT, DELETE, INSERT, UPDATE, REFERENCES.
Системная привилегия (system privilege) разрешает выполнение операций над целым классом объектов – над всеми объектами какого-то типа, принадлежащими конкретному пользователю, или вообще над всеми объектами какого-то типа во всей базе данных. При выдаче или изъятии системных привилегий не указывается название объекта, а
4) Язык управления транзакциями (TCL – Transaction Control Language) состоит из операторов, предназначенных для управления ходом выполнения транзакций.
Операторы: COMMIT, ROLLBACK, SAVEPOINT.
Транзакция представляет собой последовательность операторов языка SQL, которая рассматривается как некоторое неделимое действие над базой данных. В то же время, это логическая единица работы системы.
Существует три операторы, предназначенные для управления транзакциями:
1. COMMIT – явная фиксация транзакции;
2. ROLLBACK – явная отмена изменения в текущей транзакции;
3. SAVEPOINT – создание контрольной точки внутри транзакции (промежуточная фиксация транзакции с возможность отката к этой точке);
Идея представления (View) состоит в следующем: определить запрос, который предполагается использовать достаточно часто, сохранить его в базе данных в виде объекта ORACLE и разрешить пользователям обращаться к нему по имени, как к обычной таблице. Когда пользователь выбирает данные из представления, СУБД выполняет соответствующий запрос, организует результаты так, как определено в представлении, и выдает их пользователю. Для пользователя представление выглядит как таблица, из которой поступают данные. Однако на самом деле данные поступают через представление, из одного или нескольких других источников – исходных таблиц или других представлений.
Запрос, непосредственное выполнение которого можно заменить использованием представлений, может быть какой угодно сложности. В сущности, это и есть одно из назначений использования представлений – скрытие сложности запросов и структуры данных от пользователей.
Кроме того, представления обеспечивают дополнительный уровень безопасности базы данных, поскольку позволяют ограничивать диапазон строк и столбцов, возвращаемых пользователям.
Наконец, представления могут сделать работу с таблицами более удобной. При создании представлений можно как угодно называть имена столбцов, а также изменять порядок их отображения. Эта возможность часто используется тогда, когда необходимо подвести под некий общий стандарт, действующий внутри той или иной организации или рабочей группе, имена всех столбцов таким образом, чтобы они были понятным определенной категории пользователей.
Для создания представлений используется следующий синтаксис:
CREATE [OR REPLACE] VIEW имя_представления AS
оператор SELECT
[WITH CHECK OPTION]- применима к обновляемым представлениям
Удаление представлений, как и всех других объектов базы данных, осуществляется при помощи оператора DROP, например:
DROP VIEW имя_представления
Операции выборки из представлений – при помощи оператора SELECT.
Если к представлению можно применить операторы обновления (INSERT, UPDATE или DELETE), то представление является обновляемым (updateble), иначе оно является читаемым (read-only).
Ниже приведены критерии того, является ли представление обновляемым в SQL:
1. оно базируется на одной таблице;
2. оно должно включать первичный ключ таблицы;
3. оно не должно включать полей, полученных в результате применения функций агрегирования;
4. оно не может содержать спецификации DISTINCT;
5. оно не должно использовать GROUP BY или HAVING;
6. оно не должно использовать подзапросы;
7. оно может быть определено на другом представлении, но это представление должно быть обновляемым;
8. оно не может содержать константы, строки или выражения в списке выбираемых выходных полей;
9. для INSERT оно должно включать поля из таблицы, которые имеют ограничения NOT NULL.
8. Понятие транзакции и ее свойства. Операторы COMMIT, ROLLBACK.
Транзакция представляет собой последовательность операторов языка SQL, которая рассматривается как некоторое неделимое действие над базой данных. В то же время, это логическая единица работы системы.
Свойства:
1. Свойство атомарности выражается в том, что транзакция должна быть выполнена в целом или не выполнена вовсе.
2. Свойство согласованности гарантирует, что по мере выполнения транзакций данные переходят из одного согласованного состояния в другое — транзакция не разрушает взаимной согласованности данных.
3. Свойство изолированности означает, что конкурирующие за доступ к базе данных транзакции физически обрабатываются последовательно, изолированно друг от друга, но для пользователей это выглядит так, как будто они выполняются параллельно.
4. Свойство долговечности трактуется следующим образом: если транзакция завершена успешно, то те изменения в данных, которые были ею произведены, не могут быть потеряны ни при каких обстоятельствах (даже в случае последующих ошибок).
Фиксация транзакции — это действие, обеспечивающее запись на диск изменений в базе данных, которые были сделаны в процессе выполнения транзакции.
Откат транзакции — это действие, обеспечивающее аннулирование всех изменений данных, которые были сделаны операторами SQL в теле текущей незавершенной транзакции.
Существует три операторы, предназначенные для управления транзакциями:
1. COMMIT – явная фиксация транзакции;
2. ROLLBACK – явная отмена изменения в текущей транзакции;
3. SAVEPOINT – создание контрольной точки внутри транзакции (промежуточная фиксация транзакции с возможность отката к этой точке).
Журналы транзакций – это специальные файлы операционной системы, в которые СУБД записывает все изменения или транзакции, произведенные в базе данных.
Date: 2015-09-22; view: 1299; Нарушение авторских прав; Помощь в написании работы --> СЮДА... |