Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Вставки
На следующем, (i+1)-м каждом шаге алгоритма берем a[i+1] и вставляем на нужное место в готовую часть массива.
Поиск подходящего места для очередного элемента входной последовательности осуществляется путем последовательных сравнений с элементом, стоящим перед ним.
В зависимости от результата сравнения элемент либо остается на текущем месте(вставка завершена), либо они меняются местами и процесс повторяется.

#include "stdafx.h"
#include <iostream>
#include <math.h>
#include <ctime>
using namespace std;
int _tmain(int argc, _TCHAR* argv[])
{
setlocale(LC_ALL, "Russian");
int n;
cout << "Введите размер массива" << endl;
cin >> n;
cout << "Сортировка выбора " << n << " элеметнов \n";
srand(time(0));
int arr[50];
for (int idx = 0; idx<n; ++idx)
{
//arr[idx] = 50 -idx;
arr[idx] = rand()%100;
cout << arr[idx] << " ";
}
cout << endl;
//cout << sizeof(arr)/sizeof(*arr);
int min;
int jdx;
for (int idx = 0; idx < n; ++idx)
{
min = arr[idx];
for (jdx = idx - 1; jdx >= 0 && min < arr[jdx]; --jdx)
arr[jdx+1] = arr[jdx];
arr[jdx+1] = min;
}
cout << "\n";
for (int idx = 0; idx<n; ++idx)
{
cout << arr[idx] << " ";
}
cout << endl;
Внешняя сортировка СЛИЯНИЕМ.
Время работы сортировки слиянием составляет  . Пример работы процедуры показан на рисунке:
. Пример работы процедуры показан на рисунке:

#include "stdafx.h"
#include <iostream>
#include <math.h>
#include <ctime>
using namespace std;
void Merge(int *A, int first, int last)
{
int middle, start, final1, j;
int *mas=new int[100];
middle=(first+last)/2; //вычисление среднего элемента
start=first; //начало левой части
final1=middle+1; //начало правой части
for(j=first; j<=last; j++) //выполнять от начала до конца
if ((start<=middle) && ((final1>last) || (A[start]<A[final1])))
{
mas[j]=A[start];
start++;
}
else
{
mas[j]=A[final1];
final1++;
}
//возвращение результата в список
for (j=first; j<=last; j++)
A[j]=mas[j];
delete[]mas;
};
void MergeSort(int *A, int first, int last)
{
if (first<last)
{
MergeSort(A, first, (first+last)/2); //сортировка левой части
MergeSort(A, (first+last)/2+1, last); //сортировка правой части
Merge(A, first, last); //слияние двух частей
}
};
int _tmain(int argc, _TCHAR* argv[])
{
setlocale(LC_ALL, "Russian");
int n;
cout << "Введите размер массива" << endl;
cin >> n;
cout << "Сортировка слияния " << n << " элеметнов \n";
srand(time(0));
int *arr=new int[n];
for (int idx = 0; idx<n; ++idx)
{
arr[idx] = rand()%100;
cout << arr[idx] << " ";
}
cout << endl;
MergeSort(arr, 0, n - 1); //вызов сортирующей процедуры
cout << "\n";
for (int idx = 0; idx<n; ++idx)
{
cout << arr[idx] << " ";
}
cout << endl;
// float intermediatResult;
// cout.precision(20);
delete []arr;
arr = NULL;
system("pause");
return 0;
3. Усовершенствованные методы сортировок. Сортировка Шелла.
Пирамидальная сортировка
Сортировка ШЕЛЛА
Идея метода заключается в сравнение разделенных на группы элементов последовательности, находящихся друг от друга на некотором расстоянии. Изначально это расстояние равно d или N/2, где N — общее число элементов. На первом шаге каждая группа включает в себя два элемента расположенных друг от друга на расстоянии N/2; они сравниваются между собой, и, в случае необходимости, меняются местами. На последующих шагах также происходят проверка и обмен, но расстояние d сокращается на d/2, и количество групп, соответственно, уменьшается. Постепенно расстояние между элементами уменьшается, и на d=1 проход по массиву происходит в последний раз.
Далее, на примере последовательности целых чисел, показан процесс сортировки массива методом Шелла. Для удобства и наглядности, элементы одной группы выделены одинаковым цветом.
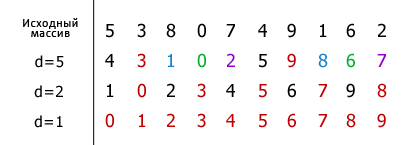
#include "stdafx.h"
#include <iostream>
#include <math.h>
#include <ctime>
using namespace std;
int _tmain(int argc, _TCHAR* argv[])
{
setlocale(LC_ALL, "Russian");
cout << "Введите размер массива" << endl;
int n;
cin >> n;
cout << "Сортировка шелла " << n << " элеметнов \n";
srand(time(0));
//int *arr=new int[n];
int arr[50];
for (int idx = 0; idx<n; ++idx)
{
arr[idx] = rand()%100;
cout << arr[idx] << " ";
}
cout << endl;
int d = n;
int temp, countCompare;;
while (d > 0)
{
d = d/2;
if (d!=0)
countCompare = n-d;
else
countCompare = 1;
for (int jdx = 0; jdx<countCompare; ++jdx)
{
for (int zdx = jdx; arr[zdx]>arr[zdx+d]; --zdx)
{
temp = arr[zdx];
arr[zdx] = arr[zdx+d];
arr[zdx+d] = temp;
}
}
}
cout << "\n";
for (int idx = 0; idx<n; ++idx)
{
cout << arr[idx] << " ";
}
cout << endl;
// float intermediatResult;
// cout.precision(20);
//delete []arr;
//arr = NULL;
system("pause");
return 0;
}
Метод пирамидальной сортировки был разработан английским математиком Дж. Уильямсом. В основе метода — удобная нумерация вершин двоичного дерева и связь дерева с массивом.
Рассмотрим полное двоичное дерево с ветвями высоты k. Такое дерево имеет 2(k+1) - 1 вершин (так что зависимость высоты дерева от числа вершин, грубо говоря, логарифмическая). Действительно, корневая вершина образует нулевой слой этого дерева, а далее в каждом горизонтальном слое число вершин вдвое больше, чем в предыдущем, и слой k содержит 2k вершин. Если перенумеровать вершины сверху вниз и слева направо, то легко убедиться, что вершина с номером s соединится с вершинами 2s и 2s + 1 следующего слоя (дети этой вершины).
Иерархическая сортировка основана на этом способе нумерации. Каждому индексу массива ставится в соответствие единственная вершина, и элементы массива (обозначим его через h[1:n]) могут рассматриваться, как вершины двоичного дерева. В терминах этого дерева и происходит сортировка массива, простая арифметическая связь номеров соединённых вершин позволяет перевести эти элементы в индексы.
Сортировка состоит из двух фаз. Первая фаза обеспечивает иерархическую упорядоченность массива: значение в каждой вершине должно быть хуже (так как сортировка традиционно осуществляется по возрастанию, под словом "хуже" понимается "больше"), чем у детей. Для этого используется операция утапливания элемента: текущий элемент сравнивается с худшим из элементов-детей, и если тот хуже, они меняются местами, на новом месте операция для текущего элемента повторяется. Так утапливается каждый элемент, начиная с номера [n/2] и кончая 1.
Вторая фаза сортировки состоит из последовательного выполнения следующих действий: взять самый худший элемент (он сейчас на первом месте, а должен быть на последнем), поменять его местами с последним, сократить на единицу число вершин в дереве, отцепив последний элемент, утопить верхний элемент дерева, чтобы восстановить иерархическую упорядоченность. В конце концов, когда все элементы массива окажутся отцеплены от дерева, массив будет полностью упорядочен.
Можно сделать вывод, что даже в самом плохом из возможных случаев Heapsort потребуется n*log n шагов
4. Быстрая сортировка, нахождение медианы массива.
Среди n элементов массива случайным образом выбирается барьерный (partition), затем в начало массива помещаются все элементы, меньшие барьерного, а в конец массива все большие. На каждом из 2 полученных подмножеств операция рекурсивно повторяется до тех пор, пока не будут получены подмножества, состоящие из 1 или 2 элементов.
В результате массив отсортирован, чтобы не усложнять условия завершения сканирования барьерный эл-т лучше не выносить в конец массива. Недостаток алгоритма – барьерный элемент не остается на месте.
Эффективность QuickSort’a. Алгоритм наиболее эффективно работает, если всякий раз выбирается медиана массива. Самый плохой случай, когда в качестве барьерного выбирается наибольший или наименьший элемент из массива. В результате потребуется (n-1) расщепление, а не log(n).
Медианой для n элементов называется элемент, меньший (или равный) половине из n элементов и больший (или равный) другой половине из n элементов. Например, медиана для элементов 16 12 99 95 18 87 10 равна 18. Метод определения медианы заключается в том, чтобы отсортировать n элементов, а затем выбрать средний элемент. Прием отыскивания медианы можно легко обобщить и для поиска среди n элементов k-го наименьшего числа. В этом случае поиск медианы – просто частный случай k = n/2.
Алгоритм, предложенный Ч. Хоаром, работает следующим образом: сначала применяется операция разделения из Quicksort с L = 1 и R = n, в качестве разделяющего значения x берется a[k]. В результате получаем индексы i и j, удовлетворяющие таким условиям:
· a[h] < x для всех h < i
· a[h] > x для всех h > j
· i > j
При этом мы сталкиваемся с одним из таких трех случаев:
1) Разделяющее значение x было слишком мало, и граница между двумя частями лежит ниже нужной величины k. Процесс разделения повторяется для элементов a[i] … a[R].
2) Выбранная граница x была слишком большой. Операции разделения следует повторить для элементов a[L] … a[j].
3) j < k < i: элемент a[k] разделяет массив на две части в нужной пропорции, следовательно, это то, что нужно.
Задача поиска медианы тесно связана с сортировкой, т.к. очевидный метод нахождения медианы заключается в том, чтобы отсортировать массив, а затем выбрать средний эл-т. Но значительно быстрее это можно сделать по методу разделения QuickSort’a,
5. Рекурсия, её особенности. Пример
Рекурсия – это такой способ организации вспомогательного алгоритма (подпрограммы), при котором эта подпрограмма (процедура или функция) в ходе выполнения ее операторов обращается сама к себе. Вообще, рекурсивным называется любой объект, который частично определяется через себя. Рекурсия обычно применяется в задачах, где необходимо перебрать множество вариантов. Рекурсия обычно применяется, если не существует других способов выполнить поставленную задачу. Рекурсию считают одним из видов цикла.
Рекурсивные функции обычно имеют три части:
1. Условие выхода из цикла.
2. Тело рекурсии, то есть код, который необходимо выполнять в каждой итерации.
3. Шаг рекурсии, в котором выполняется один или несколько самовызовов.
Procedure Factorial (N:integer; Var F:Extended);
Begin
If N<=1
Then F:=1
Else Begin Factorial(N-1, F); F:=F*N End
End;
Главное достоинство рекурсии – она позволяет с помощью конечного высказывания определить бесконечное множество объектов. С точки зрения программирования, с помощью конечной рекурсивной программы можно определить бесконечные вычисления, причем программа не будет содержать явных повторов.
В общем случае рекурсивную программу P можно выразить, как некоторую композицию команд из множества операций S, не содержащих P и самой P. Т.е. для выражения рекурсивных программ достаточно в языке программирования иметь понятие процедура (или подпрограмма), т.к. они позволяют присваивать любому оператору имя, с помощью которого к нему можно обратиться.
Программа называется прямо рекурсивной, если она содержит явную ссылку на себя. Если процедура P ссылается на себя через некоторую процедуру Y, то она называется косвенно рекурсивной. Аналогично операторам цикла рекурсивные процедуры могут приводить к не заканчивающимся вычислениям. Т.е. рекурсивные обращения к процедуре должны управляться некоторым условием, которое в определённый момент становится ложным.
Главная проблема рекурсии – каждая рекурсивная активация процедуры требует памяти для хранения промежуточных значений всех её переменных. Необходимо убедиться в том, что глубина рекурсии не только конечна, но и мала. При большой глубине рекурсии и неправильно написанной программе возможен выход с системной ошибкой.
function iter (i:integer):integer;Begin
if i<= 0 then iter = 1Else
Begin
K:=0;
F:=0;
While k<i do
Begin
k:=k+1;
f:=k*f;
end;
iter:=f;
end;
End.
Рекурсивная форма организации алгоритма обычно выглядит изящнее итерационной и дает более компактный текст программы, но при выполнении, как правило, медленнее и может вызвать переполнение стека (при каждом входе в подпрограмму ее локальные переменные размещаются в программном стеке).
6. Динамические структуры данных. Стек, очередь, список. Отличия списка от
стека и очереди. Виды списков.
Стек
Это структуры данных, которые меняют свои размеры в ходе решения задач. К динамическим структурам данных относятся: стеки, очереди, списки, деревья. Каждая компонента любой динамической структуры представляет собой запись, содержащую, по крайней мере, 2 поля: 1) тип указателя; 2) для размещения данных. Запись может содержать не один, а несколько указателей и полей данных. Поле данных может быть переменной, массивом, множеством или записью.
Стек. Это динамическая структура данных, добавление компонент в которую, исключение компонент из которой производится из одного конца, называемой вершиной стека. Стек работает по принципу: LIFO (Last-In, First-Out – поступивший последним обслуживается первым). Для формирования и работы со стеком необходимо иметь 2 переменные – указатели: 1-ая определяет вершину стека; 2-ая – вспомогательная.
Основные операции со стеком:
- объявление стека; - запись в стек;- извлечение из стека; - проверка наличия эл-та в стеке; Просматривать стек нельзя!
1. Объявление стека
type
ps=^Stack;
Stack=Record
data:Integer;
next:ps; end;
2. Создание стека
begin
New(head); (выделяем память под стек)
head^.data:=k (число, переменная, записывается в поле data)
head^.next:=nil;
end;
3. Добавление элемента в стек
var x: ps;
begin
New(x);
x^.data:=k;
x^.next:=head;
head=x;
end;
4. Удаление из стека
var x:ps;
begin
if head<>nil then
begin
x:=head;
1 head:=head^.next;
2 dispose(x);
end;
end;
Очередь:
Это динамическая структура данных, добавление компонент в кот. производится в один конец, а выборка осуществляется с др. конца. Очередь работает по принципу: FIFO (First-In, First-Out). Для формирования очереди и работы с ней необходимо иметь 3 переменные типа указатель: 1) определяет начало очереди; 2) конец очереди; 3) вспомогательная.
Основные операции с очередью:
- объявление очереди.
- запись в очередь.
- извлечение из очереди.
1. Объявление структуры данных.
type
pq=^queue
queue=record;
data: Integer;
next: pq;
end;
var pBegin, pEnd: pq;
2. Создание очереди.
procedure
begin
New(pBegin);
pBegin^.data:=StrToInt(Edit1.Text);
pBegin^.next:=nil;
pEnd:=pBegin;
end;
3. Добавление эл-та в очередь.
procedure
var x:pq;
begin
New(x);
x^.data:=StrToInt(Edit1.Text);
x^.next:=nil;
pEnd^.next:=x;
pEnd=x;
end;
4. Удаление эл-та из очереди (происходящих с начала очереди).
procedure
var x:pq;
begin
if pBegin<>nil then begin
x:=pBegin;
pBegin:=pBegin^.next;
dispose(x);
end;
Список:
Линейный список – структура данных, в произвольное место которого могут заноситься данные, а также изыматься по ключу. Ключ – число, либо строка символов. Ключ располагается в поле данных и занимает, как отдельное поле, так и бывает частью поля.
Основные отличия связанного списка от стека и очереди:
1) для чтения доступна любая компонента списка;
2) при чтении компонента не удаляется из списка;
3) новые компоненты можно добавлять в любое место списка.
Начальное формирование списка и добавление компоненты в конец списка выполняется, как формирование очереди.
Операции над списком: - формирование; - добавление компоненты в конец списка; - чтение компоненты с заданным ключом; - вставка компоненты в заданное место (обычно после компоненты с заданным ключом); - исключение компоненты с заданным ключом из списка.
Списки бывают однонаправленные, двунаправленные и кольцевые. В случае однонаправленного списка хранится только ссылка на следующий элемент. Голова однонаправленного списка хранит ссылку на первый элемент списка. Последний элемент списка хранит нулевую ссылку. Структура линейного двухсвязного списка имеет указатель на следующий элемент и указатель на предыдущий элемент. В крайних элементах соответствующие указатели должны содержать nil (в первом – предыдущий, в послед – следующий). Имеется и хвост, хранящий ссылку на последний элемент.
1. Объявление списка
type
pComp=^Comp;
Comp=record
D: Integer;
next: PComp; end;
var pBegin, pEnd: pcomp;
2. Создание списка и добавление эл-та аналогично очереди.
3. Поиск компоненты по заданному ключу. Выполняется в случае вставки, удаления и чтения по ключу.
var pCKey: pComp;
begin
pCKey:=pBegin;
while (pCKey<>nil) and (Key<>pCKey^.d) do
pCKey:=pCKey^.next; end;
Key – ключ который ищется в списке
4. Чтение компоненты с заданным ключом.
if pCKey<>nil then Edit1.Text:=IntToStr(pCKey^.d);
5. Добавление или вставка компонента после компонента с заданным ключом.
procedure
var pAux, pCKey: pComp;
Key: integer;
begin
поиск (как в 3)
New(pAux);
pAux^.d:=Strtoint(Edit1.Text);
pAux^.next:=pCKey^.next;
pCKey^.next:=pAux;
end;
6.Удаление компоненты с заданным ключом
вх. данные: Key, pBegin
pCKey:=pBegin;
while (pCKey<>nil) and (Key<>pCKey^.data) do
begin
pPreComp:=pCKey;
pCKey:=pCKey^.next;
end;
if pCKey<>nil then
begin
pPreComp^.next:=pCKey^.next;
dispose(pCKey);
end;
7. Постфиксная, префиксная, инфиксная записи выражения. Преобразование
выражения из инфиксной в постфиксную и префиксную формы. Вычисление
выражения в постфиксной форме с помощью стека.
Для представления выражения в линейной форме применяются следующие формы записи: префиксная запись; постфиксная запись; инфиксная запись.
В префиксной записи, называемой также польской префиксной записью, сначала записывается символ операции, а затем по порядку слева направо записываются операнды. Так, выражение (z+2)*(x+y) в префиксной записи будет иметь следующий вид: * + z 2 + x y. Польская префиксная запись не содержит скобок и позволяет однозначно определять порядок вычисления выражения.
В постфиксной записи, называемой также обратной польской записью или суффиксной записью, символ операции записывается после операндов. Выражение (z+2)*(x+y) в постфиксной записи будет иметь следующий вид: z 2 + x y + *.
Третьим типом записи выражений является инфиксная запись, используемая для представления выражений, как в математике, так и в языках программирования. Инфиксная запись – это стандартный способ записи выражений, при котором символ операции указывается между операндами. Однако инфиксная запись не позволяет представлять унарные операции.
Наиболее простым представлением выражения с точки зрения процесса трансляции является постфиксная запись. Однако префиксная запись более удобно обеспечивает обработку функций. Кроме того, префиксная запись позволяет вычислить выражение за один просмотр транслятора, но существенным недостатком при этом является то, что для каждой операции требуется предварительно знать число обрабатываемых ею операндов (унарная, бинарная, функция).
При вычислении выражений учитывается приоритет операций: сначала выполняются операции с более высоким приоритетом
Date: 2015-08-15; view: 472; Нарушение авторских прав; Помощь в написании работы --> СЮДА... |