Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Построение таблиц идентификаторов на основе хэш-функции
Существуют различные варианты хэш-функции. Получение результата хэш-функции — «хэширование» — обычно достигается за счет выполнения над цепочкой символов некоторых простых арифметических и логических операций. Самой простой хэш-функцией для символа является код внутреннего представления в ЭВМ литеры символа. Эту хэш-функцию можно использовать и для цепочки символов, выбирая первый символ в цепочке. Так, если двоичное ASCII представление символа А есть 00100001, то результатом хэширования идентификатора АТаblе будет код 00100001.
Хэш-функция, предложенная выше, очевидно не удовлетворительна: при использовании такой хэш-функции возникнет новая проблема — двум различным идентификаторам, начинающимся с одной и той же буквы, будет соответствовать одно и то же значение хэш-функции. Тогда при хэш-адресации в одну ячейку таблицы идентификаторов по одному и тому же адресу должны быть помещены два различных идентификатора, что явно невозможно. Такая ситуация, когда двум или более идентификаторам соответствует одно и то же значение функции, называется коллизией. Возникновение коллизии проиллюстрировано на рис.3 — двум различным идентификаторам A1 и А2 соответствуют два совпадающих значения хэш-функции n1 = n2.
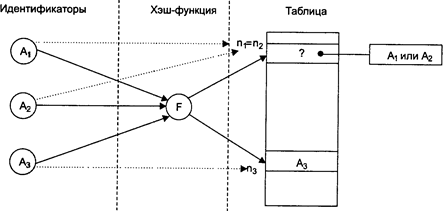
Рисунок 3 – Возникновение коллизии при использовании хэш-адресации
Естественно, что хэш-функция, допускающая коллизии, не может быть напрямую использована для хэш-адресации в таблице идентификаторов. Достаточно получить хотя бы один случай коллизии на всем множестве идентификаторов, чтобы такой хэш-функцией нельзя было пользоваться непосредственно. Но в примере взята самая элементарная хэш-функция.
Очевидно, что для полного исключения коллизий хэш-функция должна быть взаимно однозначной. Тогда любым двум произвольным элементам из области определения хэш-функции будут всегда соответствовать два различных ее значения. Теоретически для идентификаторов такую хэш-функцию построить можно, так как и область определения хэш-функции (все возможные имена идентификаторов), и область ее значений (целые неотрицательные числа) являются бесконечными счетными множествами.
Но практически это сделать исключительно сложно, т.к. в реальности область значений любой хэш-функции ограничена размером доступного адресного пространства в данной архитектуре компьютера. Организовать же взаимно однозначное отображение бесконечного множества на конечное даже теоретически невозможно. Если даже учесть, что длина принимаемой во внимание строки идентификатора в реальных компиляторах также практически ограничена — обычно она лежит в пределах от 32 до 128 символов (то есть и область определения хэш-функции конечна), то и тогда количество всех возможных идентификаторов все равно больше количества допустимых адресов в современных компьютерах. Таким образом, создать взаимно однозначную хэш-функцию практически ни в каком варианте невозможно. Следовательно, невозможно избежать возникновения коллизий.
Одним из способов решения проблемы коллизий является метод «рехэширования» (или «расстановки»). Согласно этому методу, если для элемента А адрес h(A), вычисленный с помощью хэш-функции, указывает на уже занятую ячейку, то необходимо вычислить значение функции n1 = h1(а) и проверить занятость ячейки по адресу n1. Если и она занята, то вычисляется значение h2(А), и так до тех пор, пока либо не будет найдена свободная ячейка, либо очередное значение hi(A) совпадет с h(A). В последнем случае считается, что таблица идентификаторов заполнена и места в ней больше нет — дается информация об ошибке размещения идентификатора в таблице. Особенностью метода является то, что первоначально таблица идентификаторов должна быть заполнена информацией, которая позволила бы говорить о том, что, ее ячейки являются пустыми (не содержат данных). Например, если используются указатели для хранения имен идентификаторов, то таблицу надо предварительно заполнить пустыми указателями.
Такую таблицу идентификаторов можно организовать по следующему алгоритму размещения элемента.
Шаг 1. Вычислить значение хэш-функции n = h(A) для нового элемента А.
Шаг 2. Если ячейка по адресу n пустая, то поместить в нее элемент А и завершить алгоритм, иначе i:=1 и перейти к шагу 3.
Шаг 3. Вычислить ni = hi(A). Если ячейка по адресу ni пустая, то поместить в нее элемент А и завершить алгоритм, иначе перейти к шагу 4.
Шаг 4. Если n = ni, то сообщить об ошибке и завершить алгоритм, иначе i:=i+1 и вернуться к шагу 3.
Когда поиск элемента А в таблице идентификаторов, организованной таким образом, будет выполняться по следующему алгоритму.
Шаг 1. Вычислить значение хэш-функции n = h(A) для нового элемента А.
Шаг 2. Если ячейка по адресу n пустая, то элемент не найден, алгоритм завершен, иначе сравнить имя элемента в ячейке n с именем искомого элемента А. Если они совпадают, то элемент найден и алгоритм завершен, иначе i:= 1 и перейти к шагу 3.
Шаг 3. Вычислить ni = hi(а). Если ячейка по адресу ni пустая или n = ni, то элемент не найден и алгоритм завершен, иначе сравнить имя элемента в ячейке ni с именем искомого элемента А. Если они совпадают, то элемент найден и алгоритм завершен, иначе i:=i+1 и повторить к шаг 3.
Итак, количество операций, необходимых для поиска или размещения в таблице элемента, зависит от заполненности таблицы. Естественно, функции hi(А) должны вычисляться единообразно на этапах размещения и поиска элемента. Вопрос только в том, как организовать вычисление функций hi(A).
Самым простым методом вычисления функции hi(А) является ее организация в виде hi(A) = (h(A) + рi) mod Nm, где рi — некоторое вычисляемое целое число, a Nm — максимальное число элементов в таблице идентификаторов. В свою очередь, самым простым подходом здесь будет положить рi = i. Тогда получаем формулу hi(A) = (h(A)+i) mod Nm. В этом случае при совпадении значений хэш-функции для каких-либо элементов поиск свободной ячейки в таблице начинается последовательно от текущей позиции, заданной хэш-функцией h(A).
Этот способ нельзя признать особенно удачным — при совпадении хэш-адресов элементы в таблице начинают группироваться вокруг них, что увеличивает число необходимых сравнений при поиске и размещении. Среднее время поиска элемента в такой таблице в зависимости от числа операций сравнения можно оценить следующим образом:
ТП = О((1-Lf/2)/(1- Lf)).
Здесь Lf — (load factor) степень заполненности таблицы идентификаторов — отношение числа занятых ячеек таблицы к максимально допустимому числу элементов в ней: Lf = N/Nm.
Рассмотрим в качестве примера ряд последовательных ячеек таблицы n1, n2, n3, n4, n5 и ряд идентификаторов, которые надо разместить в ней: A1, A2, A3, A4, A5 при условии, что h(A1) = h(A2) = h(Аз) = h(A4) = h(A5). Последовательность размещения идентификаторов в таблице при использовании простейшего метода рехэширования показана на рис. 4. В итоге после размещения в таблице для поиска идентификатора A1 потребуется 1 сравнение, для А2 — 2 сравнения, для Аз — 2 сравнения, для А4 — 1 сравнение и для A5 — 5 сравнений.
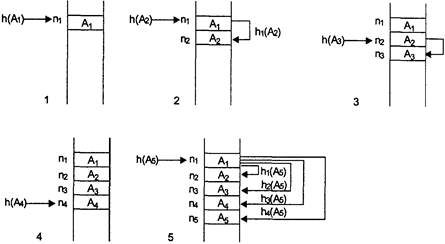
Рисунок 4 – Заполнение таблицы идентификаторов при использовании простейшего рехэширования
Даже такой примитивный метод рехэширования является достаточно эффективным средством организации таблиц идентификаторов при неполном заполнении таблицы. Имея, например, даже заполненную на 90 % таблицу для 1024 идентификаторов, в среднем необходимо выполнить 5,5 сравнений для поиска одного идентификатора, в то время как даже логарифмический поиск дает в среднем от 9 до 10 сравнений. Сравнительная эффективность метода будет еще выше при росте числа идентификаторов и снижении заполненности таблицы.
Среднее время на помещение одного элемента в таблицу и на поиск элемента в таблице можно снизить, если применить более совершенный метод рехэширования. Одним из таких методов является использование в качестве рi для функции hi(A) = (h(A)+pi)modNm последовательности псевдослучайных целых чисел p1, р2,..., pk. При хорошем выборе генератора псевдослучайных чисел длина последовательности k будет k=Nm. Тогда среднее время поиска одного элемента в таблице можно оценить следующим образом:
ЕП = О((1/Lf)*log2(1- Lf)).
Существуют и другие методы организации функций рехэширования hi(A), основанные на квадратичных вычислениях или, например, на вычислении по формуле:
hi(A) = (h(A)*i) mod Nm, если Nm - простое число. В целом рехэширование позволяет добиться неплохих результатов для эффективного поиска элемента в таблице (лучших, чем бинарный поиск и бинарное дерево), но эффективность метода сильно зависит от заполненности таблицы идентификаторов и качества используемой хэш-функции — чем реже возникают коллизии, тем выше эффективность метода. Требование неполного заполнения таблицы ведет к неэффективному использованию объема доступной памяти.
Date: 2015-07-24; view: 1539; Нарушение авторских прав; Помощь в написании работы --> СЮДА... |