Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Шины микропроцессорной системы
Самое главное, что должен знать разработчик микропроцессорных систем — это принципы организации обмена информацией по шинам таких систем. Без этого невозможно разработать аппаратную часть системы, а без аппаратной части не будет работать никакое программное обеспечение.
За более чем 30 лет, прошедших с момента появления первых микропроцессоров, были выработаны определенные правила обмена, которым следуют и разработчики новых микропроцессорных систем. Правила эти не слишком сложны, но твердо знать и неукоснительно соблюдать их для успешной работы необходимо. Как показала практика, принципы организации обмена по шинам гораздо важнее, чем особенности конкретных микропроцессоров. Стандартные системные магистрали живут гораздо дольше, чем тот или иной процессор. Разработчики новых процессоров ориентируются на уже существующие стандарты магистрали. Более того, некоторые системы на основе совершенно разных процессоров используют одну и ту же системную магистраль. То есть магистраль оказывается самым главным системообразующим фактором в микропроцессорных системах.
Обмен информацией в микропроцессорных системах происходит в циклах обмена информацией. Под циклом обмена информацией понимается временной интервал, в течение которого происходит выполнение одной элементарной операции обмена по шине. Например, пересылка кода данных из процессора в память или же пересылка кода данных из устройства ввода/вывода в процессор. В пределах одного цикла также может передаваться и несколько кодов данных, даже целый массив данных, но это встречается реже.
Циклы обмена информацией делятся на два основных типа:
· Цикл записи (вывода), в котором процессор записывает (выводит) информацию;
· Цикл чтения (ввода), в котором процессор читает (вводит) информацию.
В некоторых микропроцессорных системах существует также цикл «чтение-модификация-запись» или же «ввод-пауза-вывод». В этих циклах процессор сначала читает информацию из памяти или устройства ввода/вывода, затем как-то преобразует ее и снова записывает по тому же адресу. Например, процессор может прочитать код из ячейки памяти, увеличить его на единицу и снова записать в эту же ячейку памяти. Наличие или отсутствие данного типа цикла связано с особенностями используемого процессора.
Особое место занимают циклы прямого доступа к памяти (если режим ПДП в системе предусмотрен) и циклы запроса и предоставления прерывания (если прерывания в системе есть). Когда в дальнейшем речь пойдет о таких циклах, это будет специально оговорено.
Во время каждого цикла устройства, участвующие в обмене информацией, передают друг другу информационные и управляющие сигналы в строго установленном порядке или, как еще говорят, в соответствии с принятым протоколом обмена информацией.
Длительность цикла обмена может быть постоянной или переменной, но она всегда включает в себя несколько периодов сигнала тактовой частоты системы. То есть даже в идеальном случае частота чтения информации процессором и частота записи информации оказываются в несколько раз меньше тактовой частоты системы.
Чтение кодов команд из памяти системы также производится с помощью циклов чтения. Поэтому в случае одношинной архитектуры на системной магистрали чередуются циклы чтения команд и циклы пересылки (чтения и записи) данных, но протоколы обмена остаются неизменными независимо от того, что передается — данные или команды. В случае двухшинной архитектуры циклы чтения команд и записи или чтения данных разделяются по разным шинам и могут выполняться одновременно.
Шины микропроцессорной системы
Прежде чем переходить к особенностям циклов обмена, остановимся подробнее на составе и назначении различных шин микропроцессорной системы.
Как уже упоминалось, в системную магистраль (системную шину) микропроцессорной системы входит три основные информационные шины: адреса, данных и управления.
Шина данных — это основная шина, ради которой и создается вся система. Количество ее разрядов (линий связи) определяет скорость и эффективность информационного обмена, а также максимально возможное количество команд.
Шина данных всегда двунаправленная, так как предполагает передачу информации в обоих направлениях. Наиболее часто встречающийся тип выходного каскада для линий этой шины — выход с тремя состояниями.
Обычно шина данных имеет 8, 16, 32 или 64 разряда. Понятно, что за один цикл обмена по 64-разрядной шине может передаваться 8 байт информации, а по 8-разрядной — только один байт. Разрядность шины данных определяет и разрядность всей магистрали. Например, когда говорят о 32-разрядной системной магистрали, подразумевается, что она имеет 32-разрядную шину данных.
Шина адреса — вторая по важности шина, которая определяет максимально возможную сложность микропроцессорной системы, то есть допустимый объем памяти и, следовательно, максимально возможный размер программы и максимально возможный объем запоминаемых данных. Количество адресов, обеспечиваемых шиной адреса, определяется как 2N, где N — количество разрядов. Например, 16-разрядная шина адреса обеспечивает 65 536 адресов. Разрядность шины адреса обычно кратна 4 и может достигать 32 и даже 64. Шина адреса может быть однонаправленной (когда магистралью всегда управляет только процессор) или двунаправленной (когда процессор может временно передавать управление магистралью другому устройству, например контроллеру ПДП). Наиболее часто используются типы выходных каскадов с тремя состояниями или обычные ТТЛ (с двумя состояниями).
Как в шине данных, так и в шине адреса может использоваться положительная логика или отрицательная логика. При положительной логике высокий уровень напряжения соответствует логической единице на соответствующей линии связи, низкий — логическому нулю. При отрицательной логике — наоборот. В большинстве случаев уровни сигналов на шинах — ТТЛ.
Для снижения общего количества линий связи магистрали часто применяется мультиплексирование шин адреса и данных. То есть одни и те же линии связи используются в разные моменты времени для передачи как адреса, так и данных (в начале цикла — адрес, в конце цикла — данные). Для фиксации этих моментов (стробирования) служат специальные сигналы на шине управления. Понятно, что мультиплексированная шина адреса/данных обеспечивает меньшую скорость обмена, требует более длительного цикла обмена (рис. 2.1). По типу шины адреса и шины данных все магистрали также делятся на мультиплексированные и немультиплексированные.

Рис. 2.1. Мультиплексирование шин адреса и данных.
В некоторых мультиплексированных магистралях после одного кода адреса передается несколько кодов данных (массив данных). Это позволяет существенно повысить быстродействие магистрали. Иногда в магистралях применяется частичное мультиплексирование, то есть часть разрядов данных передается по немультиплексированным линиям, а другая часть — по мультиплексированным с адресом линиям.
Шина управления — это вспомогательная шина, управляющие сигналы на которой определяют тип текущего цикла и фиксируют моменты времени, соответствующие разным частям или стадиям цикла. Кроме того, управляющие сигналы обеспечивают согласование работы процессора (или другого хозяина магистрали, задатчика, master) с работой памяти или устройства ввода/вывода (устройства-исполнителя, slave). Управляющие сигналы также обслуживают запрос и предоставление прерываний, запрос и предоставление прямого доступа.
Сигналы шины управления могут передаваться как в положительной логике (реже), так и в отрицательной логике (чаще). Линии шины управления могут быть как однонаправленными, так и двунаправленными. Типы выходных каскадов могут быть самыми разными: с двумя состояниями (для однонаправленных линий), с тремя состояниями (для двунаправленных линий), с открытым коллектором (для двунаправленных и мультиплексированных линий).
Самые главные управляющие сигналы — это стробы обмена, то есть сигналы, формируемые процессором и определяющие моменты времени, в которые производится пересылка данных по шине данных, обмен данными. Чаще всего в магистрали используются два различных строба обмена:
· Строб записи (вывода), который определяет момент времени, когда устройство-исполнитель может принимать данные, выставленные процессором на шину данных;
· Строб чтения (ввода), который определяет момент времени, когда устройство-исполнитель должно выдать на шину данных код данных, который буде прочитан процессором.
При этом большое значение имеет то, как процессор заканчивает обмен в пределах цикла, в какой момент он снимает свой строб обмена. Возможны два пути решения (рис. 2.2):
· При синхронном обмене процессор заканчивает обмен данными самостоятельно, через раз и навсегда установленный временной интервал выдержки (tвыд), то есть без учета интересов устройства-исполнителя;
· При асинхронном обмене процессор заканчивает обмен только тогда, когда устройство-исполнитель подтверждает выполнение операции специальным сигналом (так называемый режим handshake — рукопожатие).

Рис. 2.2. Синхронный обмен и асинхронный обмен.
Достоинства синхронного обмена — более простой протокол обмена, меньшее количество управляющих сигналов. Недостатки — отсутствие гарантии, что исполнитель выполнил требуемую операцию, а также высокие требования к быстродействию исполнителя.
Достоинства асинхронного обмена — более надежная пересылка данных, возможность работы с самыми разными по быстродействию исполнителями. Недостаток — необходимость формирования сигнала подтверждения всеми исполнителями, то есть дополнительные аппаратурные затраты.
Какой тип обмена быстрее, синхронный или асинхронный? Ответ на этот вопрос неоднозначен. С одной стороны, при асинхронном обмене требуется какое-то время на выработку, передачу дополнительного сигнала и на его обработку процессором. С другой стороны, при синхронном обмене приходится искусственно увеличивать длительность строба обмена для соответствия требованиям большего числа исполнителей, чтобы они успевали обмениваться информацией в темпе процессора. Поэтому иногда в магистрали предусматривают возможность как синхронного, так и асинхронного обмена, причем синхронный обмен является основным и довольно быстрым, а асинхронный применяется только для медленных исполнителей.
По используемому типу обмена магистрали микропроцессорных систем также делятся на синхронные и асинхронные.
Лекция 48
Циклы обмена информацией
Циклы программного обмена
Рассмотрим для примера два довольно типичных случая программного обмена по магистрали микропроцессорной системы.
Первый пример — это обмен по мультиплексированной асинхронной магистрали Q-bus, предложенной фирмой DEC и широко применявшейся в микрокомпьютерах и промышленных контроллерах. Упрощенные временные диаграммы циклов чтения (ввода) и записи (вывода) по этой магистрали приведены на рис. 2.3 и 2.4.
Отметим, что в дальнейшем тексте знак «минус» перед названием сигнала говорит о том, что активный уровень сигнала низкий, пассивный — высокий, то есть сигнал отрицательный. Если минуса перед названием сигнала нет, то сигнал положительный, его низкий уровень пассивный, а высокий — активный.
На шине адреса/данных (AD) в начале цикла обмена (в фазе адреса) процессор (задатчик) выставляет код адреса. На этой шине используется отрицательная логика. Средний уровень сигналов на шине AD обозначает, что состояния сигналов на шине в данные временные интервалы не важны. Для стробирования адреса используется отрицательный синхросигнал -SYNC, выставляемый также процессором. Его передний (отрицательный) фронт соответствует действительности кода адреса на шине AD. Фаза адреса одинакова в обоих циклах записи и чтения.

Рис. 2.3. Цикл чтения на магистрали Q-bus.
Получив (распознав) свой код адреса, устройство ввода/вывода или память (исполнитель) готовится к проведению обмена. Через некоторое время после начала (отрицательного фронта) сигнала -SYNC процессор снимает адрес и начинает фазу данных.

Рис. 2.4. Цикл записи на магистрали Q-bus.
В фазе данных цикла чтения (рис. 2.3) процессор выставляет сигнал строба чтения данных -DIN, в ответ на который устройство, к которому обращается процессор (исполнитель), должно выставить свой код данных (читаемые данные). Одновременно это устройство должно подтвердить выполнение операции сигналом подтверждения обмена -RPLY.
Для сигнала -RPLY используется тип выходного каскада ОК, чтобы не было конфликтов между устройствами-исполнителями. Процессор, получив сигнал -RPLY, заканчивает цикл обмена. Для этого он снимает сигнал -DIN и сигнал -SYNC. Устройство-исполнитель в ответ на снятие сигнала -DIN должно снять код данных с шины AD и закончить сигнал подтверждения -RPLY. После этого процессор снимает сигнал -SYNC.
В фазе данных цикла записи (рис. 2.4) процессор выставляет на шину AD код записываемых данных и сопровождает его отрицательным сигналом строба записи данных -DOUT. Устройство-исполнитель должно по этому сигналу принять данные от процессора и сформировать сигнал подтверждения обмена -RPLY. Процессор, получив сигнал -RPLY, заканчивает цикл обмена. Для этого он снимает код данных с шины AD и сигнал -DOUT. Устройство-исполнитель в ответ на снятие сигнала -DIN должно закончить сигнал подтверждения -RPLY. После этого процессор снимает сигнал -SYNC.
То есть на данной магистрали адрес передается синхронно (без подтверждения его получения исполнителем), а данные передаются асинхронно, с обязательным подтверждением их выдачи или приема исполнителем. Отсутствие сигнала подтверждения -RPLY в течение заданного времени воспринимается процессором как аварийная ситуация. В принципе возможна и асинхронная передача адреса, что увеличивает надежность обмена, хотя может снижать его скорость.
Помимо циклов чтения и записи на магистрали Q-bus используются также и циклы типа «ввод-пауза-вывод» («чтение-модификация-запись»). Упрощенная временная диаграмма этого цикла представлена на рис. 2.5.

Рис. 2.5. Цикл «ввод-пауза-вывод» на магистрали Q-bus.
В этом цикле адресная фаза производится точно так же, как и в циклах чтения (ввода) и записи (вывода). Но в фазе данных процессор производит сначала чтение из заданного в адресной фазе адреса, а потом запись в тот же самый адрес. Для чтения используется строб чтения -DIN, а для записи – строб записи -DOUT. В ответ на сигнал -DIN устройство-исполнитель выдает свои данные на шину AD, а по сигналу -DOUT – принимает данные с шины AD. Как и в циклах чтения и записи, устройство-исполнитель подтверждает выполнение каждой операции сигналом подтверждения -RPLY. Понятно, что цикл «ввод-пауза-вывод» требует больше времени, чем каждый из циклов чтения или записи, но меньше времени, чем два последовательно произведенных цикла чтения и записи (так как для него нужна только одна адресная фаза). Сигнал -SYNC вырабатывается процессором в начале цикла «ввод-пауза-вывод» и держится до окончания всего цикла.
В качестве второго примера рассмотрим циклы обмена на синхронной немультиплексированной магистрали ISA (Industrial Standard Architecture), предложенной фирмой IBM и широко используемой в персональных компьютерах. Упрощенные циклы записи в устройство ввода/вывода и чтения из устройства ввода/вывода приведены на рис. 2.6 и 2.7.
Оба цикла начинаются с выставления процессором (задатчиком) кода адреса на шину адреса SA (логика на этой шине положительная). Адрес остается на шине SA до конца цикла. Фаза адреса, одинаковая для обоих циклов, заканчивается с началом строба обмена данными -IOR или -IOW. В течение фазы адреса устройство-исполнитель должно принять код адреса и распознать или не распознать его. Если адрес распознан, исполнитель готовится к обмену.
В фазе данных цикла чтения (рис. 2.6) процессор выставляет отрицательный сигнал чтения данных из устройства ввода/вывода -IOR. В ответ на него устройство-исполнитель должно выдать на шину данных SD свой код данных (читаемые данные). Логика на шине данных положительная. Через установленное время строб обмена -IOR снимается процессором, после чего снимается также и код адреса с шины SA. Цикл заканчивается без учета быстродействия исполнителя.

Рис. 2.6. Цикл чтения из УВВ на магистрали ISA.

Рис. 2.7. Цикл записи в УВВ на магистрали ISA.
Но так происходит только в случае основного, синхронного обмена. Кроме него на магистрали ISA также предусмотрена возможность асинхронного обмена. Для этого применяется сигнал готовности канала (магистрали) I/O CH RDY. Тип выходного каскада для данного сигнала — ОК, для предотвращения конфликтов между устройствами-исполнителями. При синхронном обмене сигнал I/O CH RDY всегда положительный. Но медленное устройство-исполнитель, не успевающее работать в темпе процессора, может этот сигнал снять, то есть сделать нулевым сразу после начала строба обмена. Тогда процессор до того момента, пока сигнал I/O CH RDY не станет снова положительным, приостанавливает завершение цикла, продлевает строб обмена. Конечно, слишком большая длительность этого сигнала рассматривается как аварийная ситуация. Для простоты понимания можно считать, что устройство-исполнитель формирует в данном случае отрицательный сигнал неготовности завершить обмен. На время этого сигнала обмен на магистрали приостанавливается.
Принципиальное отличие асинхронного обмена по магистрали ISA от асинхронного обмена по магистрали Q-bus состоит в следующем. Если в случае Q-bus сигнал подтверждения обязателен, и его должен формировать каждый исполнитель, то в случае ISA сигнал о неготовности исполнитель может не формировать, если он успевает работать в темпе процессора. Зато в случае Q-bus к концу цикла обмена процессор всегда уверен, что устройство-исполнитель выполнило требуемую операцию, а в случае ISA такой уверенности нет.
В фазе данных цикла записи по магистрали ISA (рис. 2.7) процессор выставляет на шину данных SD код записываемых данных и сопровождает их стробом записи данных в устройство ввода/вывода -IOW. Получив этот сигнал, устройство-исполнитель должно принять с шины SD код записываемых данных. Если оно не успевает сделать это в темпе процессора, то оно может снять на нужное время сигнал I/O CH RDY после получения переднего фронта сигнала -IOW. Тогда процессор приостановит окончание цикла записи.
Рассмотренные примеры, конечно, не раскрывают всех тонкостей обмена по упомянутым магистралям. Они всего лишь иллюстрируют главные принципы обмена по ним.
Циклы обмена по прерываниям
Циклы обмена в режиме прерываний строятся по тем же принципам, что и циклы программного обмена, но имеют ряд специфических особенностей.
Прерывания в микропроцессорных системах бывают двух основных типов:
· векторные прерывания, которые требуют проведения цикла чтения по магистрали;
· радиальные прерывания, которые не требуют никакого цикла обмена по магистрали.
Дело в том, что прерываний в микропроцессорной системе обычно бывает много. Поэтому процессору необходима информация о номере (или, как еще говорят, об адресе вектора) конкретного прерывания. Эта информация может быть передана процессору двумя путями.
При векторном прерывании код номера прерывания передается процессору тем устройством ввода/вывода, которое данное прерывание запросило. Для этого процессор проводит цикл чтения по магистрали, и по шине данных получает код номера прерывания. Шина адреса в данном цикле обычно не используется, так как устройство, запросившее прерывание, и так знает, что процессор будет обращаться именно к нему. В этом случае в магистрали достаточно всего одной линии запроса прерывания для всех устройств ввода/вывода. Так организованы прерывания, например, в магистрали Q-bus.
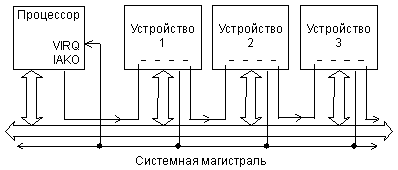
Рис. 2.8. Сигналы запроса и предоставления прерывания в магистрали Q-bus.
Схема распространения сигналов, участвующих в прерываниях на магистрали Q-bus, показана на рис. 2.8. Упрощенная временная диаграмма цикла запроса и предоставления магистрали представлена на рис. 2.9.

Рис. 2.9. Цикл запроса/предоставления векторного прерывания на магистрали Q-bus.
Запрос прерывания осуществляется отрицательным сигналом -VIRQ, который может формироваться каждым из устройств, запрашивающих прерывание. Тип выходного каскада для этого сигнала — ОК, чтобы избежать конфликтов между запрашивающими прерывания устройствами. Получив сигнал -VIRQ, процессор предоставляет прерывание (закончив предварительно выполнение текущей команды). Для этого он выставляет сигнал чтения данных -DIN и сигнал предоставления прерывания IAKO. Этот сигнал IAKO последовательно проходит через все устройства, которые могут запрашивать прерывания. Если устройство запросило прерывание, то оно не пропускает через себя этот сигнал. В результате получается, что если прерывания одновременно запросили два или более устройств, то сигнал предоставления прерывания получит только одно устройство, а именно то, которое ближе к процессору. Такой механизм разрешения конфликтов называется иногда географическим приоритетом (или цепочечным приоритетом, Daisy Chain). Получив сигнал IAKO, устройство, запросившее прерывание, должно снять свой сигнал -VIRQ.
Затем процессор проводит цикл безадресного чтения номера прерывания. В ответ на полученные сигналы -DIN и IAKO устройство, которому предоставлено прерывание, должно выдать на шину адреса/данных AD код номера прерывания (адреса вектора прерывания) и выставить сигнал подтверждения -RPLY. Процессор читает код номера прерывания и заканчивает цикл безадресного чтения снятием сигналов -DIN и IAKO.

Рис. 2.10. Структура связей для организации радиальных прерываний на магистрали ISA.
При радиальном прерывании в магистрали имеется столько линий запроса прерывания, сколько всего может быть разных прерываний. То есть каждое устройство ввода/вывода, желающее использовать прерывание, подает сигнал запроса прерывания по своей отдельной линии. Процессор узнает о номере прерывания по номеру линии, по которой пришел сигнал запроса прерывания. Никаких циклов обмена по магистрали при этом не требуется. В случае радиальных прерываний в систему обычно включается дополнительная микросхема контроллера прерываний, обрабатывающая сигналы запросов прерываний. Именно так организованы прерывания, например, в магистрали ISA.
Упрощенная структура связей между устройствами, участвующими в обмене по прерываниям, на магистрали ISA показана на рис. 2.10. Процессор общается с контроллером прерываний как по магистрали (чтобы задать ему режимы работы), так и вне магистрали (при обработке запросов на прерывание). Сигналы запросов прерываний IRQ распределяются между всеми устройствами магистрали. На каждую линию IRQ приходится одно устройство. Тип выходного каскада для этих линий — 2С, так как конфликты здесь не предусмотрены. Запросом прерывания является передний, положительный фронт сигнала IRQ. При одновременном поступлении сигналов IRQ от нескольких устройств порядок их обслуживания определяется контроллером прерываний.
Какой тип прерываний лучше — векторный или радиальный?
Векторные прерывания обеспечивают системе большую гибкость, в системе их может быть очень много. Но зато они требуют дополнительных аппаратурных узлов во всех устройствах, запрашивающих прерывания, для обслуживания циклов безадресного чтения.
Радиальных прерываний в системе обычно не очень много (от 1 до 16). При этом типе прерываний, как правило, требуется введение в систему специального контроллера прерываний. Каждое радиальное прерывание требует введения дополнительной линии в шину управления системной магистрали. Но работать с радиальными прерываниями проще, так как все сводится только к выработке единственного сигнала IRQ, и никаких циклов обмена по магистрали не требуется.
Циклы обмена в режиме ПДП
Циклы обмена в режиме прямого доступа к памяти выполняются по тем же правилам, что и циклы программного обмена, и циклы предоставления прерываний.
Прежде чем начать обмен в режиме ПДП, устройство, которому необходим ПДП, должно запросить ПДП и получить его. Процедура запроса и предоставления ПДП очень похожа на процедуру запроса и предоставления прерывания. В обоих случаях устройство, требующее обслуживания, посылает сигнал запроса процессору. Однако в случае ПДП процессор обязательно должен предоставить ПДП запросившему устройству с помощью специальных сигналов, так как на время ПДП процессор отключается от магистрали. А при радиальных прерываниях предоставления прерывания от процессора не требуется.
На магистрали Q-bus запрос и предоставление ПДП организуются подобно запросу и предоставлению прерывания. Упрощенная структура связей устройств, участвующих в ПДП, показана на рис. 2.11. Временная диаграмма запроса/предоставления ПДП очень близка к временной диаграмме запроса/предоставления прерывания (см. рис. 2.9).

Рис. 2.11. Структура связей запроса/предоставления ПДП на магистрали Q-bus.
Сигнал запроса ПДП, называемый -DMR, передается всеми устройствами, нуждающимися в ПДП, по одной линии магистрали. Тип выходного каскада на этой линии — ОК. Процессор, получив сигнал -DMR, выдает сигнал предоставления ПДП DMGO, аналогичный сигналу IAKO. Этот сигнал также проходит через все устройства последовательно, в результате чего ПДП получает только то устройство, которое находится ближе к процессору (географический приоритет). А затем устройство, получившее ПДП, проводит циклы обмена по магистрали, аналогично циклам программного обмена. В циклах ПДП информация читается из памяти и записывается в устройство ввода/вывода, или наоборот — читается из устройства ввода/вывода и передается в память.
На магистрали ISA запрос/предоставление ПДП очень напоминает организацию радиальных прерываний (рис. 2.12). Точно так же в системе существует контроллер ПДП, к которому сходятся сигналы запроса ПДП, называемые DRQ, и от которого расходятся сигналы предоставления ПДП, называемые -DACK. К каждому каналу ПДП (пара сигналов DRQ и -DACK) подключается только одно устройство, запрашивающее ПДП. Тип выходных каскадов для этих сигналов —2С. Устройство, нуждающееся в ПДП, посылает сигнал запроса DRQ и получает в ответ сигнал предоставления -DACK. После этого контроллер ПДП проводит циклы обмена по магистрали между устройством ввода/вывода и памятью.
Упрощенная временная диаграмма циклов ПДП на магистрали ISA показана на рис. 2.13.
На магистрали ISA используются раздельные стробы записи в память (-MEMW) и записи в устройства ввода/вывода (-IOW), а также раздельные стробы чтения из памяти (-MEMR) и чтения из устройств ввода/вывода (-IOR). Это позволяет за один цикл обмена ПДП читать информацию из памяти и записывать ее в устройство ввода/вывода или же читать информацию из устройства ввода/вывода и записывать ее в память. При этом на шине адреса выставляется адрес памяти, а адрес устройства ввода/вывода заменяется одним- единственным сигналом AEN. Естественно, в цикле обмена в режиме ПДП участвует только то устройство ввода/вывода, которое предварительно запросило ПДП и которому ПДП было предоставлено. Поэтому никаких конфликтов между устройствами ввода/вывода из-за такой упрощенной адресации не возникает.

Рис. 2.12. Структура связей запроса/предоставления ПДП на магистрали ISA.

Рис. 2.13. Цикл ПДП на магистрали ISA.
Лекция 49
Функции устройств магистрали. Функции процессора
Рассмотрим теперь, как взаимодействуют на магистрали основные устройства микропроцессорной системы: процессор, память (оперативная и постоянная), устройства ввода/вывода.
Функции процессора
Процессор (рис. 2.16) обычно представляет собой отдельную микросхему или же часть микросхемы (в случае микроконтроллера). В прежние годы процессор иногда выполнялся на комплектах из нескольких микросхем, но сейчас от такого подхода уже практически отказались. Микросхема процессора обязательно имеет выводы трех шин: шины адреса, шины данных и шины управления. Иногда некоторые сигналы и шины мультиплексируются, чтобы уменьшить количество выводов микросхемы процессора.
Важнейшие характеристики процессора — это количество разрядов его шины данных, количество разрядов его шины адреса и количество управляющих сигналов в шине управления. Разрядность шины данных определяет скорость работы системы. Разрядность шины адреса определяет допустимую сложность системы. Количество линий управления определяет разнообразие режимов обмена и эффективность обмена процессора с другими устройствами системы.
Кроме выводов для сигналов трех основных шин процессор всегда имеет вывод (или два вывода) для подключения внешнего тактового сигнала или кварцевого резонатора (CLK), так как процессор всегда представляет собой тактируемое устройство. Чем больше тактовая частота процессора, тем он быстрее работает, то есть тем быстрее выполняет команды. Впрочем, быстродействие процессора определяется не только тактовой частотой, но и особенностями его структуры. Современные процессоры выполняют большинство команд за один такт и имеют средства для параллельного выполнения нескольких команд. Тактовая частота процессора не связана прямо и жестко со скоростью обмена по магистрали, так как скорость обмена по магистрали ограничена задержками распространения сигналов и искажениями сигналов на магистрали. То есть тактовая частота процессора определяет только его внутреннее быстродействие, а не внешнее. Иногда тактовая частота процессора имеет нижний и верхний пределы. При превышении верхнего предела частоты возможно перегревание процессора, а также сбои, причем, что самое неприятное, возникающие не всегда и нерегулярно. Так что с изменением этой частоты надо быть очень осторожным.

Рис. 2.16. Схема включения процессора.
Еще один важный сигнал, который имеется в каждом процессоре, — это сигнал начального сброса RESET. При включении питания, при аварийной ситуации или зависании процессора подача этого сигнала приводит к инициализации процессора, заставляет его приступить к выполнению программы начального запуска. Аварийная ситуация может быть вызвана помехами по цепям питания и «земли», сбоями в работе памяти, внешними ионизирующими излучениями и еще множеством причин. В результате процессор может потерять контроль над выполняемой программой и остановиться в каком-то адресе. Для выхода из этого состояния как раз и используется сигнал начального сброса. Этот же вход начального сброса может использоваться для оповещения процессора о том, что напряжение питания стало ниже установленного предела. В таком случае процессор переходит к выполнению программы сохранения важных данных. По сути, этот вход представляет собой особую разновидность радиального прерывания.
Иногда у микросхемы процессора имеется еще один - два входа радиальных прерываний для обработки особых ситуаций (например, для прерывания от внешнего таймера).
Шина питания современного процессора обычно имеет одно напряжение питания (+5В или +3,3В) и общий провод («землю»). Первые процессоры нередко требовали нескольких напряжений питания. В некоторых процессорах предусмотрен режим пониженного энергопотребления. Вообще, современные микросхемы процессоров, особенно с высокими тактовыми частотами, потребляют довольно большую мощность. В результате для поддержания нормальной рабочей температуры корпуса на них нередко приходится устанавливать радиаторы, вентиляторы или даже специальные микрохолодильники.
Для подключения процессора к магистрали используются буферные микросхемы, обеспечивающие, если необходимо, демультиплексирование сигналов и электрическое буферирование сигналов магистрали. Иногда протоколы обмена по системной магистрали и по шинам процессора не совпадают между собой, тогда буферные микросхемы еще и согласуют эти протоколы друг с другом. Иногда в микропроцессорной системе используется несколько магистралей (системных и локальных), тогда для каждой из магистралей применяется свой буферный узел. Такая структура характерна, например, для персональных компьютеров.
После включения питания процессор переходит в первый адрес программы начального пуска и выполняет эту программу. Данная программа предварительно записана в постоянную (энергонезависимую) память. После завершения программы начального пуска процессор начинает выполнять основную программу, находящуюся в постоянной или оперативной памяти, для чего выбирает по очереди все команды. От этой программы процессор могут отвлекать внешние прерывания или запросы на ПДП. Команды из памяти процессор выбирает с помощью циклов чтения по магистрали. При необходимости процессор записывает данные в память или в устройства ввода/вывода с помощью циклов записи или же читает данные из памяти или из устройств ввода/вывода с помощью циклов чтения.
Таким образом, основные функции любого процессора следующие:
· выборка (чтение) выполняемых команд;
· ввод (чтение) данных из памяти или устройства ввода/вывода;
· вывод (запись) данных в память или в устройства ввода/вывода;
· обработка данных (операндов), в том числе арифметические операции над ними;
· адресация памяти, то есть задание адреса памяти, с которым будет производиться обмен;
· обработка прерываний и режима прямого доступа.
Упрощенно структуру микропроцессора можно представить в следующем виде (рис. 2.17).
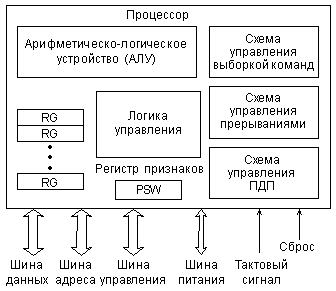
Рис. 2.17. Внутренняя структура микропроцессора.
Основные функции показанных узлов следующие.
Схема управления выборкой команд выполняет чтение команд из памяти и их дешифрацию. В первых микропроцессорах было невозможно одновременное выполнение предыдущей команды и выборка следующей команды, так как процессор не мог совмещать эти операции. Но уже в 16-разрядных процессорах появляется так называемый конвейер (очередь) команд, позволяющий выбирать несколько следующих команд, пока выполняется предыдущая. Два процесса идут параллельно, что ускоряет работу процессора. Конвейер представляет собой небольшую внутреннюю память процессора, в которую при малейшей возможности (при освобождении внешней шины) записывается несколько команд, следующих за исполняемой. Читаются эти команды процессором в том же порядке, что и записываются в конвейер (это память типа FIFO, First In — First Out, первый вошел — первый вышел). Правда, если выполняемая команда предполагает переход не на следующую ячейку памяти, а на удаленную (с меньшим или большим адресом), конвейер не помогает, и его приходится сбрасывать. Но такие команды встречаются в программах сравнительно редко.
Развитием идеи конвейера стало использование внутренней кэш-памяти процессора, которая заполняется командами, пока процессор занят выполнением предыдущих команд. Чем больше объем кэш-памяти, тем меньше вероятность того, что ее содержимое придется сбросить при команде перехода. Понятно, что обрабатывать команды, находящиеся во внутренней памяти, процессор может гораздо быстрее, чем те, которые расположены во внешней памяти. В кэш-памяти могут храниться и данные, которые обрабатываются в данный момент, это также ускоряет работу. Для большего ускорения выборки команд в современных процессорах применяют совмещение выборки и дешифрации, одновременную дешифрацию нескольких команд, несколько параллельных конвейеров команд, предсказание команд переходов и некоторые другие методы.
Арифметико-логическое устройство (или АЛУ, ALU) предназначено для обработки информации в соответствии с полученной процессором командой. Примерами обработки могут служить логические операции (типа логического «И», «ИЛИ», «Исключающего ИЛИ» и т.д.) то есть побитные операции над операндами, а также арифметические операции (типа сложения, вычитания, умножения, деления и т.д.). Над какими кодами производится операция, куда помещается ее результат — определяется выполняемой командой. Если команда сводится всего лишь к пересылке данных без их обработки, то АЛУ не участвует в ее выполнении.
Быстродействие АЛУ во многом определяет производительность процессора. Причем важна не только частота тактового сигнала, которым тактируется АЛУ, но и количество тактов, необходимое для выполнения той или иной команды. Для повышения производительности разработчики стремятся довести время выполнения команды до одного такта, а также обеспечить работу АЛУ на возможно более высокой частоте. Один из путей решения этой задачи состоит в уменьшении количества выполняемых АЛУ команд, создание процессоров с уменьшенным набором команд (так называемые RISC-процессоры). Другой путь повышения производительности процессора — использование нескольких параллельно работающих АЛУ.
Что касается операций над числами с плавающей точкой и других специальных сложных операций, то в системах на базе первых процессоров их реализовали последовательностью более простых команд, специальными подпрограммами, однако затем были разработаны специальные вычислители — математические сопроцессоры, которые заменяли основной процессор на время выполнения таких команд. В современных микропроцессорах математические сопроцессоры входят в структуру как составная часть.
Регистры процессора представляют собой по сути ячейки очень быстрой памяти и служат для временного хранения различных кодов: данных, адресов, служебных кодов. Операции с этими кодами выполняются предельно быстро, поэтому, в общем случае, чем больше внутренних регистров, тем лучше. Кроме того, на быстродействие процессора сильно влияет разрядность регистров. Именно разрядность регистров и АЛУ называется внутренней разрядностью процессора, которая может не совпадать с внешней разрядностью.
По отношению к назначению внутренних регистров существует два основных подхода. Первого придерживается, например, компания Intel, которая каждому регистру отводит строго определенную функцию. С одной стороны, это упрощает организацию процессора и уменьшает время выполнения команды, но с другой — снижает гибкость, а иногда и замедляет работу программы. Например, некоторые арифметические операции и обмен с устройствами ввода/вывода проводятся только через один регистр — аккумулятор, в результате чего при выполнении некоторых процедур может потребоваться несколько дополнительных пересылок между регистрами. Второй подход состоит в том, чтобы все (или почти все) регистры сделать равноправными, как, например, в 16-разрядных процессорах Т-11 фирмы DEC. При этом достигается высокая гибкость, но необходимо усложнение структуры процессора. Существуют и промежуточные решения, в частности, в процессоре MC68000 фирмы Motorola половина регистров использовалась для данных, и они были взаимозаменяемы, а другая половина — для адресов, и они также взаимозаменяемы.
Регистр признаков (регистр состояния) занимает особое место, хотя он также является внутренним регистром процессора. Содержащаяся в нем информация — это не данные, не адрес, а слово состояния процессора (ССП, PSW — Processor Status Word). Каждый бит этого слова (флаг) содержит информацию о результате предыдущей команды. Например, есть бит нулевого результата, который устанавливается в том случае, когда результат выполнения предыдущей команды — нуль, и очищается в том случае, когда результат выполнения команды отличен от нуля. Эти биты (флаги) используются командами условных переходов, например, командой перехода в случае нулевого результата. В этом же регистре иногда содержатся флаги управления, определяющие режим выполнения некоторых команд.
Схема управления прерываниями обрабатывает поступающий на процессор запрос прерывания, определяет адрес начала программы обработки прерывания (адрес вектора прерывания), обеспечивает переход к этой программе после выполнения текущей команды и сохранения в памяти (в стеке) текущего состояния регистров процессора. По окончании программы обработки прерывания процессор возвращается к прерванной программе с восстановленными из памяти (из стека) значениями внутренних регистров. Подробнее о стеке будет рассказано в следующем разделе.
Схема управления прямым доступом к памяти служит для временного отключения процессора от внешних шин и приостановки работы процессора на время предоставления прямого доступа запросившему его устройству.
Логика управления организует взаимодействие всех узлов процессора, перенаправляет данные, синхронизирует работу процессора с внешними сигналами, а также реализует процедуры ввода и вывода информации.
Таким образом, в ходе работы процессора схема выборки команд выбирает последовательно команды из памяти, затем эти команды выполняются, причем в случае необходимости обработки данных подключается АЛУ. На входы АЛУ могут подаваться обрабатываемые данные из памяти или из внутренних регистров. Во внутренних регистрах хранятся также коды адресов обрабатываемых данных, расположенных в памяти. Результат обработки в АЛУ изменяет состояние регистра признаков и записывается во внутренний регистр или в память (как источник, так и приемник данных указывается в составе кода команды). При необходимости информация может переписываться из памяти (или из устройства ввода/вывода) во внутренний регистр или из внутреннего регистра в память (или в устройство ввода/вывода).
Внутренние регистры любого микропроцессора обязательно выполняют две служебные функции:
· определяют адрес в памяти, где находится выполняемая в данный момент команда (функция счетчика команд или указателя команд);
· определяют текущий адрес стека (функция указателя стека).
В разных процессорах для каждой из этих функций может отводиться один или два внутренних регистра. Эти два указателя отличаются от других не только своим специфическим, служебным, системным назначением, но и особым способом изменения содержимого. Их содержимое программы могут менять только в случае крайней необходимости, так как любая ошибка при этом грозит нарушением работы компьютера, зависанием и порчей содержимого памяти.
Содержимое указателя (счетчика) команд изменяется следующим образом. В начале работы системы (при включении питания) в него заносится раз и навсегда установленное значение. Это первый адрес программы начального запуска. Затем после выборки из памяти каждой следующей команды значение указателя команд автоматически увеличивается (инкрементируется) на единицу (или на два в зависимости от формата команд и типа процессора). То есть следующая команда будет выбираться из следующего по порядку адреса памяти. При выполнении команд перехода, нарушающих последовательный перебор адресов памяти, в указатель команд принудительно записывается новое значение — новый адрес в памяти, начиная с которого адреса команд опять же будут перебираться последовательно. Такая же смена содержимого указателя команд производится при вызове подпрограммы и возврате из нее или при начале обработки прерывания и после его окончания.
О стеке будет подробнее рассказано в следующем разделе.
Лекция 50
Функции устройств магистрали. Функции памяти
Память микропроцессорной системы выполняет функцию временного или постоянного хранения данных и команд. Объем памяти определяет допустимую сложность выполняемых системой алгоритмов, а также в некоторой степени и скорость работы системы в целом. Модули памяти выполняются на микросхемах памяти (оперативной или постоянной). Все чаще в составе микропроцессорных систем используется флэш-память (англ. — flash memory), которая представляет собой энергонезависимую память с возможностью многократной перезаписи содержимого.
Информация в памяти хранится в ячейках, количество разрядов которых равно количеству разрядов шины данных процессора. Обычно оно кратно восьми (например, 8, 16, 32, 64). Допустимое количество ячеек памяти определяется количеством разрядов шины адреса как 2N, где N — количество разрядов шины адреса. Чаще всего объем памяти измеряется в байтах независимо от разрядности ячейки памяти. Используются также следующие более крупные единицы объема памяти: килобайт — 210 или 1024 байта (обозначается Кбайт), мегабайт — 220 или 1 048 576 байт (обозначается Мбайт), гигабайт — 230 байт (обозначается Гбайт), терабайт — 240 (обозначается Тбайт) Например, если память имеет 65 536 ячеек, каждая из которых 16-разрядная, то говорят, что память имеет объем 128 Кбайт. Совокупность ячеек памяти называется обычно пространством памяти системы.
Для подключения модуля памяти к системной магистрали используются блоки сопряжения, которые включают в себя дешифратор (селектор) адреса, схему обработки управляющих сигналов магистрали и буферы данных (рис. 2.18).
Оперативная память общается с системной магистралью в циклах чтения и записи, постоянная память — только в циклах чтения. Обычно в составе системы имеется несколько модулей памяти, каждый из которых работает в своей области пространства памяти. Селектор адреса как раз и определяет, какая область адресов пространства памяти отведена данному модулю памяти. Схема управления вырабатывает в нужные моменты сигналы разрешения работы памяти (CS) и сигналы разрешения записи в память (WR). Буферы данных передают данные от памяти к магистрали или от магистрали к памяти.
В пространстве памяти микропроцессорной системы обычно выделяются несколько особых областей, которые выполняют специальные функции.
Память программы начального запуска всегда выполняется на ПЗУ или флэш-памяти. Именно с этой области процессор начинает работу после включения питания и после сброса его с помощью сигнала RESET.

Рис. 2.18. Структура модуля памяти.
Память для стека или стек (Stack) — это часть оперативной памяти, предназначенная для временного хранения данных в режиме LIFO (Last In — First Out).
Особенность стека по сравнению с другой оперативной памятью — это заданный и неизменяемый способ адресации. При записи любого числа (кода) в стек число записывается по адресу, определяемому как содержимое регистра указателя стека, предварительно уменьшенное (декрементированное) на единицу (или на два, если 16-разрядные слова расположены в памяти по четным адресам). При чтении из стека число читается из адреса, определяемого содержимым указателя стека, после чего это содержимое указателя стека увеличивается (инкрементируется) на единицу (или на два). В результате получается, что число, записанное последним, будет прочитано первым, а число, записанное первым, будет прочитано последним. Такая память называется LIFO или памятью магазинного типа (например, в магазине автомата патрон, установленный последним, будет извлечен первым).
Принцип действия стека показан на рис. 2.19 (адреса ячеек памяти выбраны условно).
Пусть, например, текущее состояние указателя стека 1000008, и в него надо записать два числа (слова). Первое слово будет записано по адресу 1000006 (перед записью указатель стека уменьшится на два). Второе — по адресу 1000004. После записи содержимое указателя стека — 1000004. Если затем прочитать из стека два слова, то первым будет прочитано слово из адреса 1000004, а после чтения указатель стека станет равным 1000006. Вторым будет прочитано слово из адреса 1000006, а указатель стека станет равным 1000008. Все вернулось к исходному состоянию. Первое записанное слово читается вторым, а второе — первым.

Рис. 2.19. Принцип работы стека.
Необходимость такой адресации становится очевидной в случае многократно вложенных подпрограмм. Пусть, например, выполняется основная программа, и из нее вызывается подпрограмма 1. Если нам надо сохранить значения данных и внутренних регистров основной программы на время выполнения подпрограммы, мы перед вызовом подпрограммы сохраним их в стеке (запишем в стек), а после ее окончания извлечем (прочитаем) их из стека. Если же из подпрограммы 1 вызывается подпрограмма 2, то ту же самую операцию мы проделаем с данными и содержимым внутренних регистров подпрограммы 1. Понятно, что внутри подпрограммы 2 крайними в стеке (читаемыми в первую очередь) будут данные из подпрограммы 1, а данные из основной программы будут глубже. При этом в случае чтения из стека автоматически будет соблюдаться нужный порядок читаемой информации. То же самое будет и в случае, когда таких уровней вложения подпрограмм гораздо больше. То есть то, что надо хранить подольше, прячется поглубже, а то, что скоро может потребоваться — с краю.
В системе команд любого процессора для обмена информацией со стеком предусмотрены специальные команды записи в стек (PUSH) и чтения из стека (POP). В стеке можно прятать не только содержимое всех внутренних регистров процессоров, но и содержимое регистра признаков (слово состояния процессора, PSW). Это позволяет, например, при возвращении из подпрограммы контролировать результат последней команды, выполненной непосредственно перед вызовом этой подпрограммы. Можно также хранить в стеке и данные, для того чтобы удобнее было передавать их между программами и подпрограммами. В общем случае, чем больше область памяти, отведенная под стек, тем больше свободы у программиста и тем более сложные программы могут выполняться.
Следующая специальная область памяти — это таблица векторов прерываний.
Вообще, понятие прерывания довольно многозначно. Под прерыванием в общем случае понимается не только обслуживание запроса внешнего устройства, но и любое нарушение последовательной работы процессора. Например, может быть предусмотрено прерывание по факту некорректного выполнения арифметической операции типа деления на ноль. Или же прерывание может быть программным, когда в программе используется команда перехода на какую-то подпрограмму, из которой затем последует возврат в основную программу. В последнем случае общее с истинным прерыванием только то, как осуществляется переход на подпрограмму и возврат из нее.
Любое прерывание обрабатывается через таблицу векторов (указателей) прерываний. В этой таблице в простейшем случае находятся адреса начала программ обработки прерываний, которые и называются векторами. Длина таблицы может быть довольно большой (до нескольких сот элементов). Обычно таблица векторов прерываний располагается в начале пространства памяти (в ячейках памяти с малыми адресами). Адрес каждого вектора (или адрес начального элемента каждого вектора) представляет собой номер прерывания.
В случае аппаратных прерываний номер прерывания или задается устройством, запросившим прерывание (при векторных прерываниях), или же задается номером линии запроса прерываний (при радиальных прерываниях). Процессор, получив аппаратное прерывание, заканчивает выполнение текущей команды и обращается к памяти в область таблицы векторов прерываний, в ту ее строку, которая определяется номером запрошенного прерывания. Затем процессор читает содержимое этой строки (код вектора прерывания) и переходит в адрес памяти, задаваемый этим вектором. Начиная с этого адреса в памяти должна располагаться программа обработки прерывания с данным номером. В конце программы обработки прерываний обязательно должна располагаться команда выхода из прерывания, выполнив которую, процессор возвращается к выполнению прерванной основной программы. Параметры процессора на время выполнения программы обработки прерывания сохраняются в стеке.
Пусть, например, процессор (рис.2.20) выполнял основную программу и команду, находящуюся в адресе памяти 5000 (условно). В этот момент он получил запрос прерывания с номером (адресом вектора) 4. Процессор заканчивает выполнение команды из адреса 5000. Затем он сохраняет в стеке текущее значение счетчика команд (5001) и текущее значение PSW. После этого процессор читает из адреса 4 памяти код вектора прерывания. Пусть этот код равен 6000. Процессор переходит в адрес памяти 6000 и приступает к выполнению программы обработки прерывания, начинающейся с этого адреса. Пусть эта программа заканчивается в адресе 6100. Дойдя до этого адреса, процессор возвращается к выполнению прерванной программы. Для этого он извлекает из стека значение адреса (5001), на котором его прервали, и бывшее в тот момент PSW. Затем процессор читает команду из адреса 5001 и дальше последовательно выполняет команды основной программы.

Рис. 2.20. Упрощенный алгоритм обработки прерывания.
Прерывание в случае аварийной ситуации обрабатывается точно так же, только адрес вектора прерывания (номер строки в таблице векторов) жестко привязан к данному типу аварийной ситуации.
Программное прерывание тоже обслуживается через таблицу векторов прерываний, но номер прерывания указывается в составе команды, вызывающей прерывание.
Такая сложная, на первый взгляд, организация прерываний позволяет программисту легко менять программы обработки прерываний, располагать их в любой области памяти, делать их любого размера и любой сложности.
Во время выполнения программы обработки прерывания может поступить новый запрос на прерывание. В этом случае он обрабатывается точно так же, как описано, но основной программой считается прерванная программа обработки предыдущего прерывания. Это называется многократным вложением прерываний. Механизм стека позволяет без проблем обслуживать это многократное вложение, так как первым из стека извлекается тот код, который был сохранен последним, то есть возврат из обработки данного прерывания происходит в программу обработки предыдущего прерывания.
Отметим, что в более сложных случаях в таблице векторов прерываний могут находиться не адреса начала программ обработки прерываний, а так называемые дескрипторы (описатели) прерываний. Но конечным результатом обработки этого дескриптора все равно будет адрес начала программы обработки прерываний.
Наконец, еще одна специальная область памяти микропроцессорной системы — это память устройств, подключенных к системной шине. Такое решение встречается нечасто, но иногда оно очень удобно. То есть процессор получает возможность обращаться к внутренней памяти устройств ввода/вывода или каких-то еще подключенных к системной шине устройств, как к своей собственной системной памяти. Обычно окно в пространстве памяти, выделяемое для этого, не слишком большое.
Все остальные части пространства памяти, как правило, имеют универсальное назначение. В них могут располагаться как данные, так и программы (конечно, в случае одношинной архитектуры). Иногда это пространство памяти используется как единое целое, без всяких границ. А иногда пространство памяти делится на сегменты с программно изменяемым адресом начала сегмента и с установленным размером сегмента. Оба подхода имеют свои плюсы и минусы. Например, использование сегментов позволяет защитить область программ или данных, но зато границы сегментов могут затруднять размещение больших программ и массивов данных.
В заключение остановимся на проблеме разделения адресов памяти и адресов устройств ввода/вывода. Существует два основных подхода к решению этой проблемы:
· выделение в общем адресном пространстве системы специальной области адресов для устройств ввода/вывода;
· полное разделение адресных пространств памяти и устройств ввода/вывода.
Первый подход хорош тем, что при обращении к устройствам ввода/вывода процессор может использовать те же команды, которые служат для взаимодействия с памятью. Но адресное пространство памяти должно быть уменьшено на величину адресного пространства устройств ввода/вывода. Например, при 16-разрядной шине адреса всего может быть 64К адресов. Из них 56К адресов отводится под адресное пространство памяти, а 8К адресов — под адресное пространство устройств ввода/вывода.
Преимущество второго подхода состоит в том, что память занимает все адресное пространство микропроцессорной системы. Для общения с устройствами ввода/вывода применяются специальные команды и специальные стробы обмена на магистрали. Именно так сделано, например, в персональных компьютерах. Но возможности взаимодействия с устройствами ввода/вывода в данном случае существенно ограничены по сравнению с возможностями общения с памятью.
Лекция 51
Функции устройств магистрали. Функции устройств ввода/вывода
Устройства ввода/вывода обмениваются информацией с магистралью по тем же принципам, что и память. Наиболее существенное отличие с точки зрения организации обмена состоит в том, что модуль памяти имеет в адресном пространстве системы много адресов (до нескольких десятков миллионов), а устройство ввода/вывода обычно имеет немного адресов (обычно до десяти), а иногда и всего один адрес.
Но модули памяти системы обмениваются информацией только с магистралью, с процессором, а устройства ввода/вывода взаимодействуют еще и с внешними устройствами, цифровыми или аналоговыми. Поэтому разнообразие устройств ввода/вывода неизмеримо больше, чем модулей памяти. Часто используются еще и другие названия для устройств ввода/вывода: устройства сопряжения, контроллеры, карты расширения, интерфейсные модули и т.д.
Объединяют все устройства ввода/вывода общие принципы обмена с магистралью и, соответственно, общие принципы организации узлов, которые осуществляют сопряжение с магистралью. Упрощенная структура устройства ввода/вывода (точнее, его интерфейсной части) приведена на рис. 2.21. Как и в случае модуля памяти, она обязательно содержит схему селектора адреса, схему управления для обработки стробов обмена и буферы данных.
Самые простейшие устройства ввода/вывода выдают на внешнее устройство код данных в параллельном формате и принимают из внешнего устройства код данных в параллельном формате. Такие устройства ввода/вывода часто называют параллельными портами ввода/вывода. Они наиболее универсальны, то есть удовлетворяют потребности сопряжения с большим числом внешних устройств, поэтому их часто вводят в состав микропроцессорной системы в качестве стандартных устройств. Параллельные порты обычно имеются в составе микроконтроллеров. Именно через параллельные порты микроконтроллер связывается с внешним миром.
Входной порт (порт ввода) в простейшем случае представляет собой параллельный регистр, в который процессор может записывать информацию. Выходной порт (порт вывода) обычно представляет собой просто однонаправленный буфер, через который процессор может читать информацию от внешнего устройства. Именно такие порты показаны для примера на рис. 2.21. Порт может быть и двунаправленным (входным/выходным). В этом случае процессор пишет информацию во внешнее устройство и читает информацию из внешнего устройства по одному и тому же адресу в адресном пространстве системы. Входные и выходные линии для связи с внешним устройством при этом могут быть объединены поразрядно, образуя двунаправленные линии.

Рис. 2.21. Структура простейшего устройства ввода/вывода.
При обращении со стороны магистрали селектор адреса распознает адрес, приписанный данному устройству ввода/вывода. Схема управления выдает внутренние стробы обмена в ответ на магистральные стробы обмена. Входной буфер данных обеспечивает электрическое согласование шины данных с этим устройством (буфер может и отсутствовать). Данные из шины данных записываются в регистр по сигналу С и выдаются на внешнее устройство. Выходной буфер данных передает входные данные с внешнего устройства на шину данных магистрали в цикле чтения из порта.
Более сложные устройства ввода/вывода (устройства сопряжения) имеют в своем составе внутреннюю буферную оперативную память и даже могут иметь микроконтроллер, на который возложено выполнение функций обмена с внешним устройством.
Каждому устройству ввода/вывода отводится свой адрес в адресном пространстве микропроцессорной системы. Дублирование адресов должно быть исключено, за этим должны следить разработчик и пользователь микропроцессорной системы.
Устройства ввода/вывода помимо программного обмена могут также поддерживать режим обмена по прерываниям. В этом случае они преобразуют поступающий от внешнего устройства сигнал запроса на прерывание в сигнал запроса прерывания, необходимый для данной магистрали (или в последовательность сигналов при векторном прерывании). Если нужно использовать режим ПДП, устройство ввода/вывода должно выдать сигнал запроса ПДП на магистраль и обеспечить работу в циклах ПДП, принятых для данной магистрали.
В составе микропроцессорных систем, как правило, выделяются три специальные группы устройств ввода/вывода:
· устройства интерфейса пользователя (ввода информации пользователем и вывода информации для пользователя);
· устройства ввода/вывода для длительного хранения информации;
· таймерные устройства.
К устройствам ввода для интерфейса пользователя относятся контроллеры клавиатуры, тумблеров, отдельных кнопок, мыши, трекбола, джойстика и т.д. К устройствам вывода для интерфейса пользователя относятся контроллеры светодиодных индикаторов, табло, жидкокристаллических, плазменных и электронно-лучевых экранов и т.д. В простейших случаях управляющих контроллеров или микроконтроллеров эти средства могут отсутствовать. В сложных микропроцессорных системах они есть обязательно. Роль внешнего устройства в данном случае играет человек.
Устройства ввода/вывода для длительного хранения информации обеспечивают сопряжение микропроцессорной системы с дисководами (компакт-дисков или магнитных дисков), а также с накопителями на магнитной ленте. Применение таких устройств существенно увеличивает возможности микропроцессорной системы в отношении хранения выполняемых программ и накопления массивов данных. В простейших контроллерах эти устройства отсутствуют.
Таймерные устройства отличаются от других устройств ввода/вывода тем, что они могут не иметь внешних выводов для подключения к внешним устройствам. Эти устройства предназначены для того, чтобы микропроцессорная система могла выдерживать заданные временные интервалы, следить за реальным временем, считать импульсы и т.д. В основе любого таймера лежит кварцевый тактовый генератор и многоразрядные двоичные счетчики, которые могут перезапускать друг друга. Процессор может записывать в таймер коэффициенты деления тактовой частоты, количество отсчитываемых импульсов, задавать режим работы счетчиков таймера, а читает процессор выходные коды счетчиков. В принципе выполнить практически все функции таймера можно и программным путем, поэтому иногда таймеры в системе отсутствуют. Но включение в систему таймера позволяет решать более сло
Date: 2016-07-18; view: 669; Нарушение авторских прав; Помощь в написании работы --> СЮДА... |