Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Построение хранилища данных
Анализ
Располагая каталогом требований, можно приступить к реализации этапа анализа —получения согласованных по источникам логической модели и определения набора инструментальных средств для работы с ХД. Стадии этого этапа показаны на рис. 3.3.

Рис. 3.3. Этап анализа
Цель первой стадии этого этапа состоит в разработке логической модели данных для ХД и киосков данных. Кроме создания логической модели, необходимо фиксировать модели логической структуры баз данных подающих систем.
На следующей стадии определяются процессы, которые необходимы для связи источников данных и ХД, процедур очистки, преобразования и агрегации данных источников, производится выбор инструментальных средств для загрузки данных в ХД и выбор инструментальных средств конечного пользователя, которые должны быть размещены на клиентских компьютерах.
Проектирование
После завершения стадии анализа переходят к реализации стадии проектирования (рис. 3.4). Цель этого этапа — разработка физической модели ХД, проектирование процедур поступления данных в него и проектирование архитектуры приложений.
Проектирование ХД можно разложить на две равноценных стадии – проектирование архитектуры данных (логическое и физическое проектирование) и архитектуры приложений (анализ запросов и фиксация процессов взаимодействия хранилища данных с внешними источниками и пользователями).
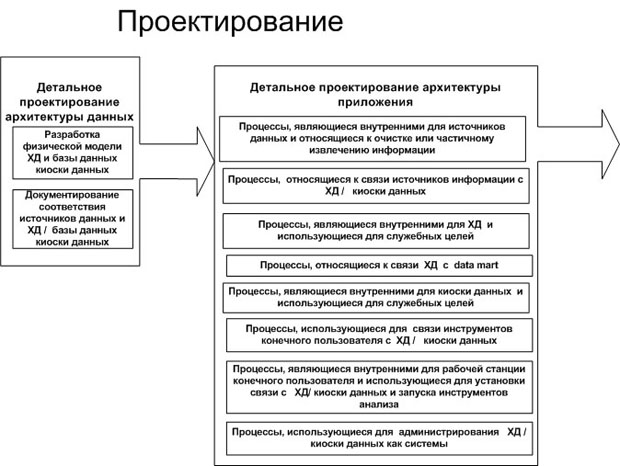
Рис. 3.4. Этап проектирования хранилища данных
Детальное проектирование архитектуры данных включает в себя:
· логическое проектирование. Разработка логических моделей данных для ХД и киосков данных в рабочем пространстве базы данных. Отображение логических моделей данных источников данных в логические модели ХД и киосков данных;
· физическое проектирование. Отображение логических объектов в физическое описание ХД. Денормализация логической модели. Создание табличного пространства, секционирование, создание индексов и ограничений. Оценка объема физического ввода-вывода.
На стадии логического проектирования рассматриваются логические взаимоотношения между объектами предметной области. Особенностью логического проектирования ХД является тотальная ориентация на потребности и задачи конечного пользователя — бизнес-аналитиков и руководителей организации различных уровней. Они будут анализировать данные и работать с агрегированными данными, а не с данными конкретной бизнес-операции. Этот класс пользователей, как правило, обычно не знает точно, что им все-таки нужно от данных. И здесь важно оценить уровень претензий к данным и очертить круг задач, которые могут возникнуть.
В процессе логического проектирования выделяется набор объектов предметной области с их атрибутами. Объект представляет собой фрагмент информации о предметной области. В реляционных базах данных объект отображается в таблицу, а его атрибуты отображаются в колонки такой таблицы. В логическом проектировании ХД для создания ER-диаграмм используется многомерное моделирование, которое, грубо говоря, сводится к идентификации информации об объекте в виде фактов (таблицы фактов) и идентификации информации, с помощью которой на эти факты можно посмотреть (таблицы измерений). Результатом стадии логического проектирования является логическая схема ХД и, возможно, отображение логической схемы источников данных (подающих систем) на логическую схему ХД.
На стадии физического проектирования рассматриваются задачи размещения данных в БД для эффективной их выборки. На этой стадии (для реляционных хранилищ данных) реально пишутся SQL-операторы. Данные, собранные на стадии логического проектирования, превращаются в описание физической БД, включая таблицы, уникальные идентификаторы объектов – в первичные ключи, ограничения по значениям данных, взаимоотношения между объектами – во внешние ключи, индексы, табличные пространства, разбиения и представления.
Назначение табличного пространства состоит в отделении таблиц от их индексов, маленьких таблиц от больших таблиц, т.е. является механизмом для решения задачи оптимального размещения данных (некоторые СУБД решают эту задачу сами, без вмешательства пользователя).
Секционирование больших таблиц необходимо для увеличения производительности обработки запросов, т.е. является одним из механизмов решения задачи оптимизации выборки, так же, как и создание индексов.
Ограничения в ХД отличаются от ограничений в OLTP-системах. В системах складирования данных целостность и проверка данных обеспечивается на стадии загрузки данных. Поэтому роль ограничений в ХД не столь уж велика. Типичным ограничением в ХД является ограничение NOT NULL.
Параллельно с проектированием архитектуры данных начинается стадия детального проектирования структуры приложений, которая включает в себя определение:
· процессов, которые являются внутренними для источников данных и связаны с процедурами очистки и частичной экстракции информации;
· процессов, которые связывают источники данных с ХД и киосками данных;
· процессов, которые являются внутренними по отношению к ХД и предназначены исключительно для обслуживания данных в хранилище;
· процессов, которые связывают ХД и киоски данных;
· процессов, которые являются внутренними по отношению к киоскам данных и предназначены исключительно для обслуживания данных в них;
· процессов, которые связывают хранилище и киоски данных со средствами конечного пользователя;
· процессов, которые являются внутренними на рабочих станциях конечных пользователей и используются для установки связи с ХД и запуском средств анализа;
· процессов для поддержки управления и администрирования внутренних задач ХД как системы.
Целью этой стадии является получение спецификаций всех приложений ХД.
Все результаты стадии проектирования тщательно документируются, поскольку являются исходными и рабочими документами команды проекта и постоянно используются в ходе дальнейшей работы над проектом.
Построение хранилища данных
Следующий этап проекта создания ХД — это построение ХД (рис. 3.5).

Рис. 3.5. Построение хранилища данных
Цель этого этапа состоит в разработке программ и собственно физической БД под ХД. Выполнение этого этапа проекта, помимо создания собственно ХД, включает в себя разработку и отладку приложений ХД, а именно следующих групп программ:
· программы, которые создают и модифицируют БД для ХД и киосков данных;
· программы, которые экстрагируют данные из источников данных;
· программы, которые выполняют преобразования данных, такие как интеграция, суммирование и агрегация;
· программы, которые выполняют обновление реляционных БД;
· программы, которые реализуют поиск в очень больших БД.
Результатом выполнения этого этапа является комплекс программ, работающих с ХД.
Внедрение
Следующим этапом реализации проекта создание является внедрение в опытную эксплуатацию (рис. 3.6). Это очень ответственный и трудоемкий этап. Начинается он со стадии начальной инсталляции, включающей начальную загрузку хранилища из источников данных, и тестирования процедур обновления и синхронизации данных.

Рис. 3.6. Этап внедрения хранилища данных
Далее составляются и утверждаются планы постадийного тестирования, тренировки и обучения персонала для всех классов пользователей, реализации обновления несущих платформ для ХД, информационных потребностей и т. д.
Выполняется обеспечение администрирования системы и данных о пользователях, возможностей архивирования и резервного копирования, возможностей восстановления, управления доступом и безопасностью, полных возможностей и процесса управления системой и ее структурными компонентами, информационного каталога/директории. Проводится целостная интеграция хранилища данных в существующую инфраструктуру организации.
Результатом выполнения этого этапа является всесторонняя подготовка перехода ХД в промышленную эксплуатацию.
Поддержка
Этап поддержки ХД в работоспособном состоянии, как уже отмечалось выше, является самостоятельным проектом. Это последний этап жизненного цикла ХД. По его завершении происходит либо уничтожение ХД как продукта, либо его реинжениринг. Это связано с быстрыми изменениями сферы бизнеса организации, которые приводят к необходимости пересмотра стратегических и тактических планов организации. ХД, так же, как и другие элементы инфраструктуры организации, должно соответствовать генеральному бизнес-плану организации. В зависимости от структуры генерального бизнес-плана организации, эксплуатирующей ХД, продолжительность этого этапа может составлять два-четыре года, реже пять и более лет.
На этом этапе ИТ-служба организации обеспечивает:
· поддержку работоспособности и масштабируемости программно-аппаратного обеспечения ХД;
· сбор, очистку, преобразование, загрузку и актуализацию данных в соответствии с установленными бизнес-процедурами;
· поддержку автоматизированных мест пользователей.
Этот этап может также включать в себя техническую поддержку со стороны разработчика ХД, в частности консультирование, обучение пользователей или абонентское обслуживание.
Этот этап является также испытанием ХД "на прочность". Конечные пользователи, как правило, не являются ИТ-профессионалами. Они решают свои задачи. Они будут использовать ХД только в том случае, если оно будет эффективно помогать им решать их задачи. Поэтому ИТ-служба организации должна постоянно отслеживать активность пользователей на ХД и вести постоянный аудит мнений пользователей о полезности ХД в их профессиональной деятельности, отсекая при этом "зерна от плевел".
(Посмотреть дома в ответах к экзамену)
ETL (от англ. Extract, Transform, Load — дословно «извлечение, преобразование, загрузка») — один из основных процессов в управлении хранилищами данных, который включает в себя:
· извлечение данных из внешних источников;
· их трансформация и очистка, чтобы они соответствовали потребностям бизнес-модели;
· и загрузка их в хранилище данных.
С точки зрения процесса ETL, архитектуру хранилища данных можно представить в виде трёх компонентов:
· источник данных: содержит структурированные данные в виде таблиц, совокупности таблиц или просто файла (данные в котором разделены символами-разделителями);
· промежуточная область: содержит вспомогательные таблицы, создаваемые временно, и, исключительно для организации процесса выгрузки.
· получатель данных: хранилище данных или база данных, в которую должны быть помещены извлечённые данные.
Перемещение данных от источника к получателю называют потоком данных. Требования к организации потока данных описываются аналитиком. ETL следует рассматривать не только как процесс переноса данных из одного приложения в другое, но и как инструмент подготовки данных к анализу.
Вопрос 3
Билет 5
Вопрос 1
См ответы к экзамену по хд
Вопрос 2
Файловая система
Файловая система - это часть операционной системы, назначение которой состоит в том, чтобы обеспечить пользователю удобный интерфейс при работе с данными, хранящимися на диске, и обеспечить совместное использование файлов несколькими пользователями и процессами.
В широком смысле понятие "файловая система" включает:
· совокупность всех файлов на диске,
· наборы структур данных, используемых для управления файлами, такие, например, как каталоги файлов, дескрипторы файлов, таблицы распределения свободного и занятого пространства на диске,
· комплекс системных программных средств, реализующих управление файлами, в частности: создание, уничтожение, чтение, запись, именование, поиск и другие операции над файлами.
Имена файлов
Файлы идентифицируются именами. Пользователи дают файлам символьные имена, при этом учитываются ограничения ОС как на используемые символы, так и на длину имени. До недавнего времени эти границы были весьма узкими. Так в популярной файловой системе FAT длина имен ограничивается известной схемой 8.3 (8 символов - собственно имя, 3 символа - расширение имени), а в ОС UNIX System V имя не может содержать более 14 символов. Однако пользователю гораздо удобнее работать с длинными именами, поскольку они позволяют дать файлу действительно мнемоническое название, по которому даже через достаточно большой промежуток времени можно будет вспомнить, что содержит этот файл. Поэтому современные файловые системы, как правило, поддерживают длинные символьные имена файлов. Например, Windows NT в своей новой файловой системе NTFS устанавливает, что имя файла может содержать до 255 символов, не считая завершающего нулевого символа.
При переходе к длинным именам возникает проблема совместимости с ранее созданными приложениями, использующими короткие имена. Чтобы приложения могли обращаться к файлам в соответствии с принятыми ранее соглашениями, файловая система должна уметь предоставлять эквивалентные короткие имена (псевдонимы) файлам, имеющим длинные имена. Таким образом, одной из важных задач становится проблема генерации соответствующих коротких имен.
Длинные имена поддерживаются не только новыми файловыми системами, но и новыми версиями хорошо известных файловых систем. Например, в ОС Windows 95 используется файловая система VFAT, представляющая собой существенно измененный вариант FAT. Среди многих других усовершенствований одним из главных достоинств VFAT является поддержка длинных имен. Кроме проблемы генерации эквивалентных коротких имен, при реализации нового варианта FAT важной задачей была задача хранения длинных имен при условии, что принципиально метод хранения и структура данных на диске не должны были измениться.
Обычно разные файлы могут иметь одинаковые символьные имена. В этом случае файл однозначно идентифицируется так называемым составным именем, представляющем собой последовательность символьных имен каталогов. В некоторых системах одному и тому же файлу не может быть дано несколько разных имен, а в других такое ограничение отсутствует. В последнем случае операционная система присваивает файлу дополнительно уникальное имя, так, чтобы можно было установить взаимно-однозначное соответствие между файлом и его уникальным именем. Уникальное имя представляет собой числовой идентификатор и используется программами операционной системы. Примером такого уникального имени файла является номер индексного дескриптора в системе UNIX.
Типы файлов
Файлы бывают разных типов: обычные файлы, специальные файлы, файлы-каталоги.
Обычные файлы в свою очередь подразделяются на текстовые и двоичные. Текстовые файлы состоят из строк символов, представленных в ASCII-коде. Это могут быть документы, исходные тексты программ и т.п. Текстовые файлы можно прочитать на экране и распечатать на принтере. Двоичные файлы не используют ASCII-коды, они часто имеют сложную внутреннюю структуру, например, объектный код программы или архивный файл. Все операционные системы должны уметь распознавать хотя бы один тип файлов - их собственные исполняемые файлы.
Специальные файлы - это файлы, ассоциированные с устройствами ввода-вывода, которые позволяют пользователю выполнять операции ввода-вывода, используя обычные команды записи в файл или чтения из файла. Эти команды обрабатываются вначале программами файловой системы, а затем на некотором этапе выполнения запроса преобразуются ОС в команды управления соответствующим устройством. Специальные файлы, так же как и устройства ввода-вывода, делятся на блок-ориентированные и байт-ориентированные.
Каталог - это, с одной стороны, группа файлов, объединенных пользователем исходя из некоторых соображений (например, файлы, содержащие программы игр, или файлы, составляющие один программный пакет), а с другой стороны - это файл, содержащий системную информацию о группе файлов, его составляющих. В каталоге содержится список файлов, входящих в него, и устанавливается соответствие между файлами и их характеристиками (атрибутами).
В разных файловых системах могут использоваться в качестве атрибутов разные характеристики, например:
· информация о разрешенном доступе,
· пароль для доступа к файлу,
· владелец файла,
· создатель файла,
· признак "только для чтения",
· признак "скрытый файл",
· признак "системный файл",
· признак "архивный файл",
· признак "двоичный/символьный",
· признак "временный" (удалить после завершения процесса),
· признак блокировки,
· длина записи,
· указатель на ключевое поле в записи,
· длина ключа,
· времена создания, последнего доступа и последнего изменения,
· текущий размер файла,
· максимальный размер файла.
Каталоги могут непосредственно содержать значения характеристик файлов, как это сделано в файловой системе MS-DOS, или ссылаться на таблицы, содержащие эти характеристики, как это реализовано в ОС UNIX (рисунок 2.31). Каталоги могут образовывать иерархическую структуру за счет того, что каталог более низкого уровня может входить в каталог более высокого уровня (рисунок 2.32).

Рис. 2.31. Структура каталогов: а - структура записи каталога MS-DOS (32 байта);
б - структура записи каталога ОС UNIX
Иерархия каталогов может быть деревом или сетью. Каталоги образуют дерево, если файлу разрешено входить только в один каталог, и сеть - если файл может входить сразу в несколько каталогов. В MS-DOS каталоги образуют древовидную структуру, а в UNIX'е - сетевую. Как и любой другой файл, каталог имеет символьное имя и однозначно идентифицируется составным именем, содержащим цепочку символьных имен всех каталогов, через которые проходит путь от корня до данного каталога.

Рис. 2.32. Логическая организация файловой системы
а - одноуровневая; б - иерархическая (дерево); в - иерархическая (сеть)
Date: 2016-06-07; view: 886; Нарушение авторских прав; Помощь в написании работы --> СЮДА... |