Полезное:
Как сделать разговор полезным и приятным
Как сделать объемную звезду своими руками
Как сделать то, что делать не хочется?
Как сделать погремушку
Как сделать так чтобы женщины сами знакомились с вами
Как сделать идею коммерческой
Как сделать хорошую растяжку ног?
Как сделать наш разум здоровым?
Как сделать, чтобы люди обманывали меньше
Вопрос 4. Как сделать так, чтобы вас уважали и ценили?
Как сделать лучше себе и другим людям
Как сделать свидание интересным?

Категории:
АрхитектураАстрономияБиологияГеографияГеологияИнформатикаИскусствоИсторияКулинарияКультураМаркетингМатематикаМедицинаМенеджментОхрана трудаПравоПроизводствоПсихологияРелигияСоциологияСпортТехникаФизикаФилософияХимияЭкологияЭкономикаЭлектроника
Поисковые машины WWW
Поисковых систем сегодня существует достаточно много, международных и отечественных. AltaVista является одной из самых старых, если не старейшей, поисковой системой в Интернете - она была создана в 1995 году. В настоящее время AltaVista может осуществлять поиск на 25 языках, включая русский. Известны также зарубежные системы InfoSeek, Lycos, WebCrawler и отечественные Апорт, Rambler, Яndex. В последнее время стала расти популярность поисковой системы Google.
Если перед пользователем стоит задача найти что-либо в русскоязычной части сети, то, скорее всего, наиболее успешный результат даст поиск с использованием русскоязычных поисковиков. Прежде всего, потому, что русскоязычные поисковые сервера, в отличие от англоязычных, ведут поиск с учетом морфологии русского языка.
По данным системы статистики SpyLOG, наибольшей популярностью среди русскоязычной части пользователей Интернета пользуются системы Яndex, Rambler, Google и Апорт. Популярность поисковых машин рассчитывается по количеству переходов с них на русскоязычные сайты.
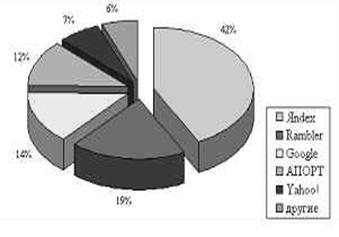
График 4. Поисковые машины: распределение переходов на русскоязычные Интернет-ресурсы
Информационно-поисковая система Rambler (www.rambler.ru) успешно работает с 1996 г. и является одной из лучших информационно-поисковых систем в России и странах СНГ. В состав Rambler входят:
· Поисковая система (www.rambler.ru) по серверам России и странам СНГ. Содержит информацию о более чем 12 миллионах документов с более чем 48000 сайтов. Система имеет развитый язык запросов и гибкую форму вывода результатов. Rambler индексирует домены ru, su, ua, by, kz, kg, ge, uz и некоторые русскоязычные ресурсы из доменов com, net, org.. В апреле 2001 года (на момент запуска обновленной версии поисковой машины) в базе данных Rambler хранилась информация о почти 8 миллионах уникальных документов. Ежедневно в базу данных этого поисковика вносится до 60 тысяч изменений и дополнений, что обеспечивает постоянное пополнение базы сведениями обо всех новинках, появляющихся в русскоязычной части Сети. Ежедневно портал Rambler посещают около 300 тыс. человек.
Rambler учитывает координаты слов, обучена строгой и нечеткой морфологии, связывает поиск с каталогом, в качестве которого используется “Top100”, группирует результаты поиска по сайтам, ищет по числам. Достаточно удачная архитектура продукта позволяет Rambler иметь для поисковика количество серверов в 2 раза меньшее, чем у "Яндекса", и в 3 раза меньшее, чем у "Апорта".
"Паук" Rambler производит индексирование в новостях 5 раз в день; в сайтах, входящих в Top100, - 1 раз в день; все прочие посещаются не чаще, чем 1 раз в две недели. Rambler не индексирует личные странички, находящиеся на публичных зарубежных серверах (geocities, tripod и других), а страницы подобных отечественных сайтов (narod, boom) обходит медленней, чем другие ресурсы.
Очень удобной функцией Rambler является "восстановить текст". Благодаря этой функции пользователь может просмотреть проиндексированную страницу даже если эта страница удалена или сервер, на котором расположена страница недоступен.
Динамические, т.е. постоянно изменяемые страницы на сайтах, страницы Rambler пока не индексирует.
· Система определения рейтинга (http://top100.rambler.ru/top100/index.shtml.ru) сайтов/страниц по посещаемости, с учетом классификации сайтов. Множество сайтов разбито на более чем 55 категорий (администрации, образование, наука, работа,...). Система обрабатывает до 3.5 миллионов счетных хитов в день, содержит более 59 тыс. ресурсов. Система ведет восемь видов рейтингов. Кроме того, для текущего дня регистрируются 5 дополнительных параметров. Обновление рейтингов - каждые 30 минут.
· Информационный и развлекательный проект "Кулички на Рамблере" (http://kulichki.rambler.ru). Проект содержит много интересной и развлекательной информации в различных областях (компьютеры, музыка, спорт, юмор,...). Включает в себя более 20 тыс. страниц, имеет более 500 тыс. хитов в день;
· В мае 2001 года Rambler объявил об открытии нового проекта - Руметрика, посвященный исследованию развития русскоязычного сектора Интернета. Создатели проекта несколько раз в месяц публикуют данные об объеме Рунета, распределении сайтов по тематическим группам, динамике пользовательской активности, а также различные аналитические материалы, оценки социологов, аналитиков и экспертов в различных областях.
Яndex начал работу в сентябре 1997 года. Выполняет поиск по русскоязычной части Интернет (Рунет) с учетом русской морфологии. Поисковой машиной автоматически сканируются домены: su, ru, am, az, by, ge, kg, kz, md, ua, uz.
Яndex ежедневно просматривает сотни тысяч Web-страниц в поисках изменений или новых ссылок. В настоящее время Яndex содержит сведения о более чем 155 тысячах серверов. База данных машины содержит информацию о 23 млн. документах общим объемом 257 МГб. В поисковую машину Яndex вносятся только русскоязычные сайты. Для увеличения скорости поиска информации Яndex предоставляет возможность поиска по 17 категориям: культура/искусство; наука/образование; деловой мир; предприятия; СМИ; домашний очаг; интернет; государство; вокруг света; работа и заработок; торговля; компьютеры; отдых; спорт; справки; юмор; непознанное. Поисковая машина предоставляет разнообразные сервисы, которые позволяют пользователю делать персональные настройки (создавать свой сайт, свой почтовый ящик и т.д. и т.п.). Чтобы получить возможность работы с персональными настройками, необходимо зарегистрироваться. Яndex не требует от пользователя знания специальных команд для поиска. Достаточно набрать вопрос (например: "где продать зерно пшеница"). Независимо от того, в какой форме употребляется слово в запросе, поиск учитывает все его формы по правилам русского языка. После того, как задан запрос, Яndex выведет список ссылок на документы, наиболее точно ему соответствующие. Яndex обладает развитым языком запросов, позволяющим осуществлять "тонкий" поиск. Для того чтобы воспользоваться широким спектром возможностей, необходимо использовать страницу "расширенный поиск". Яndex предлагает пользователям новую услугу - почтовую подписку на поисковый запрос. Эта услуга позволяет узнать, когда в Сети появляется новая информация на интересующую вас тему? Еще одна услуга Яndex: поиск в категории. Поиск в категории - по сути, комбинация поисковой системы и каталога. В обычном каталоге поиск в разделе идет по описаниям ресурсов, составленными авторами. Яndex предлагает поиск по содержанию страниц, относящихся к тому или иному разделу. При поиске для каждого найденного документа Яndex вычисляет величину релевантности содержания этого документа поисковому запросу. Список найденных документов перед выдачей пользователю сортируется по этой величине в порядке убывания. Релевантность документа зависит от ряда факторов, в том числе от частотных характеристик искомых слов, веса слова или выражения, близости искомых слов в тексте документа друг к другу и т.д.
Google работает с 1997 года и сейчас считается крупнейшей международной поисковой системой в Интернете. Существует и русская версия. По популярности, влиятельности и техническим возможностям ему нет равных. По заявлению Google в русской версии на данный момент (апрель 2003 года) их база данных насчитывает 3 083 324 652 проиндексированных страниц.
Поисковый “паук” Google ведет поиск не только в WWW-сети, но и в архивах групп новостей Usenet, существующим с 1981 года, то есть с тех пор, когда Web еще не было на свете. Сейчас эти архивы содержат 700 млн. сообщений, рассортированных по 35 тысячам категорий. Google также может найти по запросу изображения, файлы форматов Microsoft Office и PDF расположенных в сети Интернет.
Google использует базу данных и алгоритмы поиска международной поисковой сети Yahoo!, причем его основное отличие от других поисковых систем заключается в том, что Google более строго относится к соответствию выдаваемых ссылок на страницы со словами в форме запроса. Поисковая система имеет возможность вести поиск web-страниц на 26 различных языках.
Для облегчения процесса поиска в поисковой системе используется так называемый "интеллектуальный агент", конкретизирующий область поиска и присваивающий сайтам рейтинг по критерию "важность". Этот метод получил название PageRank. PageRank — уникальный метод, так как был создан специально для поисковый системы Google. Суть данной технологии такова: когда учтены все факторы обуславливающие релевантность и частоту цитируемости, Google использует PageRank, чтобы откорректировать результаты так, что более “важные” сайты поднимутся соответственно вверх на странице результатов поиска пользователя. То есть, порядок ранжирования в Google работает следующим образом:
1. Найти все страницы, соответствующие ключевым словам поиска.
2. Отранжировать соответственно “страничным факторам”, таким, как ключевые слова.
3. Учесть текст ссылок на страницы.
4. Откорректировать результаты данными PageRank.
PageRank, используемая в Google, в основном основана на link popularity (“популярность ссылки”). Т.е. при вычислении релевантности страницы наибольший вклад имеет количество и качество ссылок на страницы с других страниц. Сейчас link popularity используется во всех основных поисковых системах мира (в той или иной степени). Кстати, в некоторых русскоязычных поисковых системах также используется этот параметр, например, в Яndex, этот параметр называется индекс цитирования.
Очень удобной функцией Google является "cache". Благодаря этой функцией пользователь может просмотреть проиндексированную страницу даже если эта страница удалена или сервер, на котором расположена страница недоступен. Вы также можете использовать эту функцию для исследования ваших конкурентов, это также помогает лучше понять принцип индексирования страницы поисковым пауком (роботом).
С помощью Google можно найти страницы, которые не содержатся в его базе данных. Это возможно потому, что поисковый паук индексирует текст ссылок со страниц. Данная функция также обуславливает растущую популярность данной поисковой системы.
По сообщению КомпьюЛенты от 11 апреля 2002 года “Самым популярным поисковиком февраля стал Yahoo!, Google на третьем месте.Первое место в списке занял портал Yahoo!, поисковыми функциями которого воспользовалось 32 млн. человек. На втором месте оказался еще один портал MSN, который посетило 32 млн. "искателей". И, наконец, на третьем месте находится Google - самая популярная из поисковых систем, не отягощенных портальными "наворотами"”.
Поисковая система Апорт, являющаяся в настоящее время частью информационно-развлекательного портала РОЛ (http://www.rol.ru), относится к числу ведущих поисковых систем российского Интернета. Как и любая другая поисковая система, она имеет свои особенности, как чисто технические, интересные в первую очередь профессионалам в области информационного поиска, так и те, которые существенны для обычных пользователей.
Одним из существенных преимуществ Апорта является англо-русский и русско-английский on-line перевод запросов и поисков результата, благодаря чему можно исследовать "русский интернет" не зная ни слова по-русски. Более того, благодаря ряду уникальных особенностей системы, можно проводить поиск, используя контекстные выражения даже для предложений.
Поисковая система Апорт (www.aport.ru) по серверам России и странам СНГ содержит миллионы документов с более чем 15000 сайтов. Система имеет развитый язык запросов и гибкую форму вывода результатов. Основные свойства поисковой системы Апорт:
· перевод запроса и результатов поиска с русского на английский и наоборот
· автоматическая проверка орфографических ошибок запроса
· более информативный вывод результатов поиска для найденных сайтов (выводится не только первое предложение найденного документа)
· возможность поиска в любой грамматической форме (что особенно важно для русского языка)
· мощный язык расширенных запросов для профессиональных пользователей
· поддержка пяти основных кодовых страниц (разных операционных систем) для русского языка
· технология поиска с использованием ограничений по URL (адресу) и дате документов
· поиск ведется не только по тексту, но и по заголовкам, комментариям и подписям к картинкам и т.д.
· сохранение параметров поиска и определенного числа предыдущих запросов пользователя
· объединение копий документа, находящихся на разных серверах
Технология поиска с использованием поисковых машин
Рассматривают следующие основные этапы, которые так или иначе присутствуют при поиске информации с использованием поисковых машин.
Определение географических регионов поиска
Поскольку проведение информационного поиска преследует практические цели - маркетинговые, производственные, сугубо утилитарные и тому подобные, - практическая ценность информационного ресурса может зависеть и от географического расположения соответствующего источника.
Составление тезауруса
Для эффективного использования поисковых серверов необходим список ключевых слов, организованный с учетом семантических отношений между ними, т.е. тезаурус. При составлении тезауруса необходимо предусмотреть обработку синонимов, омонимов и морфологических вариаций ключевых слов.
Использование законов Зипфа
Число, показывающее сколько раз встречается слово в тексте, называется частотой вхождения слова. Если расположить частоты по мере убывания и пронумеровать, то порядковый номер частоты называется рангом частоты. Вероятность обнаружения слова в тексте = частота вхождения слова / число слов в тексте. Зипф нашел, что если умножить вероятность обнаружения слова в тексте на ранг частоты, то получившаяся величина приблизительно постоянна для всех текстов на одном языке: С = (частота вхождения слов X ранг частоты) / число слов
Это значит, что график зависимости ранга от частоты - равносторонняя гипербола. Зипф также установил, что зависимость количества слов с данной частотой от частоты - также гипербола и постоянная для всех текстов в пределах одного языка.
Что можно извлечь из этих законов? Исследования вышеуказанных зависимостей для различных текстов показали, что наиболее значимые слова текста лежат в средней части диаграммы, так как слова с максимальной частотой как правило являются предлогами, частицами, местоимениями, в английском языке - артиклями (так называемые "стоп-слова"), а редко встречающиеся слова в большинстве случаев не имеют решающего значения. Основываясь на этой закономерности, можно предложить следующую методику.
Составление списка ключевых слов
Правильный набор ключевых слов имеет определяющее значение для оптимального поиска информации. К примеру, задав поисковой машине в качестве ключевого слова "МАРП", мы получим список документов, в которых встречается эта аббревиатура (Московское Агентство по Развитию Предпринимательства). Но если нас интересуют документы по более широкой теме, например: развитие предпринимательства, и мы сформируем простой запрос из этих двух слов, то поисковая машина выдаст нам список из сотен тысяч наименований, ориентироваться в котором будет весьма непросто.
Поэтому для составления оптимального набора ключевых слов используют процедуру, основанную на применении законов Зипфа, которая заключается в следующем: берут любой текст-источник, близкий к искомой теме, т.е. "образец", и анализируют его, выделяя значимые слова. В качестве текста-источника может служить книга, статья, Web-страница, любой другой документ. Анализ текста производится таким образом:
- Удаление из текста стоп-слов.
- Вычисление частоты вхождения каждого слова и составление списка, в котором слова расположены в порядке убывания их частоты.
- Выбор диапазона частот, лежащего в середине списка, и отбор из этого диапазона слов, наиболее полно соответствующих смыслу текста.
- Составление запроса к поисковой машине в форме перечисления отобранных таким образом ключевых слов, связанных логическим оператором ИЛИ (OR). Запрос в таком виде позволяет обнаружить тексты, в которых встречается хотя бы одно из перечисленных слов.
Число документов, полученных в результате поиска по этому запросу, может быть огромно. Однако, благодаря ранжированию документов (расположению их в порядке убывания частоты вхождения слов запроса в документ), применяемому в большинстве поисковых машин, на первых страницах списка практически все документы окажутся релевантными, причем документ-источник может находиться далеко от начала.
Более адекватной представляется структура тезауруса в виде так называемых семантических срезов, где для каждого основного термина отдельно строится таблица сопутствующих слов и слов шумовых (которые не должны встречаться в источнике), - некоторые поисковые машины (AltaVista) позволяют это использовать. Таким образом, вместо единой иерархической структуры терминов мы получаем пакет таблиц, которые могут расширяться и модифицироваться отдельно.
Отбор поисковых машин
Устанавливается последовательность использования поисковых машин в соответствии с убыванием ожидаемой эффективности поиска с применением каждой машины. Всего известно около 180 поисковых серверов, различающихся по регионам охвата, принципам проведения поиска (а следовательно, по входному языку и характеру воспринимаемых запросов), объему индексной базы, скорости обновления информации, способности искать "нестандартную" информацию и тому подобное. Основными критериями выбора поисковых серверов являются объем индексной базы сервера и степень развитости самой поисковой машины, то есть уровень сложности воспринимаемых ею запросов.
Составление и выполнение запросов к поисковым машинам
Это наиболее сложный и трудоемкий этап, связанный с обработкой большого количества информации (в основном шумовой). На основе тезауруса формируются запросы к выбранным поисковым серверам, после чего возможно уточнение запроса с целью отсечения очевидно нерелевантной информации. Затем производится отбор ресурсов, начиная с наиболее интересных, с точки зрения целей поиска. Данные с ресурсов, признанных релевантными, собираются для последующего анализа.
Формирование запросов
Как формат, так и семантика запросов варьируются в зависимости от применяемой поисковой машины и конкретной предметной области. Запросы составляются так, чтобы область поиска была максимально конкретизирована и сужена. Предпочтение отдается использованию нескольких узких запросов по сравнению с одним расширенным. В общем случае для каждого основного понятия из тезауруса готовится отдельный пакет запросов. Так же производится пробная реализация запросов - как для уточнения и пополнения тезауруса, так и с целью отсечения шумовой информации.
Результат запроса (список ссылок) обрабатывается в два этапа. На первом этапе производится отсечение очевидно нерелевантных источников, попавших в выборку в силу несовершенства поисковой машины или недостаточной "интеллектуальности" запроса. Параллельно проводится семантический анализ, имеющий целью уточнение тезауруса для модификации последующих запросов. Дальнейшая обработка производится путем последовательного обращения на каждый из найденных ресурсов и анализа находящейся там информации.
Т.о., поиск с применением поисковых машин является самым распространенным и эффективным методом поиска чего-то конкретного в сети Интернет. Хотя остальные методы ничем не хуже, только они применяются очень редко и только в том случае, если при помощи поисковой машины ничего нельзя найти.
Заключение
Поиск информации в сети Интернет - это последовательность действий, от определения предмета поиска, до получения ответа на имеющиеся вопросы с использованием всех поисковых сервисов, которые предоставляет сегодня Интернет.
Основные инструменты поиска информации в Интернет:
• электронная почта и почтовые роботы;
• глобальная система телеконференций Usenet, региональные и специализированные телеконференции;
• рассылки;
• он-лайновые средства коммуникации пользователей;
• системы поиска людей и организаций;
• система файловых архивов FTP, системы поиска в FTP-архивах глобального и регионального охвата;
• гипертекстовая информационная система World Wide Web (WWW);
• сетевые базы данных (в среде WWW);
• каталоги ресурсов - глобальные, локальные, специализированные (в среде WWW);
• глобальные
• локальные
• региональные
• специализированные
• широкоспециализированные
• узкоспециализированные
• поисковые машины, или автоматические индексы - глобальные, локальные, региональные, специализированные (в среде WWW);
• баннерные системы (в среде WWW);
• активные информационные каналы (в среде WWW).
Но при низкой себестоимости полученной информации, следует также учитывать, что трудоемкие поисковые работы, связанные с масштабным сбором информации из Сети, нуждаются в планировании. Ошибочная логика построения запроса, неоптимизированная последовательность применения инструментов, попытка форсировать поиск - все это не просто затягивает получение результата, но может поставить под вопрос смысл всей поисковой кампании.
Date: 2016-05-25; view: 837; Нарушение авторских прав; Помощь в написании работы --> СЮДА... |